)
离策略演员–评论家(Off-policy Actor–Critic)
On-policy 与 Off-policy
演员–评论家算法通常是on-policy(同策略)的:用于探索环境的动作必须由当前策略生成,否则评论者(Critic)提供的反馈(优势项)会在策略梯度中引入巨大的偏差。
这源自策略梯度定理:
其中 \(\rho^\pi\) 表示按照策略 \(\pi_\theta\) 可访问的状态分布。若采样的状态 \(s\) 并非来自此分布,则梯度估计将出现高偏差,导致策略次优。
On-policy 缺点:
样本复杂度高、探索效率低。如果智能体初始化于低回报区域,则策略更新极慢,可能长时间无法“命中”高回报区域。
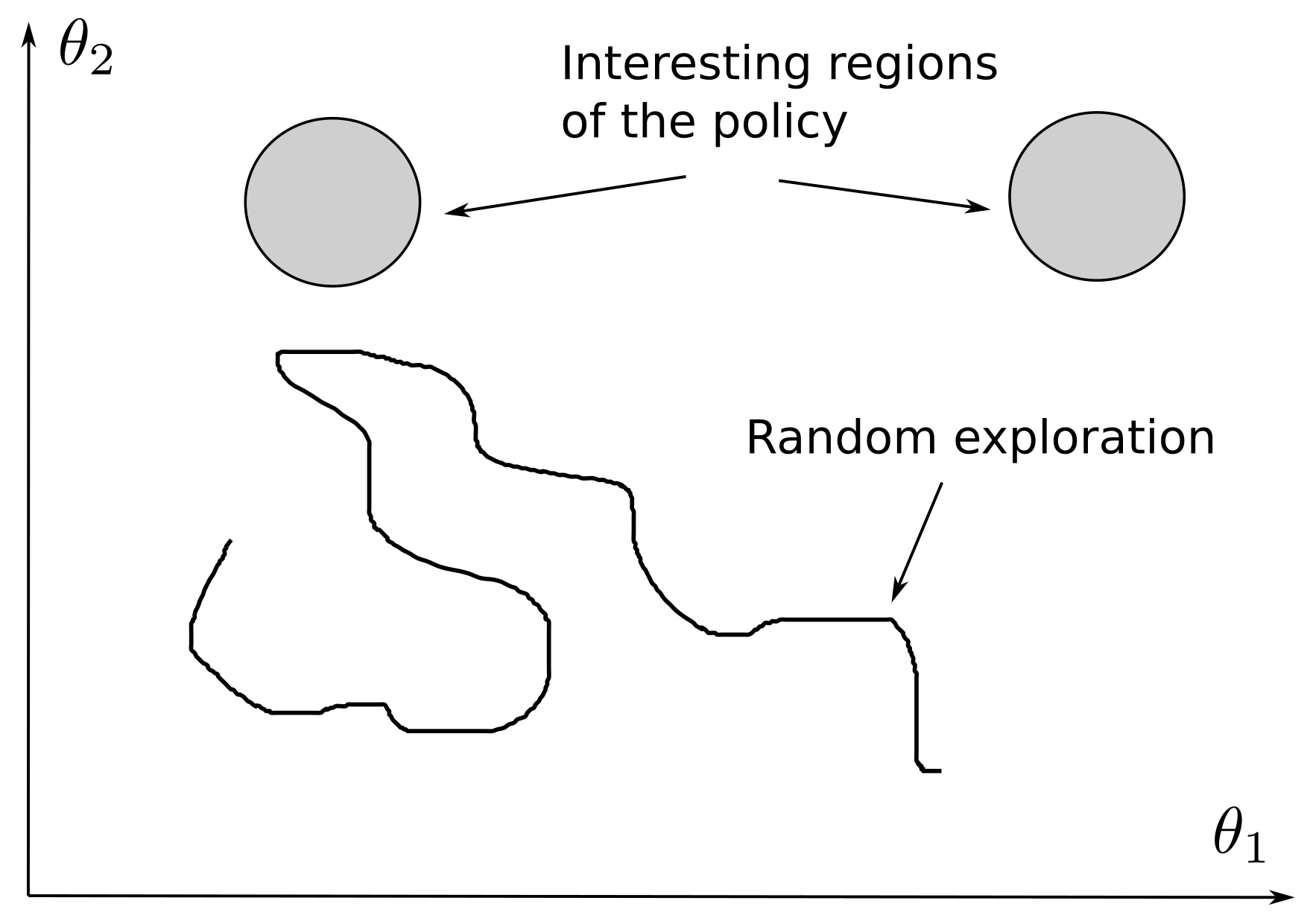
在高维状态或动作空间中,这一问题更严重,尤其是稀疏奖励情境。
此时可借助 off-policy 方法:使用行为策略(behavior policy) \(b(s,a)\) 探索环境,同时学习目标策略(target policy) \(\pi(s,a)\)。
若行为策略足够好,off-policy 学习能显著减少探索所需样本。
Off-policy 学习原理
Q-learning 是典型的 off-policy 算法,因为它在更新 Q 值时使用的是贪婪动作而非实际执行动作:
唯一要求是:目标策略能被行为策略“覆盖”:
即行为策略必须有非零概率执行目标策略可能选择的动作。
行为策略常见构造方式:
- 专家示范或启发式策略(模仿学习、机器人控制等)。
- 由目标策略派生:例如目标为贪婪策略,而行为策略采用 \(\epsilon\)-greedy 或 softmax 版本以保证探索。
后者确保了探索与收敛的平衡,因此 DQN 就是此种结构。
此外,off-policy 允许使用 经验回放(replay buffer),这是如 DQN 等算法的关键特性。
重要性采样(Importance Sampling)
off-policy 方法利用行为策略采样轨迹,但要估计目标策略的期望回报:
若用行为策略采样,得到:
两者分布不同。
重要性采样通过加权校正实现无偏估计:
其中比值:
称为重要性权重(importance weight)。
离策略蒙特卡罗策略搜索算法
- 使用行为策略 \(b\) 采样 \(m\) 条轨迹 \(\tau_i\);
- 对每条轨迹存储奖励 \(r_{t+1}\)、行为概率 \(b(s_t,a_t)\) 与目标策略概率 \(\pi_\theta(s_t,a_t)\);
- 估计目标期望:\[\hat{J}(\theta) = \frac{1}{m} \sum_{i=1}^m \!\left(\prod_{t=0}^T \frac{\pi_\theta(s_t,a_t)}{b(s_t,a_t)}\!\right)\!\left(\sum_{t=0}^T \gamma^t r_{t+1}\!\right) \]
