![[PaperReading] Breaking the Modality Barrier: Universal Embedding Learning with Multimodal LLMs](http://pic.xiahunao.cn/yaotu/[PaperReading] Breaking the Modality Barrier: Universal Embedding Learning with Multimodal LLMs)
- Breaking the Modality Barrier: Universal Embedding Learning with Multimodal LLMs
- TL;DR
- Method
- 阶段一:Textual Discriminative Knowledge Distillation
- 阶段二:Hard Negative Enhanced Instruction Tuning
- 过滤错误负样本
- 困难负例采样策略
- Experiment
- 总结与思考
Breaking the Modality Barrier: Universal Embedding Learning with Multimodal LLMs
link
时间:25.04
单位:The University of Sydney、DeepGlint、Tongyi Lab
相关领域:MLLM
作者相关工作:Tiancheng Gu
被引次数:16
项目主页:https://garygutc.github.io/UniME/
TL;DR
CLIP这类多模态表征方法虽然被广泛应用,但存在三个问题:(1) 文本标记截断, (2) 孤立的图像-文本编码, (3) 因词袋行为导致的组合性缺陷。本文提出UniME (Universal Multimodal Embedding),训练方法是一个两阶段训练,第一阶段用强大LLM-Teacher模型蒸馏提升MLLM的language组件的embedding表征能力,第二阶段通过难负样本指令微调进一步提升表征能力。实验结果在长短caption检索以及组合检索等多个检索任务取得好的效果。
Q:如何理解CLIP存在的上述三个问题?
(1) 文本标记截断
CLIP模型的文本编码器有最大输入长度限制(例如77个标记)。当遇到长文本(如细节丰富的图像描述)时,超出的部分会被直接截断丢弃。
(2) 孤立的图像-文本编
分别对图像和文本进行编码,然后在嵌入空间计算它们的整体相似度。这种机制是“粗粒度”的,它关注的是全局语义匹配,而无法精细地验证文本中的每一个具体陈述是否在图像中有对应。
(3) 因词袋行为导致的组合性缺陷
说CLIP的训练目标导致其文本编码器表现出“词袋”特性,是因为其基于对比学习的全局匹配范式,鼓励模型优先学习能够区分不同文本类别的关键词信号,而相对地弱化了对词序、语法结构和精细修饰关系的建模。
