
Adversarial Style Augmentation via Large Language Model for Robust Fake News Detection(WWW 2025)
通过大型语言模型进行对抗风格增强以实现鲁棒的假新闻检测
作者:Sungwon Park, Sungwon Han, Xing Xie, Jae-Gil Lee, Meeyoung Cha
代码:https://github.com/deu30303/AdStyle
论文地址:https://arxiv.org/abs/2406.11260
1. 研究动机与研究问题
研究动机 (Motivation)
- 现实挑战:假新闻传播危害严重。虽然现有许多检测方法利用情感、主题、传播网络等特征取得了不错效果,但这些特征容易被风格转换攻击Style-conversion Attacks所操纵。
- LLM 带来的新威胁:随着大语言模型(LLM)的兴起,攻击者可以轻易通过 Prompt(如“把这段话改成《纽约时报》的风格”)重写假新闻。这种重写保留了原始内容,但改变了文本的句式结构和风格特征,使得现有的检测器(甚至专门针对 AI 生成内容的检测器)难以分辨。
- 现有防御的不足:
- 现有的防御方法(如 SheepDog)通常依赖预定义的风格转换 Prompt(如“改为中立风格”)。
- 这种预定义方式可能无法覆盖检测器的所有盲点,且无法适应检测器在训练过程中的动态变化。
- 需要一种能自动发现对当前检测器最具攻击性的风格,并据此进行针对性增强的方法。
研究问题 (Research Questions)
- 如何利用 LLM 自动生成多样化且连贯的风格转换 Prompt,以模拟各种潜在的风格攻击?
- 如何筛选出对当前检测器最具攻击性(Adversarialness)且保持语义一致(Coherency)的 Prompt?
- 利用这些生成的对抗性风格样本进行数据增强(Adversarial Augmentation),能否显著提升假新闻检测器在面对未知风格攻击时的鲁棒性?
2. Method
