
【动手学深度学习PyTorch】softmax回归 - 实践
2025-10-19 15:38 tlnshuju 阅读(0) 评论(0) 收藏 举报softmax回归
一、分类困难
1. 介绍
假设每次输入是一个2×22\times22×2的灰度图像。每个图像属于类别“猫”“鸡”和“狗”中的一个。接下来,我们要选择如何表示标签。
选择就是最直接的想法y∈{1,2,3}y \in \{1, 2, 3\}y∈{1,2,3},其中整数分别代表{狗,猫,鸡}\{\text{狗}, \text{猫}, \text{鸡}\}{狗,猫,鸡}。这是在计算机上存储此类信息的有效方法。
2. 独热编码(one-hot encoding)
独热编码是一个向量,它的分量和类别一样多。
类别对应的分量设置为1,其他所有分量设置为0。
在上边的例子中,标签yyy将是一个三维向量,其中(1,0,0)(1, 0, 0)(1,0,0)对应于“猫”、(0,1,0)(0, 1, 0)(0,1,0)对应于“鸡”、(0,0,1)(0, 0, 1)(0,0,1)对应于“狗”:y∈{(1,0,0),(0,1,0),(0,0,1)}.y \in \{(1, 0, 0), (0, 1, 0), (0, 0, 1)\}.y∈{(1,0,0),(0,1,0),(0,0,1)}.
二、网络架构
为了估计所有可能类别的条件概率,我们得一个有多个输出的模型,每个类别对应一个输出。
为了解除线性模型的分类问题,我们必须和输出一样多的仿射函数(affine function)。每个输出对应于它自己的仿射函数。
在我们的例子中,由于我们有4个特征和3个可能的输出类别,我们将需要12个标量来表示权重(带下标的www),3个标量来表示偏置(带下标的bbb)。
下面我们为每个输入计算三个未规范化的预测(logit):o1o_1o1、o2o_2o2和o3o_3o3。
o1=x1w11+x2w12+x3w13+x4w14+b1,o2=x1w21+x2w22+x3w23+x4w24+b2,o3=x1w31+x2w32+x3w33+x4w34+b3. \begin{aligned} o_1 &= x_1 w_{11} + x_2 w_{12} + x_3 w_{13} + x_4 w_{14} + b_1,\\ o_2 &= x_1 w_{21} + x_2 w_{22} + x_3 w_{23} + x_4 w_{24} + b_2,\\ o_3 &= x_1 w_{31} + x_2 w_{32} + x_3 w_{33} + x_4 w_{34} + b_3. \end{aligned}o1o2o3=x1w11+x2w12+x3w13+x4w14+b1,=x1w21+x2w22+x3w23+x4w24+b2,=x1w31+x2w32+x3w33+x4w34+b3.
我们许可用神经网络图来描述这个计算过程。
与线性回归一样,softmax回归也是一个单层神经网络。由于计算每个输出o1o_1o1、o2o_2o2和o3o_3o3取决于所有输入x1x_1x1、x2x_2x2、x3x_3x3和x4x_4x4,因而softmax回归的输出层也是全连接层。
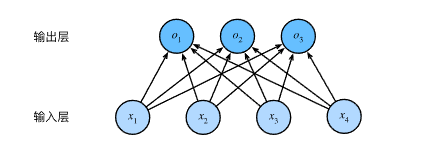
通过向量形式表达为o=Wx+b\mathbf{o} = \mathbf{W} \mathbf{x} + \mathbf{b}o=Wx+b,
三、全连接层的参数开销
全连接层是“完全”连接的,可能有很多可学习的参数。
具体来说,对于任何具有ddd个输入和qqq个输出的全连接层,参数开销为O(dq)\mathcal{O}(dq)O(dq),这个数字在实践中可能高得令人望而却步。然而将ddd个输入转换为qqq个输出的成本可以减少到O(dqn)\mathcal{O}(\frac{dq}{n})O(ndq),其中超参数nnn行由我们灵活指定,以在实际应用中平衡参数节约和模型有效性
四、softmax运算
softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持可导的性质。
- 为了做完这一目标,我们首先对每个未规范化的预测求幂,这样可以确保输出非负。
- 为了确保最终输出的概率值总和为1,我们再让每个求幂后的结果除以它们的总和。
- 如下式:y^=softmax(o)其中y^j=exp(oj)∑kexp(ok)\hat{\mathbf{y}} = \mathrm{softmax}(\mathbf{o})\quad \text{其中}\quad \hat{y}_j = \frac{\exp(o_j)}{\sum_k \exp(o_k)}y^=softmax(o)其中y^j=∑kexp(ok)exp(oj)
- 对于所有的jjj总有0≤y^j≤10 \leq \hat{y}_j \leq 10≤y^j≤1。因此,y^\hat{\mathbf{y}}y^可以视为一个正确的概率分布。
softmax运算不会改变未规范化的预测o\mathbf{o}o之间的大小次序,只会确定分配给每个类别的概率。因此,在预测过程中,我们仍然可以用下式来选择最有可能的类别。
argmaxjy^j=argmaxjoj. \operatorname*{argmax}_j \hat y_j = \operatorname*{argmax}_j o_j.jargmaxy^j=jargmaxoj.
