
通用操作
- 数据特征:
key:value形式的数据存储在Redis当中。
redis有16个数据库,下标为0-15,默认为0。
- 登录:
方式1:redis-cli -a password(默认密码为123456)
方式2:redis-cli
auth password (默认密码为123456)
- 退出:
exit
- 查看所有数据:
keys *
- 删除当前数据库(即0数据库)所有数据
flushdb
- 删除所有数据库数据:
flushall
- 选择数据库
select index (例如:select 0)
String类型操作
- 存储数据:
set key value(例如:set k1 100)
- 同时存储多个数据:
mset key value key value ...
- 查看指定数据:
get key (例如:get k1)
- 同时查看多个指定数据:
mget key key ...
- 删除指定数据:
del k1 k2...
- 查看key的长度:
strlen key
- 设置数据的有效时长(s):
方式1:set key value EX seconds (例如:set a 100 EX 10)
方式2:set key value
expire key seconds
- 设置数据的有效时长(ms):
set key value
pexpire key seconds
- 查看剩余有效时长(s):
ttl key
- 取消数据的有效时长:
persist key
- 查看key的数据类型:
type key
- key进行自增
incr key (若key存在则每次自动加1;若key不存在则自动创建,创建后的初始值为1)
incyby key increment (可通过increment指定每次递增的数值,若key存在则每次自动加increment;若key不存在则自动创建,创建后的初始值为指定的increment的数值)
- key进行自减
decr key (若key存在则每次自动减1;若key不存在则自动创建,创建后的初始值为-1)
decrby key decrement (可通过decrement指定每次递减的数值,若key存在则每次自动减decrement;若key不存在则自动创建,创建后的初始值为指定的decrement的数值)
- 追加数据
append key value (若key存在则追加value对应的值;若key不存在则自动创建,创建后的初始值为value)
- 用途:记录某篇文章的点赞数等
Hash类型操作
RedisTemplate对象
- 选择依赖:
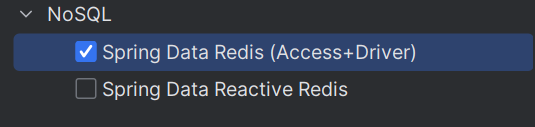
--> 即如下依赖:
org.springframework.boot spring-boot-starter-data-redis
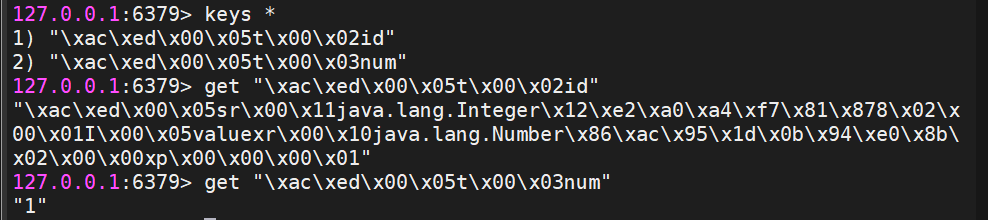
- 示例代码1:
ValueOperations vo=redisTemplate.opsForValue();
vo.set("id","1"); //key和value都会默认采用JDK序列化的方式进行数据存储
String num=vo.increment("num"); //key不存在的时候会自动创建,key会采用JDK序列化的方式进行数据存储,value采用原有的类型进行存储,不会进行序列化存储
System.out.println(vo.get("id"));
System.out.println(num);- 运行此段代码后,可在Linux中查看数据:
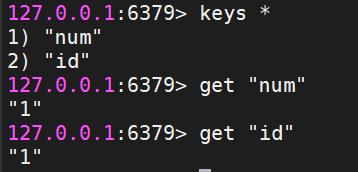
- 示例代码2:
ValueOperations vo=redisTemplate.opsForValue();
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setValueSerializer(RedisSerializer.string());
vo.set("id","1");
vo.increment("num");
System.out.println(vo.get("id"));
System.out.println(vo.get("num"));运行此段代码后,可在Linux中查看数据:
- 示例代码3:
- 写一个外部类,以后写pojo类尽量都实现Serializable接口:
- IDEA自动生成序列化ID

java |
3、写代码:
该处将value使用了json格式的序列化,应该添加如下的依赖(spring-web依赖里面有json格式序列化的方法):
java |
java |
RedisTemplate定制的序列化和反序列化方法
- 通过添加全局配置类实现将key进行string类型的序列化,将value进行json类型的序列化。
- 代码:在base->config下面新建一个RedisConfig的类,添加@Configuration注解,@Bean注解。
- 添加上面提到的redis和spring-web依赖。
java |
Redis缓存测试
- 测试一:

