
- 1 WebFlux与SpringMVC 对比
- 1.1 前言
- 1.2 问题引入
- 1.3 WebFlux核心:异步非阻塞与响应式流
- 1.3.1 Reactor 与 Mono/Flux
- 1.3.2 背压(Backpressure):响应式流的精髓
- 1.4 两种编程模型:注解与函数式
- 1.4.1 注解模型
- 1.4.2 函数式模型
- 1.5 WebFlux如何运转
- 1.6 性能与选择
1 WebFlux与SpringMVC 对比
1.1 前言
从早期的 Struts 到统治多年的 Spring MVC,见证了整个 Java Web 开发框架的演进。所以今天深入聊聊 Spring 5 带来的这个“新成员”—— WebFlux。
有些小伙伴在工作中可能听说过它,知道它性能高、异步非阻塞,但真要上手,心里却直打鼓:这和 Spring MVC 到底有啥不同?项目真的需要它吗?
1.2 问题引入
要理解 WebFlux,必须先看清楚它要解决的问题。我们最熟悉的 Spring MVC,其核心是建立在 Servlet API 之上的同步阻塞模型。
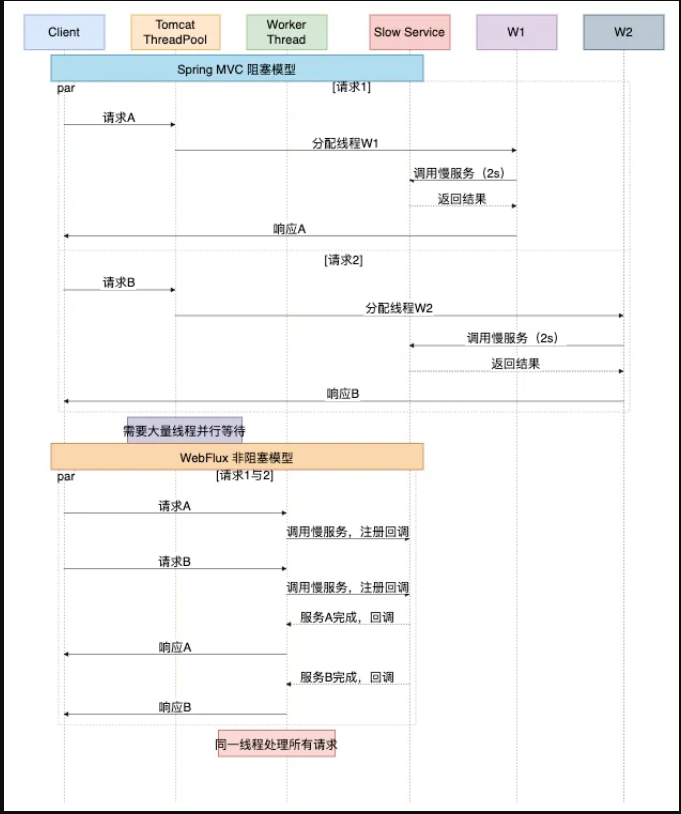
想象这样一个场景:控制器里有一个方法,需要调用一个外部接口获取数据,这个接口响应很慢,可能需要 2 秒。
// 传统的Spring MVC控制器
@RestController
public class TraditionalController {@GetMapping("/slow")public String slowApi() {// 模拟一个耗时2秒的远程调用String data = someSlowRemoteService.call(); // 线程在这里被阻塞2秒!return "Data: " + data;}
}
问题出在哪里? 当请求到达服务器时,Servlet 容器(如 Tomcat)会从它的线程池中分配一个工作线程来处理这个请求。
在这个线程执行 someSlowRemoteService.call() 的整整 2 秒钟里,这个线程什么也做不了,只能空转、等待。
它无法去处理其他已经到达的请求。如果同一时间有 1000 个这样的并发请求,Tomcat 就需要准备至少 1000 个线程来应对。
每个线程都消耗内存(约 1MB 栈内存)和 CPU 调度资源。当线程数超过物理核心承载能力,大量的时间将浪费在线程上下文切换上,导致响应变慢,最终可能因资源耗尽而崩溃。
这就是 一个请求,一个线程 的阻塞模型在 I/O 密集型场景下的天然瓶颈。我们投入了大量资源(线程),仅仅是为了“等待”,而不是“计算”。
有些小伙伴在工作中,可能已经通过增大线程池、服务拆分等方式缓解了这个问题,但这本质上是“用资源换吞吐量”,并非最优解。
1.3 WebFlux核心:异步非阻塞与响应式流
WebFlux 的哲学截然不同。它源于响应式编程范式,核心目标是:用少量、固定的线程,处理大量并发请求。
如何做到?答案是 事件驱动 和 异步非阻塞 I/O。它不再让线程傻等,而是告诉系统:“我去做点别的,等数据准备好了,你再回调通知我”。
1.3.1 Reactor 与 Mono/Flux
这是理解 WebFlux 的第一道坎。WebFlux 构建在 Project Reactor 响应式库之上,引入了两个核心类型:
Mono: 代表0或1个结果的异步序列。可以把它想象成一个未来可能到来的单个数据包的承诺。Flux: 代表0到N个结果的异步序列。可以把它想象成一个数据流,数据项一个接一个地异步发布出来。
看一个代码对比,立刻就能明白:
// Spring MVC: 直接返回对象
@GetMapping("/user/{id}")
public User getUser(@PathVariable String id) {return userService.findById(id); // 阻塞式,线程等待数据库返回
}
// WebFlux: 返回Mono,代表一个异步承诺
@GetMapping("/user/{id}")
public Mono<User> getUser(@PathVariable String id) {return userService.findByIdReactive(id); // 非阻塞,立即返回Mono,数据稍后填充
}
在 WebFlux 版本中,getUser 方法几乎瞬间返回,返回的是一个 Mono<User> 的空壳。当底层非阻塞数据库驱动真正获取到数据后,会自动将数据填充到这个 Mono 里,并最终发送给客户端。在这个过程中,线程没有被挂起,它可以立刻去处理其他请求。
我们可以通过下面这张图,直观感受两种模型处理多个慢请求时的巨大差异:
1.3.2 背压(Backpressure):响应式流的精髓
这或许是 WebFlux 最精妙也最容易被忽视的特性。在传统的拉取模型中,消费者控制节奏。而在响应式流中,数据由生产者主动推送,如果生产者太快,消费者来不及处理怎么办?