尽管softmax是一个非线性函数,但softmax回归的输出仍然由输入特征的仿射变换决定。因此,softmax回归是一个线性模型(linear model)。
五、小批量样本的矢量化
为了提高计算效率并且充分利用GPU,我们通常会对小批量样本的材料执行矢量计算。
假设大家读取了一个批量的样本X\mathbf{X}X,其中特征维度(输入数量)为ddd,批量大小为nnn。此外,假设我们在输出中有qqq个类别。那么小批量样本的特征为X∈Rn×d\mathbf{X} \in \mathbb{R}^{n \times d}X∈Rn×d,权重为W∈Rd×q\mathbf{W} \in \mathbb{R}^{d \times q}W∈Rd×q,偏置为b∈R1×q\mathbf{b} \in \mathbb{R}^{1\times q}b∈R1×q。
softmax回归的矢量计算表达式为:
O=XW+b,Y^=softmax(O). \begin{aligned} \mathbf{O} &= \mathbf{X} \mathbf{W} + \mathbf{b}, \\ \hat{\mathbf{Y}} & = \mathrm{softmax}(\mathbf{O}). \end{aligned}OY^=XW+b,=softmax(O).
相对于一次处理一个样本,小批量样本的矢量化加快了X和W\mathbf{X}和\mathbf{W}X和W的矩阵-向量乘法。
由于X\mathbf{X}X中的每一行代表一个数据样本,那么softmax运算许可按行(rowwise)执行:
对于O\mathbf{O}O的每一行,我们先对所有项进行幂运算,然后凭借求和对它们进行标准化。
在O=XW+b\begin{aligned} \mathbf{O} &= \mathbf{X} \mathbf{W} + \mathbf{b} \end{aligned}O=XW+b中,XW+b\mathbf{X} \mathbf{W} + \mathbf{b}XW+b的求和会使用广播机制,小批量的未规范化预测O\mathbf{O}O和输出概率Y^\hat{\mathbf{Y}}Y^都是形状为n×qn \times qn×q的矩阵。
六、损失函数
1. 对数似然
softmax函数给出了一个向量y^\hat{\mathbf{y}}y^,我们能够将其视为“对给定任意输入x\mathbf{x}x的每个类的条件概率”。例如,y^1\hat{y}_1y^1=P(y=猫∣x)P(y=\text{猫} \mid \mathbf{x})P(y=猫∣x)。
假设整个数据集{X,Y}\{\mathbf{X}, \mathbf{Y}\}{X,Y}具有nnn个样本,其中索引iii的样本由特征向量x(i)\mathbf{x}^{(i)}x(i)和独热标签向量y(i)\mathbf{y}^{(i)}y(i)组成。我们许可将估计值与实际值进行比较:
P(Y∣X)=∏i=1nP(y(i)∣x(i)). P(\mathbf{Y} \mid \mathbf{X}) = \prod_{i=1}^n P(\mathbf{y}^{(i)} \mid \mathbf{x}^{(i)}).P(Y∣X)=i=1∏nP(y(i)∣x(i)).
