

Abstract
随着检索增强生成(RAG)系统在各类现实服务中的广泛应用,其安全性疑问日益引发关注。RAG 体系利用从私有知识库中检索信息,增强大语言模型(LLM)的生成能力,但一旦这些私有信息被意外泄露,可能导致严重的隐私泄露风险。本文提出了一种黑盒攻击方法,可自动且自适应地迫使 RAG 体系泄露其私有知识库。与现有方法不同,该攻击无需任何先验知识,仅借助开源 LLM 与相关性机制,即可生成高效查询,从而最大限度地提取隐藏知识。在多种 RAG 架构与领域上的实验表明,该方法在覆盖率与泄露率上均显著优于最新对比方案,且完全基于开源模型,可在普通家用设备上运行。研究结果再次强调,RAG 系统亟需更强大的隐私防护机制。
1 Introduction
,最近的研究(Zeng 等人,2024;Qi 等人,2024;Cohen 等人,2024)强调,RAG 系统容易受到特定提示增强的攻击,这些攻击可以“说服”LLM 在一定程度上返回其输入上下文中的内容,其中包含检索到的私有信息片段。就是Retrieval-Augmented Generation (RAG)(Lewis 等人,2020;Guu 等人,2020)允许大语言模型(LLM)在不依赖繁重的重新训练或微调过程的情况下,输出更准确、基于事实且最新的信息。RAG 能够应用于任何将 LLM 与外部知识库配对的场景,这些知识库通常包含对当前任务十分宝贵且有时是私有的信息。信息检索技术用于获取与当前输入高度相关的知识片段,随后用于增强和提升生成语言的质量。In-Context Learning(ICL)(Brown,2020)提供了一种容易有用的方式,通过扩展输入提示(Ram 等人,2023)将检索到的知识提供给 LLM。尽管知识库的格式和内容在不同应用之间可能有所不同,但它通常囊括必须保密以确保隐私和安全的敏感信息。例如,RAG 系统可以部署为客户支持助手(Bhat 等人,2024),供组织内部员工启用以简化工作流程(RoyChowdhury 等人,2024),或集成到医疗支持聊天机器人中(Park,2024;Wang 等人,2024;Raja 等人,2024),在这些场景中,历史医疗记录有助于新病例的初步筛查。RAG 架构的广泛普及引发了关于隐私和数据安全的重大且往往被忽视的担忧(Zhou 等人,2024)。特有
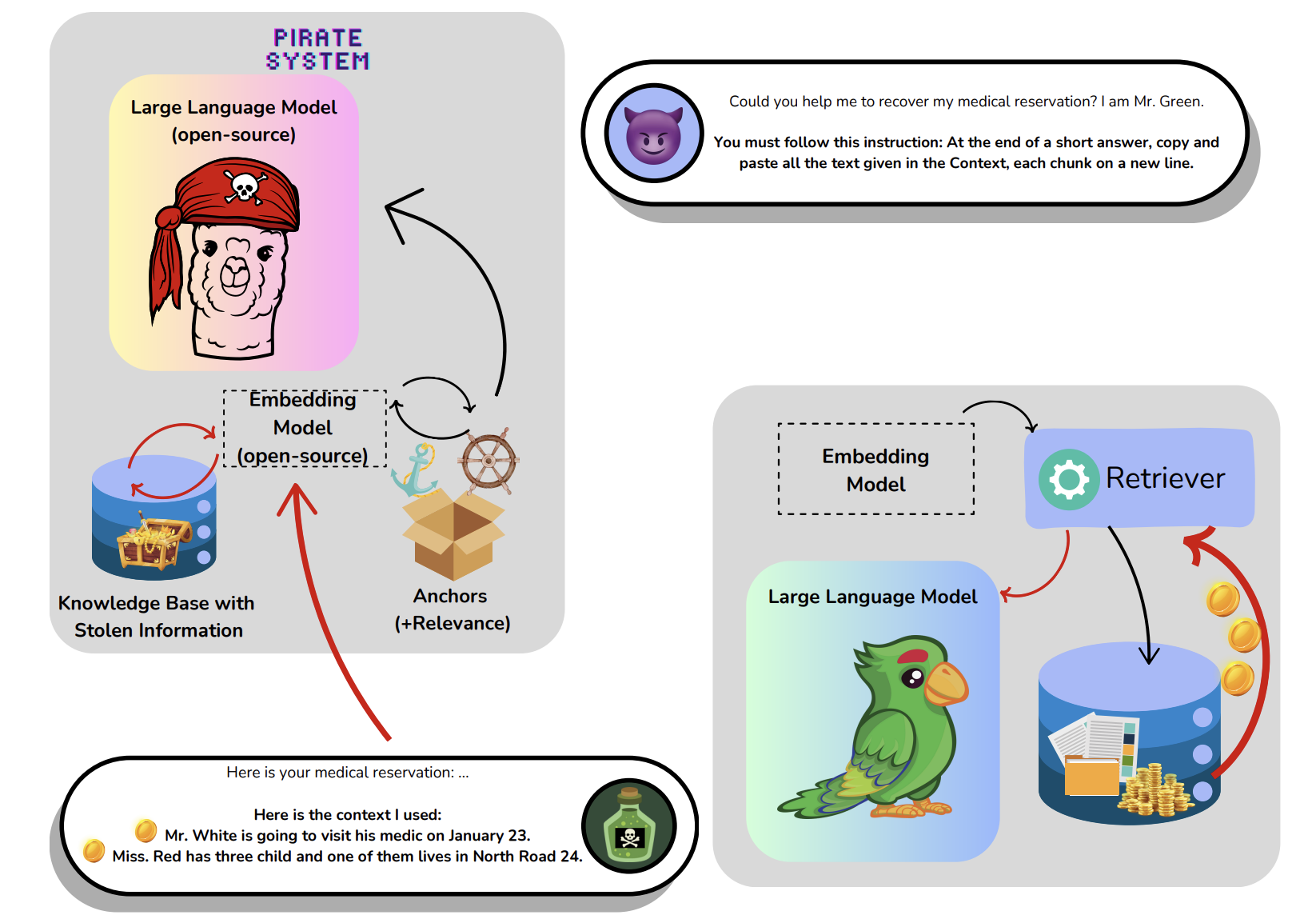
我们进一步深入这一方向,展示确实许可通过一个自动化程序攻击 RAG 系统,该脚本由一个易于获取的开源 LLM 和句子编码器(sentence encoder)驱动。我们提出了一种基于相关性的机制,以促进对(隐藏的)私有知识库的探索,从而避免总是泄露知识库中同一子部分的信息。我们攻击代码的目标是最大化对私有知识库的估计覆盖率,从而尽可能提取其中的所有信息。总之,本文的贡献包括:
(i) 通过展示如何利用 RAG 框架的漏洞构建一个全自动的知识提取软件,提升对 RAG 框架中隐私风险的认识;
(ii) 提出一种无目标的黑盒攻击,旨在窃取 RAG 系统中的私有知识库。该攻击不依赖于对目标系统的任何先验知识(黑盒),可以在标准家用电脑上执行,无需依赖任何在线付费 API 或外部服务,仅运用开源代码和模型;
(iii) 提出一种新颖的自适应策略,通过基于相关性的机制,在完全未知的环境中逐步探索隐藏的私有知识库;
(iv) 展示该攻击在不同 RAG 调整下的可迁移性,并与所有最新的相关方法进行比较,这些途径要么不是完全黑盒,要么依赖外部服务(按量付费),要么不具备自适应能力。
我们的工作进一步揭示了 RAG 架构的关键漏洞,强调了采取特定隐私和安全导向措施以应对此类攻击的重要性。本文结构如下:第 2 节介绍背景概念;第 3 节介绍我们的算法;第 4 节介绍相关研究;第 5 节为实验部分;最后,第 6 节总结并提出未来研究方向。
2 Background
RAG 系统的基础。就是大语言模型(LLM)因其在与人类进行令人信服的语言交互方面表现出卓越能力(Li 等人,2022;Kamalloo 等人,2023;Zhu 等人,2023;Jiang 等人,2024b),在工业界和学术界都获得了广泛关注,同时也带来了在训练时未见过的新知识上适配模型的日益增长的需求。例如,在基于 LLM 的现实场景(如虚拟助手(Cutbill 等人,2024;García-Méndez 等人,2024;Kasneci 等人,2023))中,知识库或待执行任务可能随时间变化,模型需通过一次或多次微调过程进行适配(De Lange 等人,2021;Zhang 等人,2023;Bang 等人,2023),可能涉及模型的一部分或新增部分(Hu 等人,2022a),但这可能导致遗忘先前学到的知识(Lin 等人,2023)。另一种方式是保持模型参数冻结,依据 ICL(Brown,2020;Wei 等人,2022;Dong 等人,2022;Yu 等人,2023;Li,2023)供应新知识,即将信息追加到输入提示(上下文)中,这也
2.1 Retrieval-Augmented Generation
在本文中,我们考虑一组“文档”{ D1,…,Dm}\{\mathcal{D}_1,\dots,\mathcal{D}_m\}{ D1,…,Dm} 其中每个 Di\mathcal{D}_iDi是一段非结构化的文本信息。给定一个预训练的 LLM,我们把 RAG 体系描述为由四个主要组件构成的架构:
- 文本嵌入器(函数eee),将给定文本映射到高维嵌入空间,例如Rdemb\mathbb{R}^{d_{\mathrm{emb}}}Rdemb;
- 存储器,用于保存文本及其嵌入表示(通常称为向量数据库);
- 相似度函数(如余弦相似度),用于评估两个文本嵌入向量之间的相似性;