背压机制 允许消费者(如下游服务)主动告知生产者(如上游数据源)“我最多还能处理多少”,生产者据此调整推送速率,避免消费者被压垮。这为构建健壮的流处理系统提供了基础保障,是 Reactive Streams 规范的核心。
1.4 两种编程模型:注解与函数式
WebFlux 提供了两种编程模型:
1.4.1 注解模型
这种方式和 Spring MVC 几乎一模一样,学习成本极低。主要区别仅在于返回值和部分参数类型。
@RestController
@RequestMapping("/orders")
publicclass ReactiveOrderController {@Autowiredprivate ReactiveOrderService orderService;// 返回Flux,代表多个订单的流@GetMappingpublic Flux<Order> getAllOrders() {return orderService.findAll();}// 返回Mono@GetMapping("/{id}")public Mono<Order> getOrderById(@PathVariable String id) {return orderService.findById(id);}// 参数也可以是Mono@PostMappingpublic Mono<Void> createOrder(@RequestBody Mono<Order> orderMono) {return orderMono.flatMap(orderService::save).then();}
}
可以看到,除了 Flux 和 Mono 这些类型,其他注解 @RestController、@GetMapping 都是 SpringMVC 中的。这对于现有项目进行部分重构或新项目启动非常友好。
1.4.2 函数式模型
这是 WebFlux 的另一面,更像是在用 Java 8 的 Lambda 表达式和函数式接口来定义路由和处理逻辑,它不依赖于注解。
@Configuration
publicclass RouterFunctionConfig {@Beanpublic RouterFunction<ServerResponse> routeOrder(ReactiveOrderHandler orderHandler) {return RouterFunctions.route().GET("/fn/orders", orderHandler::getAll).GET("/fn/orders/{id}", orderHandler::getById).POST("/fn/orders", orderHandler::create).build();}
}
@Component
publicclass ReactiveOrderHandler {public Mono<ServerResponse> getAll(ServerRequest request) {Flux<Order> orders = ... // 获取订单流return ServerResponse.ok().contentType(MediaType.APPLICATION_JSON).body(orders, Order.class);}// ... 其他处理方法
}