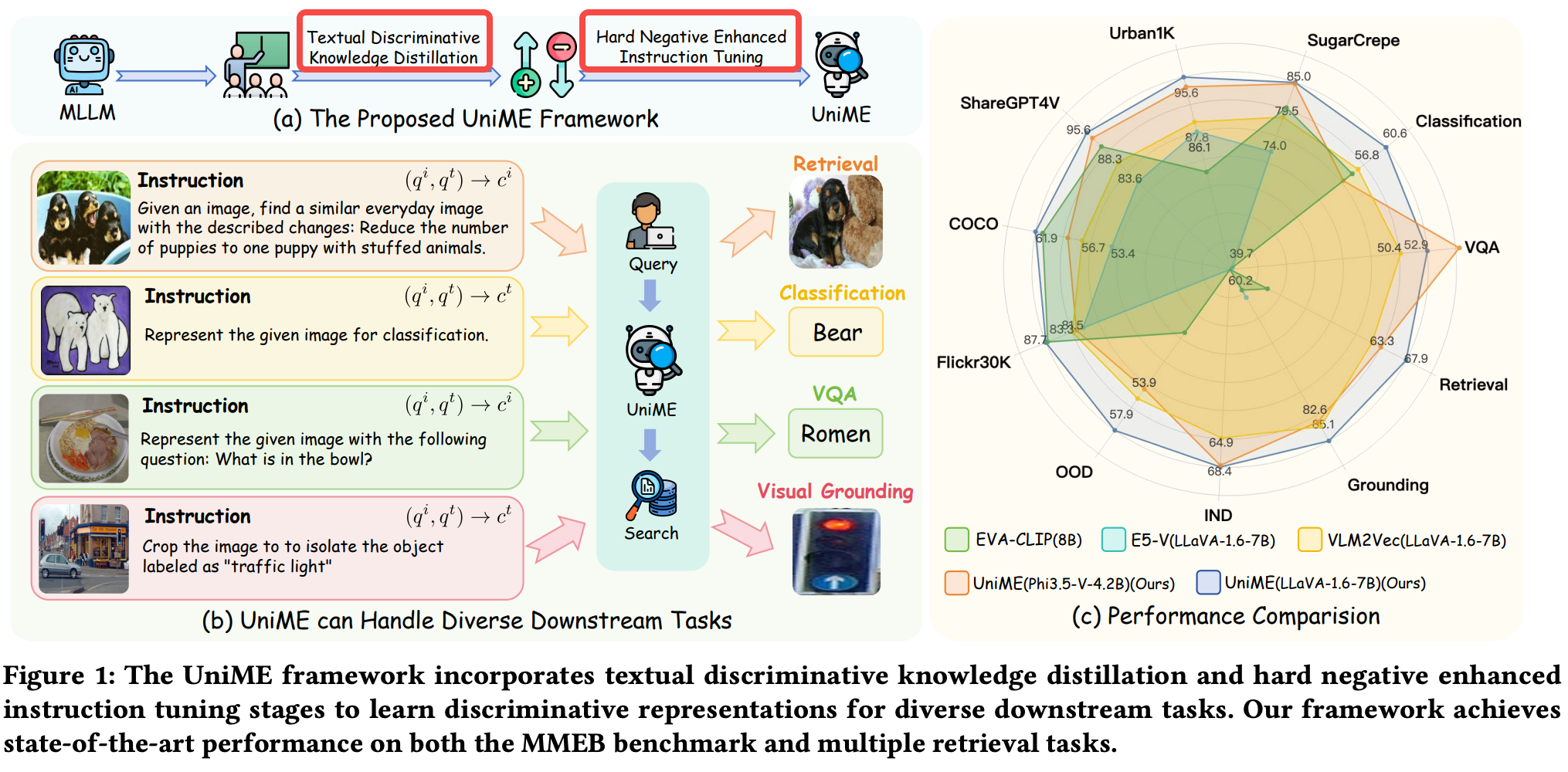
Method
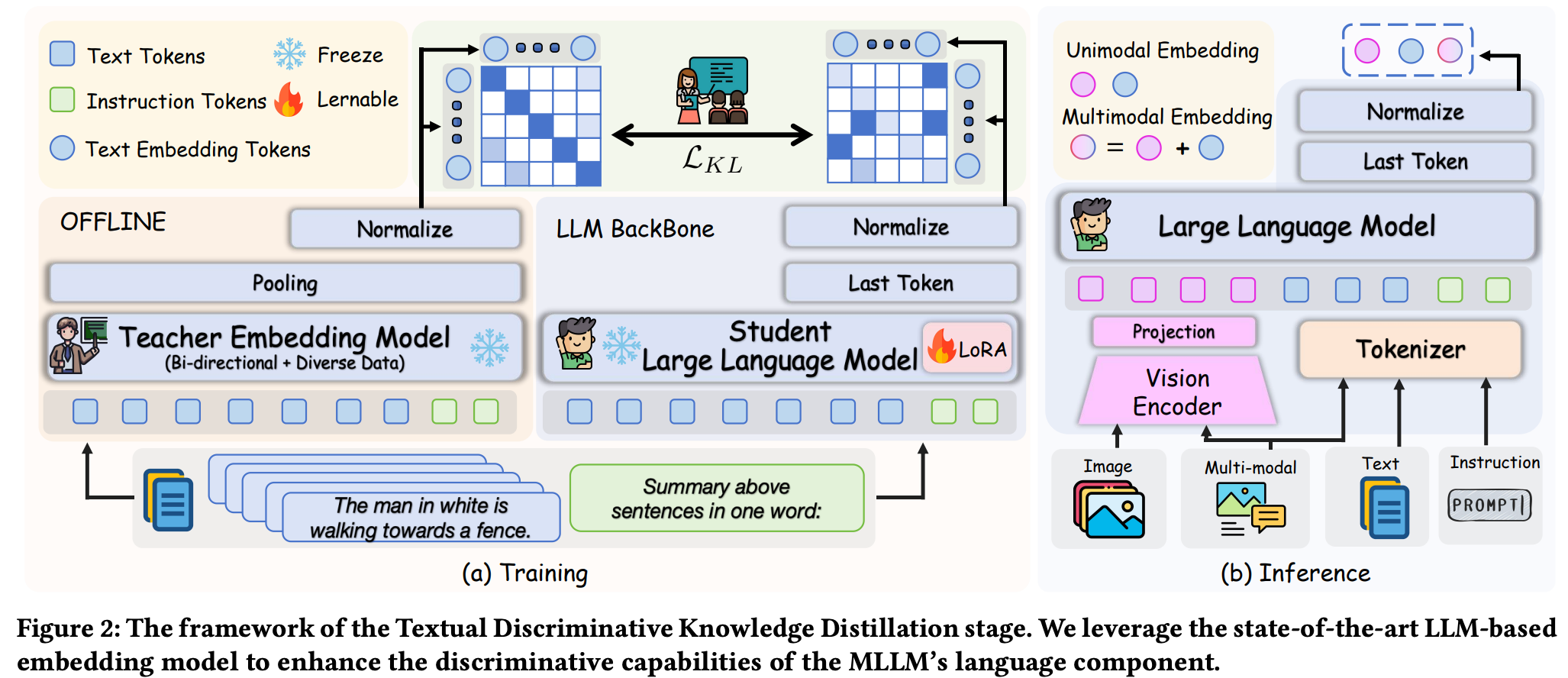
阶段一:Textual Discriminative Knowledge Distillation
使用了一个SOTA LLM-Based嵌入模型NV-Embed V2作为Teacher模型。蒸馏方法:将text encoder从Student MLLM中解耦出来抽取text embedding,Teacher LLM模型也相应抽取embedding,通过KL散度将知识蒸馏给Student。

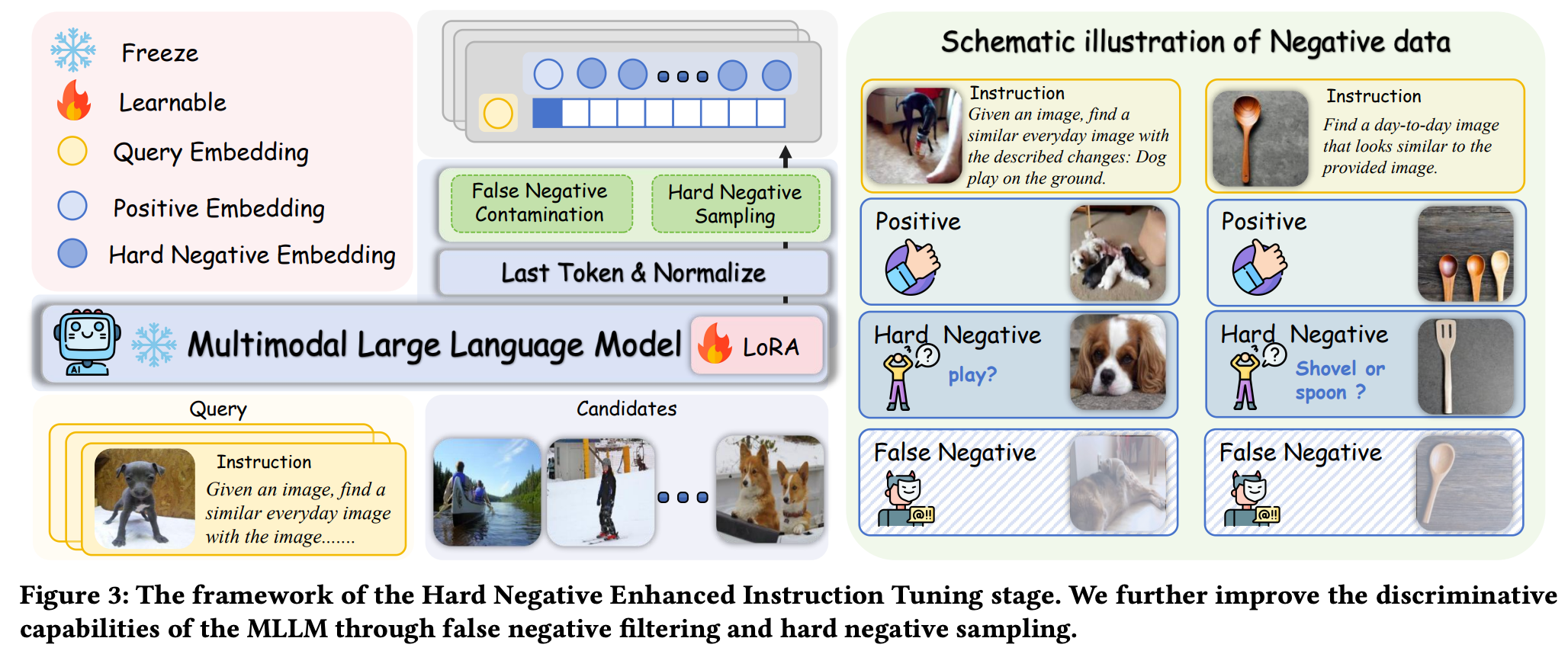
阶段二:Hard Negative Enhanced Instruction Tuning
过滤错误负样本
核心思想:某些样本可能与查询在语义上高度相关(即“正例”),但由于数据标注噪声或语义多样性,被错误地标记为负例,这些样本被称为“假负例”。
\(\alpha = cos(𝑒_{𝑞}, 𝑒_{𝑐}+) + \beta\)
过滤过程:在训练时,所有与查询的相似度超过阈值\(\alpha\)的负例样本都会被排除。这种方法可以有效清除假负例,同时保留那些具有挑战性的“真”困难负例。