论文提出的核心方法名为 AdStyle (Adversarial Style Augmentation)。这是一个迭代式的对抗训练框架。
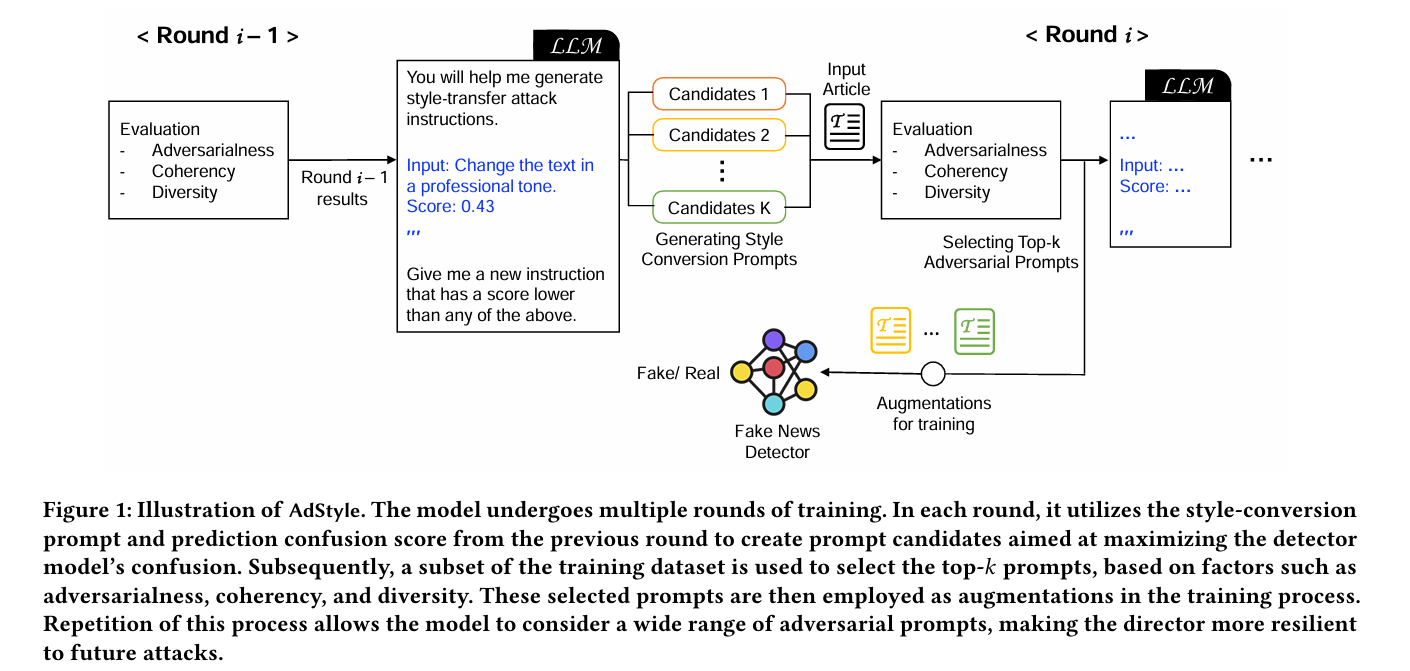
2.1 概览 (Overview)
- 目标:训练一个鲁棒的假新闻检测器 f,使其在面对文本风格扰动(如语序、格式变化)时仍能保持预测准确,同时不改变句子原意。
- 流程:多轮次(Round-based)训练。
- 利用 LLM 生成候选的风格转换 Prompt。
- 筛选出最能混淆当前检测器的 Top-k 个 Prompt。
- 利用这些 Prompt 对训练数据进行增强(重写)。
- 使用增强后的数据重新训练检测器。
2.2 对抗性风格转换 Prompt 生成 (Adversarial Style-Conversion Prompts)
- 核心思想:不使用预定义的固定 Prompt,而是利用 LLM 的推理能力自动搜索能最大化检测器混淆度的 Prompt。这类似于计算机视觉中的对抗攻击,但在离散文本空间中通过 Prompt 实现。
![image]()
- Prompt 设计:
- 问题描述组件:告诉 LLM 任务目标是“最小化假新闻检测器的性能”。
- 分数轨迹组件 (Score Trajectory):利用上下文学习(In-Context Learning)。
- 输入:上几轮使用的
[Prompt, Score]对+这轮输入。 Score是预测混淆分数 (Prediction Confusion Score, \(s_c\)):
![image]()
分数越低(越接近0),说明检测器的预测越接近随机猜测(AUC=0.5),即攻击越成功。- LLM 根据这些历史数据,推断出更能让检测器失效的新 Prompt。
- 输入:上几轮使用的

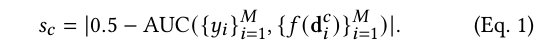
2.3 选择 Top-k 对抗性 Prompt (Selecting Top-k Adversarial Prompts)
生成大量 Prompt 后,并非所有都适用。需要筛选出同时满足 对抗性、一致性 和 多样性 的 Prompt。
-
嵌入向量差异计算:
- 计算原文本集合 \(B\) 的平均 BERT 嵌入 \(z\)。
- 计算经 Prompt \(c\) 转换后的文本集合 \(B^c\) 的平均嵌入 \(z'\)。
- 变化向量 \(z_c = z' - z\),代表该 Prompt 导致的风格偏移方向。
-
指标定义:
- 对抗性评分 (Adversarialness Scale, \(s_{adv}^c\)):衡量攻击效果。
![image]()
(AUC 越接近 0.5,得分越高,范围 0.1~1) - 一致性评分 (Coherency Scale, \(s_{coh}^c\)):衡量语义保留程度。利用 LLM 判断原句和改写句是否意图一致,计算相同意思的文本对占百分比是多少,该值被缩放到 0.1 到 1 之间
- 对抗性评分 (Adversarialness Scale, \(s_{adv}^c\)):衡量攻击效果。
-
加权与选择:
- 对变化向量进行加权:\(\hat{z}_c = z_c \times s_{adv}^c \times s_{coh}^c\)。
- 多样性选择:使用 k-means++ 初始化算法在 \(\hat{z}_c\) 空间中选择 \(k\) 个中心点对应的 Prompt。这确保了选出的 Prompt 既强力、语义保留好,又在风格空间上尽可能分散(多样)。
-
增强训练:
- 用选出的 \(k\) 个 Prompt 对整个训练集 \(D\) 进行重写,生成增强样本。
- 将增强样本与原样本混合,使用二元交叉熵损失训练检测器。
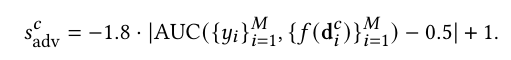
3. Experiment
3.1 性能评估 (Performance Evaluation)
数据集 (Datasets)
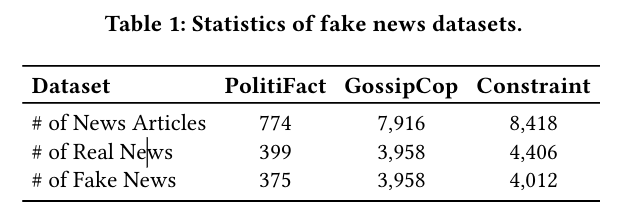
- PolitiFact (政治新闻)
- GossipCop (娱乐新闻)
- Constraint (COVID-19 社交媒体帖子)
- 划分:80% 训练,20% 测试。
攻击设置 (Attack Settings)