函数式模型将所有路由和处理器暴露为明确的 Bean,声明清晰,易于测试,且运行时开销更小,特别适合微服务场景中功能明确、结构简洁的端点。
1.5 WebFlux如何运转
理解了表面用法,我们以注解模型为例,深入一层,看看一个请求在 WebFlux 内部是如何流转的。
点击此处了解SpringMVC请求过程
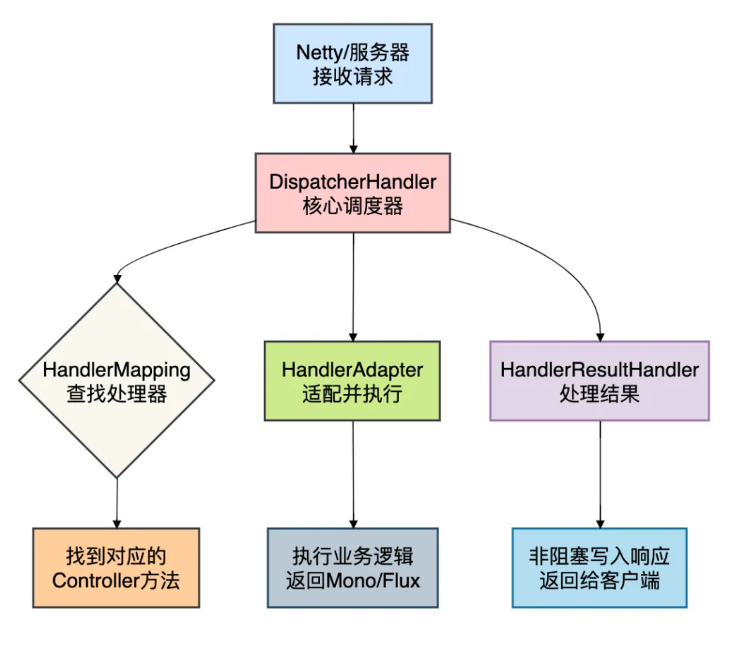
WebFlux 的核心调度器不再是 Servlet 容器的线程池,而是一个名为 DispatcherHandler 的组件,它扮演着类似 Spring MVC 中 DispatcherServlet 的角色。
请求接收: 以Netty为例,I/O线程接收到HTTP请求,将其封装为ServerWebExchange(一个非阻塞的请求-响应交换对象)。寻找处理器:DispatcherHandler调用一组HandlerMapping,根据请求路径等信息,找到对应的控制器方法(就是一个Handler)。执行处理:DispatcherHandler再通过HandlerAdapter去实际执行这个控制器方法。我们的方法返回一个Mono或Flux。处理结果:HandlerResultHandler负责处理这个反应式返回类型,将流中的数据序列化(如转为JSON),并通过非阻塞 I/O 写回响应。
整个过程中,所有环节都是非阻塞的。线程只在有 CPU 计算任务时才忙碌,一旦遇到 I/O 等待,就会去处理其他任务,从而实现极高的资源利用率。
下面是 WebFlux 核心组件协同处理请求的架构图:
1.6 性能与选择
WebFlux 和 Spring MVC 不是替代关系,而是互补关系,它们共同扩展了 Spring 生态的能力边界。
性能真相:
WebFlux的优势在于高并发、低延迟的I/O密集型场景。当你的应用有大量外部调用(数据库、微服务、API)、慢连接或长轮询(如聊天)时,WebFlux 能用更少的资源提供更稳定的吞吐量。WebFlux不会让CPU密集型计算更快。如果业务逻辑本身就是复杂的计算,没有太多I/O等待,那么切换到WebFlux可能看不到收益,甚至因为响应式链的开销而略有下降。- 资源利用率是核心优势。
WebFlux通过减少线程数量,降低了内存消耗和上下文切换开销,使系统在压力下的表现更加可预测和稳定。
代价与挑战:
编程范式转换: 从“指令式”思维切换到“声明式”、“函数式”的反应式思维是一大挑战。调试链式调用的Mono/Flux也比调试普通代码更困难。生态兼容性: 整个技术栈都需要支持非阻塞。这意味着常用的阻塞式数据库驱动(如 JDBC)、Redis 客户端等可能无法直接使用,必须寻找其反应式版本(如 R2DBC、Lettuce)。这是一条“全栈反应式”的不归路。学习曲线: 团队需要时间学习 Reactor 丰富的操作符(map, flatMap, zip 等)和错误处理机制。
如何选择?
可以遵循以下的决策流程,来判断你的项目是否真的需要 WebFlux:
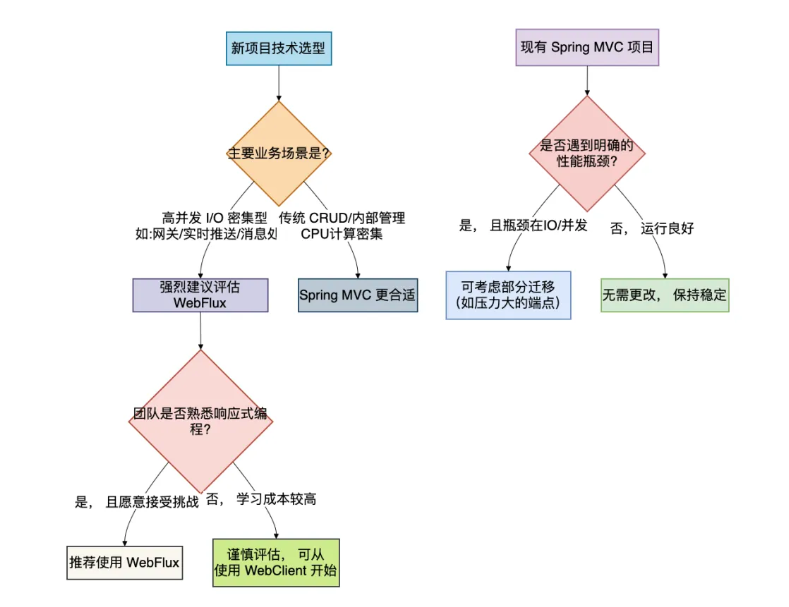
- 对于新项目: 如果是微服务网关(
Spring Cloud Gateway就是基于 WebFlux)、实时监控、消息推送等场景,WebFlux 是绝佳选择。 - 对于现有项目: 不要轻易重构, 如果 Spring MVC 运行良好,重构的成本和风险极高。