通过上述操作可以发现仍然可以读取到k2的数值,这是因为通过redis-cli shutdown这种方式去停掉redis,其实是一种安全退出的模式,redis在退出的时候会将内存中的数据立即生成一份完整的rdb快照,通过redis日志可以直观地看出RDB缓存。

使用shutdown命令停掉redis之后可以通过redis-server /usr/local/redis/conf/redis.conf命令重启redis
- 测试二:
窗口1命令:

窗口2命令:

窗口3日志:

通过三个窗口的操作,我们可以看出使用kill -9 端口号进行暴力杀死进程后导致后台无法保存尚未保存的数据。
Redis架构设计
主从架构

本次实战,我们设计1个master挂3个slave的主从架构,具体实现过程如下:
第一步:创建主节点(master)的配置文件,名字为redis-6379.conf
Java |
第二步:修改redis-6379.conf文件内容,具体内容如下:
Java |
第三步:创建从节点redis-6380.conf配置文件(cp redis-6379.conf redis-6380.conf),其修改的内容如下:
Java |
第四步:创建从节点redis-6381.conf配置文件(cp redis-6380.conf redis-6381.conf),其修改的内容如下:
Java |
第五步:创建从节点redis-6382.conf配置文件(cp redis-6381.conf redis-6382.conf),其修改的内容如下:
Java |
第六步:启动主从节点服务(可以打开多个窗口,在不同窗口启动不同服务)
Java |
第七步:登录主节点,并检查主从架构状态
Java |
第八步:在主节点写入数据,检查从节点是否可以读取到数据;在任意一个从节点写入数据,检查主节点和其它从节点是否可以读取到数据
经检验都是可以实现的。
哨兵模式
Redis缓存穿透,缓存击穿,缓存雪崩
缓存穿透:
问题描述:
用户查询某一个数据,但该数据不存在于redis内存数据库中(缓存没有命中),这时候就会向持久层数据库查询,但持久层数据库也没有该数据,于是本次查询失败,若用户很多时,他们查询的数据不存在于redis内存数据库中(缓存没有命中),于是都去请求了持久层数据库,这样就会给持久层数据库带来很大的压力,这种大量不走redis内存数据库的现象就叫缓存穿透。
解决方案:
- 布隆过滤器(BloomFilter)
在控制层对请求先进行校验,不符合条件的请求则被丢弃,从而避免对持久层数据库造成的查询压力。
- 缓存空对象
当查询的数据不存在于redis中时,请求到了持久层数据库中去查询数据,但查询不出数据,这时会返回空对象,同时把该空对象缓存到redis里,然后设置一个过期时间,往后只要再次请求查询该条数据,该条数据都会从redis中获取(获取redis返回的空对象),从而保护了后端的数据源。
缺点:
- 因为空对象能被缓存起来,而有些请求有可能查询不出数据,所以过程中可能产生大量的返回空对象然后被redis缓存的现象,而这意味着redis需要更多的空间来存储更多的键。
- 即使对空对象设置了过期时间,但如果在redis的空对象在未过时的情况下,持久层数据库已经有了对应的数据,而redis对应的键的值仍是空对象,这时请求查询出的仍是空对象,而不是持久层里已经有的数据,而这种情况对于需要保持数据一致性的业务会造成影响。
缓存击穿:
问题描述:
redis里的一个key非常热点,导致大并发集中对这个key不断的进行访问,当在这个key过期的瞬间,持续的大并发就会跳过缓存,直接作用在持久层数据库上,请求在访问持久层数据库查询数据的同时,持久层数据库也需要回写缓存,这时候就会导致持久层数据库瞬间压力过大导致服务器宕机,这种现象就叫做缓存击穿。
解决方案:
- 设置热点key永不过期。
- 加互斥锁:使用分布式锁在redis和持久层数据库之间加锁,让每次查询都能保证只有一个线程进去,其他线程等待,这样做就能保证对于每一个key同时只能有一个线程去查询后端持久层数据库,而其他线程没有分布式锁的权限,所以只能等待,这种解决方案把高并发的压力转移到了分布式锁身上,但同时也加大了对分布式锁的考验。
缓存雪崩:
问题描述:
在某一时间段,一批key集中过期失效或者redis宕机,导致大量的请求作用在持久层数据库上,导致持久层数据库挂掉。
解决方案:
- redis高可用:redis集群搭建
- 限流降级:通过加锁或队列来控制读取持久层数据库的线程数量,例如通过对某个key加锁来保证只有一个线程对该key进行读和写,其他线程则需要等待。
- 数据预热:在正式部署前把可能被大量访问的数据先访问一遍,这些被访问的数据就会被加载到缓存中,在正式的大量访问到来之后减轻持久层数据库的压力;在发生大并发访问前手动触发加载缓存所需要的key,并给这些key设置不同的过期时间,让key失效的时间点尽量均匀开来,避免缓存雪崩。
综合案例
案例描述:
基于数据库中字典项表的设计,实现CRUD,基于本地缓存、Redis缓存提高查询的效率,并保证数据的一致性。
案例实现:
步骤一:建立数据库/数据表
sql |
步骤二:引入项目依赖