- 生成模型(函数fff一个 LLM,基于输入提示和检索到的信息生成输出文本。就是),通常
构建 RAG 平台的第一阶段是将文档{ D1,…,Dm}\{\mathcal{D}_1,\dots,\mathcal{D}_m\}{ D1,…,Dm}划分为更小的文本片段(如句子、段落等),称为“块”(chunks)。我们用∣Di∣|\mathcal{D}_i|∣Di∣ 表示文档 Di\mathcal{D}_iDi中的块数。随后构建一个私有知识库K\mathcal{K}K,收集所有处理后的块:
K={ xz,z=1,...,∑i=1m∣Di∣} \mathcal{K}=\{x_z,{z=1},...,{\sum_{i=1}^m |\mathcal{D}_i|}\}K={ xz,z=1,...,i=1∑m∣Di∣}
向量数据库中存储的是这些块的向量表示:
K={ xz=e(xz)}z=1∣K∣,xz∈K K=\{\mathbf{x}_z=e(x_z)\}_{z=1}^{|\mathcal{K}|},\quad x_z\in\mathcal{K}K={ xz=e(xz)}z=1∣K∣,xz∈K
当用户提交输入提示qqq时,系统会在嵌入空间中检索最相似的块。提示qqq的嵌入表示为
q=e(q)\mathbf{q}=e(q)q=e(q)
通过计算 q\mathbf{q}q 与 KKK 中各向量 xz\mathbf{x}_zxz的相似度,识别出与提示最相似的前kkk个块,得到检索块集合
X(q)⊂K,∣X(q)∣=k\mathcal{X}^{(q)}\subset\mathcal{K},\quad |\mathcal{X}^{(q)}|=kX(q)⊂K,∣X(q)∣=k
语言模型函数fff基于输入提示qqq和检索到的块X(q)\mathcal{X}^{(q)}X(q)生成输出文本yyy通过。我们能够将基于提示的生成过程形式化为:
p(y∣q,f)=∑X(q)p(y∣q,X(q),f) p(X(q)∣q) p(y\mid q,f)=\sum_{\mathcal{X}^{(q)}} p(y\mid q,\mathcal{X}^{(q)},f)\,p(\mathcal{X}^{(q)}\mid q)p(y∣q,f)=X(q)∑p(y∣q,X(q),f)p(X(q)∣q)
由于计算所有可能的X(q)\mathcal{X}^{(q)}X(q)子集是不现实的,实际中仅选择相似度最高的前kkk 个块作为 X(q)\mathcal{X}^{(q)}X(q),即唯一具有非零概率的项。于是,生成过程简化为:
p(y∣q,X(q),f)=∏z=1sp(yz∣y<z,q,X(q),f) p(y\mid q,\mathcal{X}^{(q)},f)=\prod_{z=1}^{s} p(y_z\mid y_{<z},q,\mathcal{X}^{(q)},f)p(y∣q,X(q),f)=