为了模拟真实的风格攻击,使用 LLM 将测试集重写为四种特定风格:
- CNN, The New York Times (权威、客观风格)
- The Sun, National Enquirer (小报、煽情风格)
- 工具:GPT-3.5-Turbo
Baselines (基线模型)
- Vanilla: 普通 BERT 检测器。
- UDA: 无监督数据增强(使用回译)。
- RADAR: 使用对抗生成的 Paraphraser 进行增强。
- ENDEF: 去除实体偏差的方法。
- SheepDog: SOTA 方法,使用预定义的风格 Prompt(如“中立”、“煽情”)进行增强。
实验结果 (Results)
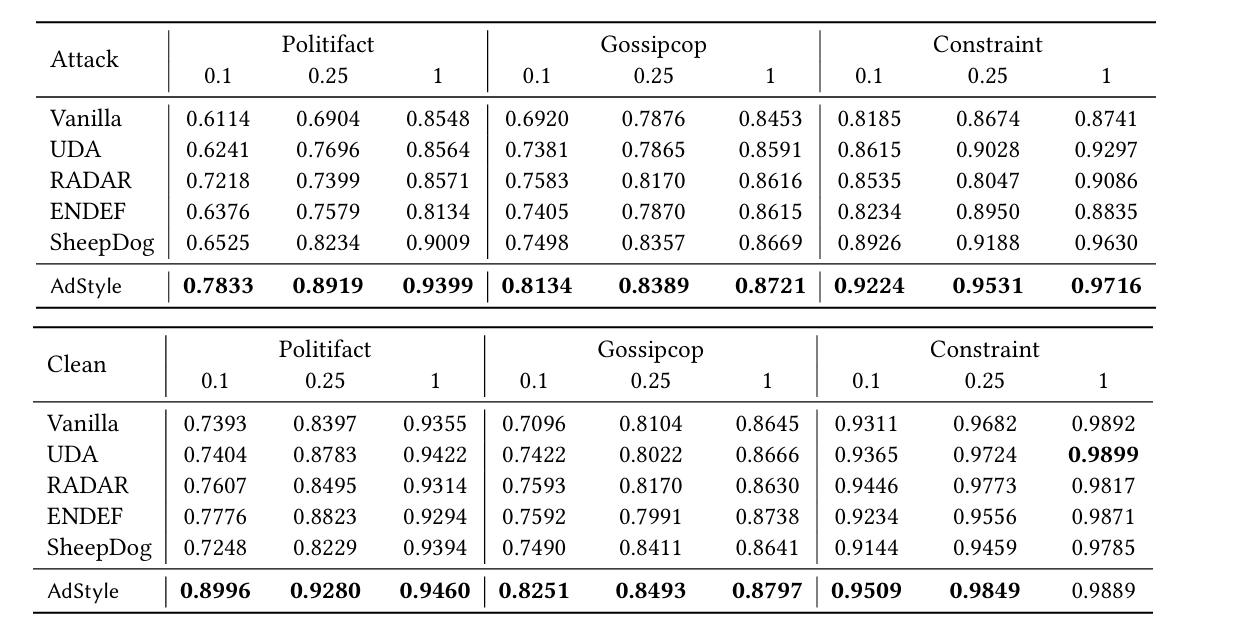
- 攻击场景 (Attack):在四种风格攻击下的平均 AUC。
- AdStyle 在所有数据集、所有数据比例(10%, 25%, 100%)下均显著优于所有基线。
- 例如在 PolitiFact (100%数据) 上,AdStyle AUC 达到 0.9399,而 SOTA SheepDog 仅为 0.9009。
- 干净场景 (Clean):无攻击的原始测试集。
- AdStyle 同样表现最佳,说明对抗性增强没有损害(甚至提升了)模型在原始分布上的泛化能力。
- 收敛性 (Figure 4):随着训练轮数增加(不断生成新的对抗 Prompt),模型性能稳步提升。
3.2 组件分析 (Component Analysis)
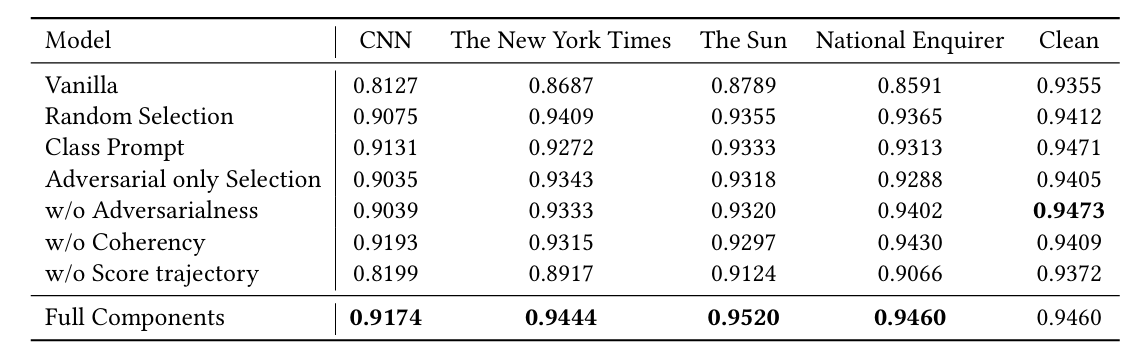
通过消融实验验证各模块贡献:
- w/o Score Trajectory(去掉分数轨迹):性能下降最严重。说明让 LLM 看到“什么样的 Prompt 攻击效果好”对于生成更强的攻击至关重要。
- Random Selection(随机选择 Prompt):性能下降。说明 k-means++ 的选择策略有效。
- w/o Adversarialness / Coherency:去掉任一评分指标都会导致性能下降,说明攻击强度和语义保留缺一不可。