pom.xml
xml |
步骤三:添加全局配置
application.properties
Properties |
步骤四:添加配置类
Cache.config
java |
Redis.config
java |
JsonResult.java
java |
步骤五:创建实体类
Dict.java
java |
步骤六:创建Mapper
DictMapper.java
Java |
步骤七:创建xml
DictMapper.xml
xml |
步骤八:创建Service
DictService.java
java |
步骤九:创建ServiceImpl
DictServiceImpl.java
java |
步骤十:创建Controller
DictController.java
Java |
步骤十一:创建HttpClient进行测试
dict-api-rest.http
HTTP |
步骤十二:断点测试
在DictServiceImpl.java中添加断点测试缓存是否生效
第一次:本地缓存为NULL,Redis缓存为NULL,执行数据库查询;
第二次:本地缓存存在数据,直接执行本地缓存查询,返回数据。
业务加强:
问题描述:
用户查询某一个数据,但该数据不存在于redis内存数据库中(缓存没有命中),这时候就会向持久层数据库查询,但持久层数据库也没有该数据,于是本次查询失败,若用户很多时,他们查询的数据不存在于redis内存数据库中(缓存没有命中),于是都去请求了持久层数据库,这样就会给持久层数据库带来很大的压力,这种大量不走redis内存数据库的现象就叫缓存穿透,为了解决缓存穿透的问题,我们可以通过设置布隆过滤器来解决。
问题解决:
步骤一:添加布隆过滤器对应的pom依赖
xml |
步骤二:在CacheConfig中添加布隆过滤器配置
Java |
步骤三:在DictServiceImpl中添加布隆过滤器过滤数据逻辑
Java |
消息队列
List实现
步骤一:创建ListQueueService
typescript |
步骤二:测试分析
typescript |
发布订阅
步骤一:创建Service对象
typescript |
步骤二:消息监听对象
java |
步骤三:RedisConfig对象
java |
步骤四:Controller对象
typescript |
步骤五:创建HttpClient进行测试
HTTP |
对比分析
特性 | List(点对点对列) | Pub/Sub(发布订阅) |
消息模型 | 点对点(P2P),消息被消费后即删除 | 广播式,消息发送给所有订阅者 |
消费者行为 | 主动拉取(Pull) | 被动接收推送(Push) |
是否需要监听器 | 否(依赖阻塞命令) | 是(需持续监听频道) |
消息持久化 | 支持(消息保留至被消费) | 不支持(瞬时传递,无存储) |
适用场景 | 任务队列、顺序消费 | 实时通知、事件广播(如聊天室) |