- 更新 \(\theta\) 以最大化 \(\hat{J}(\theta)\)。
同理,策略梯度形式为:
基于因果性原则(causality),可化为逐步估计形式:
线性离策略演员–评论家(Off-PAC)
@Degris2012 提出首个离策略 Actor–Critic 方法。
其目标函数为:
策略梯度:
Off-PAC 能基于单步转移 \((s,a)\) 在线更新,结合重要性采样权重。
该算法支持资格迹(eligibility traces),但由于方差高,仅适用于线性函数逼近器。
Retrace 算法
Retrace [@Munos2016] 同时满足:
- 离策略学习(可复用旧样本,支持经验回放);
- 多步回报(multi-step returns)(平衡偏差与方差)。
在通用形式下,更新公式为:
不同的 \(c_s\) 取值对应不同算法:
| \(c_s\) 形式 | 算法 | 特点 |
|---|---|---|
| \(\lambda\) | \(Q(\lambda)\) | 对策略差异敏感,不安全 |
| \(\frac{\pi(s_s,a_s)}{b(s_s,a_s)}\) | 重要性采样 | 无偏但高方差 |
| \(\pi(s_s,a_s)\) | Tree-backup | 稳定但收敛慢 |
Retrace 的改进:
该方法结合重要性采样与资格迹,具有低方差、高稳定性和高效率。
Retrace 常用于 ACER 与 Reactor 等算法中。
自模仿学习(Self-Imitation Learning, SIL)
@Oh2018 提出在 A2C 等 on-policy 算法上加入回放缓冲区,强化对历史高回报样本的重用。
仅当实际回报高于当前状态值时,样本才用于更新:
其中 \((x)^+ = \max(0,x)\)。
SIL 实现了 on-policy 与 off-policy 的混合:既保持探索,又能高效利用已有经验。
实验表明,A2C+SIL 在 Atari 与 Mujoco 环境中均优于 A3C、PPO 等算法,尤其在稀疏奖励任务中表现突出。
Reactor 算法
Reactor(Retrace Actor) [@Gruslys2017] 结合 Retrace 与分布式架构,是 ACER 的分布式扩展。
主要特点:
- 使用 重要性采样的策略梯度;
- Retrace 校正的多步回报;
- 分布式 Q 值学习(distributional critic);
- 序列级优先回放(prioritized sequence replay)。
Actor–Critic 梯度:
为控制方差,引入截断参数:
得到 \(\beta\)-LOO(Leave-One-Out)梯度。
Critic 通过 Retrace(\(\lambda\)) 更新,结合分布式 Bellman 投影。
此外,Reactor 使用 LSTM 提供隐状态记忆,并行多个 actor-learner 在 CPU 上训练,仅需一天即可超越 DQN、A3C 与 ACER。