3.3 性能分析 (Performance Analysis)
对其他攻击的鲁棒性
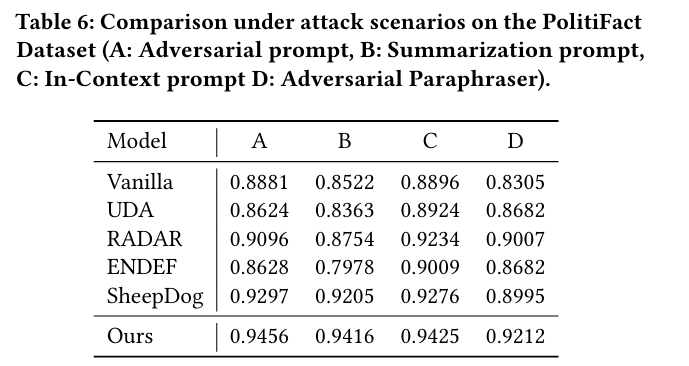
测试了 AdStyle 对未知攻击类型的防御能力:
- A: Adversarial prompt (让 LLM 尽力改写以绕过检测)。
- B: Summarization (摘要)。
- C: In-Context (模仿给定的真实新闻风格)。
- D: Adversarial Paraphraser (使用专门训练的改写模型)。
- 结果:AdStyle 在所有这些未见过的攻击场景下依然保持最高性能,证明其学到了通用的鲁棒特征,而非仅仅记住了某种风格。
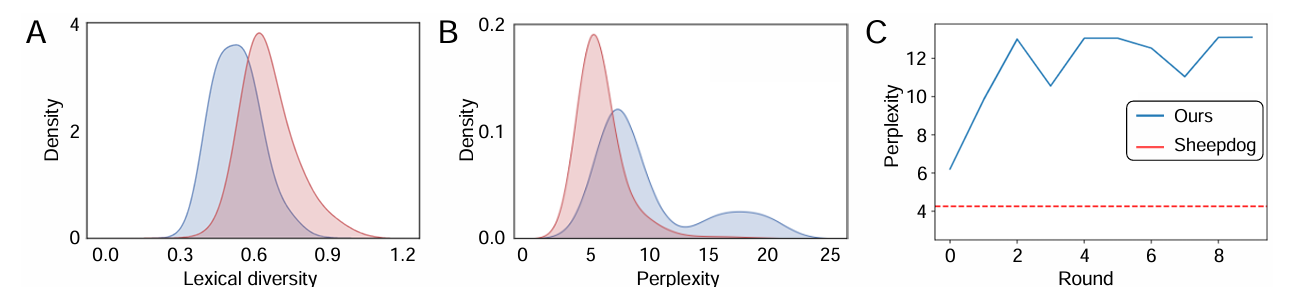
风格 Prompt 定性分析
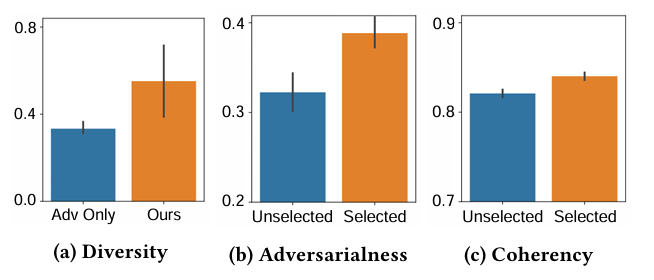
- 多样性 :AdStyle 选出的 Prompt 在嵌入空间分布更广。
![image]()
- 困惑度 :AdStyle 生成的样本具有更高的困惑度(Perplexity),意味着它生成的句子结构对检测器来说更陌生、更具挑战性,从而迫使检测器学习更本质的特征。
- Prompt 进化示例 :
![image]()
- Round 0: "nonsensical and absurdly exaggerated..." (比较常规)。
- Round 1: "...malevolent and apocalyptic tone... incorporating elements of surrealism..." (变得非常具体、复杂且具有创造性)。这证明了 LLM 在迭代中学会了更狠的攻击手段。

结论 (Conclusion)
- AdStyle 提出了一种利用 LLM 自动生成和筛选对抗性风格 Prompt的框架。
- 通过模拟进化的攻击(Prompt 越来越刁钻),训练出的检测器在面对各种已见和未见的风格转换攻击时都表现出了极强的鲁棒性。
- 该方法不仅是一种防御手段,其生成的 Prompt 也可以作为一种自动化的攻击测试工具。