根据最大似然估计,我们最大化P(Y∣X)P(\mathbf{Y} \mid \mathbf{X})P(Y∣X),相当于最小化负对数似然:
−logP(Y∣X)=∑i=1n−logP(y(i)∣x(i))=∑i=1nl(y(i),y^(i)), -\log P(\mathbf{Y} \mid \mathbf{X}) = \sum_{i=1}^n -\log P(\mathbf{y}^{(i)} \mid \mathbf{x}^{(i)}) = \sum_{i=1}^n l(\mathbf{y}^{(i)}, \hat{\mathbf{y}}^{(i)}),−logP(Y∣X)=i=1∑n−logP(y(i)∣x(i))=i=1∑nl(y(i),y^(i)),
其中,对于任何标签y\mathbf{y}y和模型预测y^\hat{\mathbf{y}}y^,损失函数为:$ l(\mathbf{y}, \hat{\mathbf{y}}) = - \sum_{j=1}^q y_j \log \hat{y}_j. $
2. softmax及其导数
subsec_softmax_and_derivatives
由于softmax和相关的损失函数很常见,
因此我们需要更好地理解它的计算方式。
将y^=softmax(o)其中y^j=exp(oj)∑kexp(ok)\hat{\mathbf{y}} = \mathrm{softmax}(\mathbf{o})\quad \text{其中}\quad \hat{y}_j = \frac{\exp(o_j)}{\sum_k \exp(o_k)}y^=softmax(o)其中y^j=∑kexp(ok)exp(oj)代入损失$ l(\mathbf{y}, \hat{\mathbf{y}}) = - \sum_{j=1}^q y_j \log \hat{y}_j. $中。
利用softmax的定义,我们得到:
l(y,y^)=−∑j=1qyjlogexp(oj)∑k=1qexp(ok)=∑j=1qyjlog∑k=1qexp(ok)−∑j=1qyjoj=log∑k=1qexp(ok)−∑j=1qyjoj. \begin{aligned} l(\mathbf{y}, \hat{\mathbf{y}}) &= - \sum_{j=1}^q y_j \log \frac{\exp(o_j)}{\sum_{k=1}^q \exp(o_k)} \\ &= \sum_{j=1}^q y_j \log \sum_{k=1}^q \exp(o_k) - \sum_{j=1}^q y_j o_j\\ &= \log \sum_{k=1}^q \exp(o_k) - \sum_{j=1}^q y_j o_j. \end{aligned}l(y,y^)=−j=1∑qyjlog∑k=1qexp(ok)exp(oj)=j=1∑qyjlogk=1∑qexp(ok)−j=1∑qyjoj=logk=1∑qexp(ok)−j=1∑qyjoj.
考虑相对于任何未规范化的预测ojo_joj的导数,大家得到:
∂ojl(y,y^)=exp(oj)∑k=1qexp(ok)−yj=softmax(o)j−yj. \partial_{o_j} l(\mathbf{y}, \hat{\mathbf{y}}) = \frac{\exp(o_j)}{\sum_{k=1}^q \exp(o_k)} - y_j = \mathrm{softmax}(\mathbf{o})_j - y_j.∂ojl(y,y^)=∑k=1qexp(ok)exp(oj)−yj=softmax(o)j−yj.
3. 交叉熵损失
我们启用$ l(\mathbf{y}, \hat{\mathbf{y}}) = - \sum_{j=1}^q y_j \log \hat{y}_j来定义损失来定义损失来定义损失l$,它是所有标签分布的预期损失值。
此损失称为交叉熵损失(cross-entropy loss),它是分类障碍最常用的损失之一。
小结
- softmax运算获取一个向量并将其映射为概率。
- softmax回归适用于分类障碍,它应用了softmax运算中输出类别的概率分布。
- 一个衡量两个概率分布之间差异的很好的度量,它测量给定模型编码数据所需的比特数。就是交叉熵
内容声明
本文基于开源教材《动手学深度学习》(Dive into Deep Learning, 作者:Aston Zhang、Zachary C. Lipton、Mu Li、Alexander J. Smola 等)整理,原始项目地址:https://github.com/d2l-ai/d2l-zh。
在整理过程中对部分内容进行了删改和补充,仅用于个人学习与交流,版权归原作者所有。