困难负例采样策略
核心思想:与容易区分的“简单负例”相比,那些与正例标签不同但embedding表征非常相似的“困难负例”能为模型提供更丰富的梯度信息,从而更有效地提升其判别能力。
采样方法:模型自主地为每个查询识别出困难负例。具体采样公式如下:
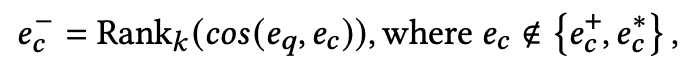
其中,\(𝑒_{𝑐}*\)是经过假负例过滤后的候选样本,\(𝑒_{𝑐}+\)是正例候选,\(𝑒_𝑞\)是查询嵌入。函数\(Rank_𝑘\)会选择与查询最相似的前 k个候选作为困难负例。
实现细节:为保证批次一致性,当采样到的困难负例少于 k个时,会通过复制现有的困难负例来保持固定的数量 k。论文中默认设置 k = 8。
Experiment

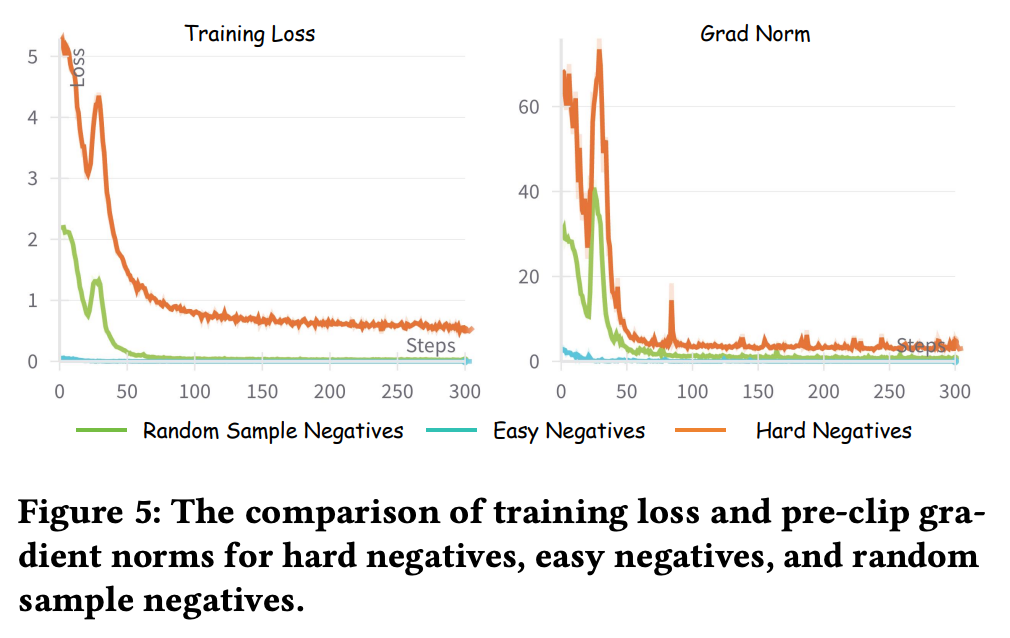
Hard Negatives对应的Loss与梯度都有更大的贡献
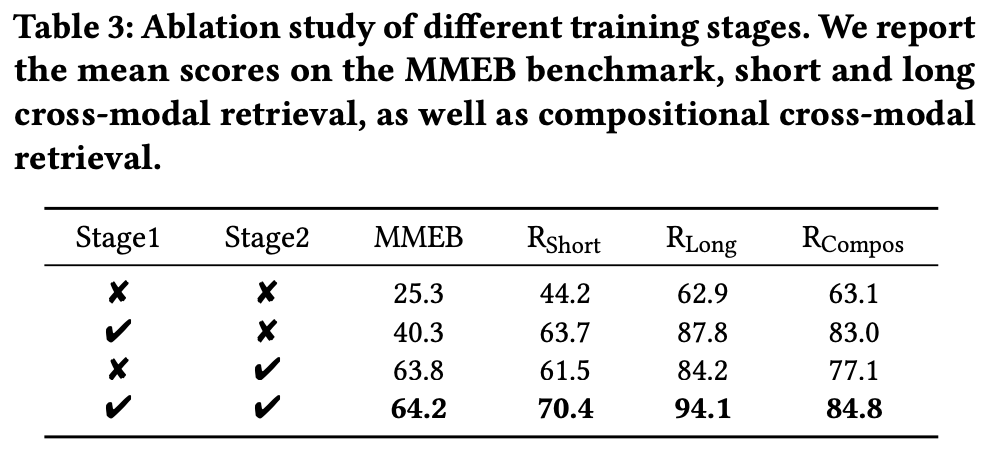
从Ablation来看,Stage1与Stage2对于MMEB指标的提升都挺明显的
对于\(\beta\)与top-k的k两个超参数的ablation study

总结与思考
负样本对于表征学习比较关键,Stage2提供了两种方法,实际应用时超参数需要根据数据集相应调整。