
参考
https://github.com/linzm1007/nano-vllm-ascend
Nano-vLLM-Ascend
nano-vllm是开源的一个gpu推理项目,基于开源版本弄的一个ascend npu版本推理小demo,旨在帮助初学者了解推理的整体流程,区别于vllm,nano-vllm体量更小,麻雀虽小五脏俱全,更有助于初学者学习。
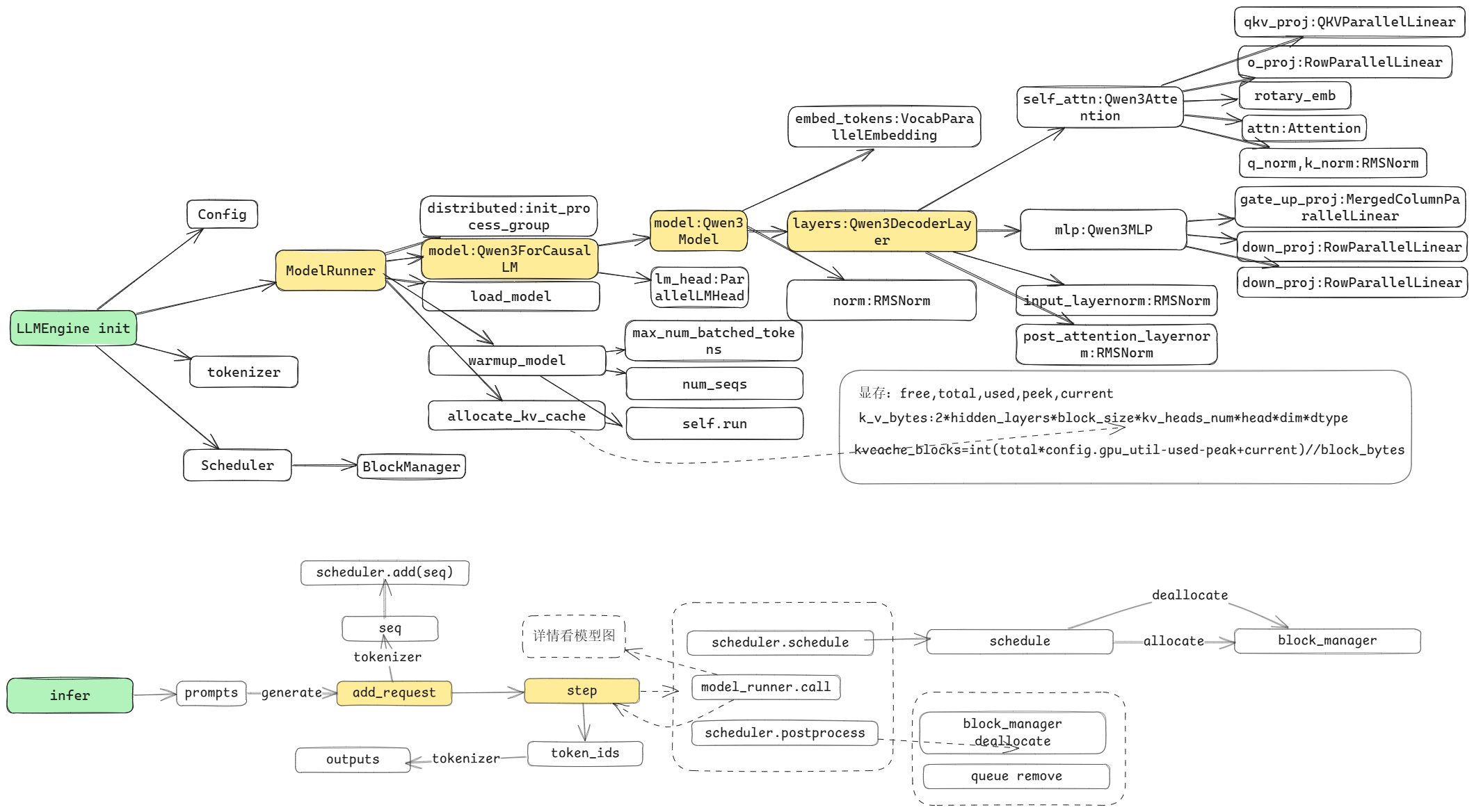
框架层流程图
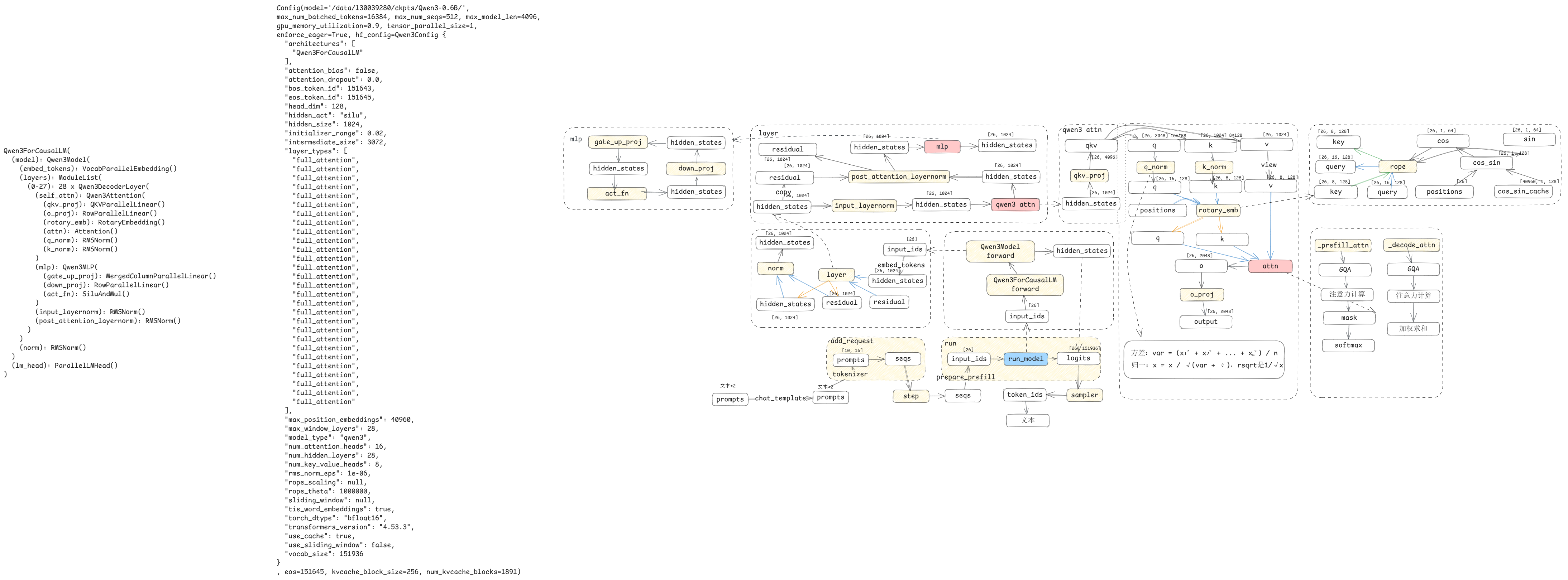
模型层流程图
特性
- 📖 可读代码库 - 约1200行Python代码的清晰实现
- ⚡ 优化套件 - 张量并行、Torch编译等
镜像下载
docker login xx
docker pull xxx/nano-vllm/nano-vllm-ascend:v1_20251112
容器运行
#!/bin/bashCONTAINER_NAME="xxx"# 停止并删除现有容器
docker stop $CONTAINER_NAME 2>/dev/null
docker rm $CONTAINER_NAME 2>/dev/nullecho "Starting SSH container..."docker run -it --name=$CONTAINER_NAME \--shm-size=20g \--net=host \--privileged=true \-u root \-w /data \--device=/dev/davinci_manager \--device=/dev/hisi_hdc \--device=/dev/devmm_svm \-v /data:/data \-v /tmp:/tmp \-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \-v /usr/local/dcmi:/usr/local/dcmi \-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \-v /etc/ascend_install.info:/etc/ascend_install.info \-v /usr/local/sbin:/usr/local/sbin \-v /etc/hccn.conf:/etc/hccn.conf \-v /usr/bin/hccn_tool:/usr/bin/hccn_tool \-v /usr/share/zoneinfo/Asia/Shanghai:/etc/localtime \xxx/nano-vllm/nano-vllm-ascend:v1_20251112 bash安装依赖
pip install .
ssh安装
#!/bin/bash
set -ex# 配置openEuler软件源
echo "配置openEuler软件源..."
cat > /etc/yum.repos.d/openeuler.repo << 'EOF'
[openEuler-everything]
name=openEuler-everything
baseurl=http://mirrors.tools.xx.com/openeuler/openEuler-22.03-LTS-SP4/everything/aarch64/
enabled=1
gpgcheck=0
gpgkey=http://mirrors.tools.xx.com/openeuler/openEuler-22.03-LTS-SP4/everything/aarch64/RPM-GPG-KEY-openEuler[openEuler-EPOL]
name=openEuler-epol
baseurl=http://mirrors.tools.xx.com/openeuler/openEuler-22.03-LTS-SP4/EPOL/main/aarch64/
enabled=1
gpgcheck=0[openEuler-update]
name=openEuler-update
baseurl=http://mirrors.tools.xx.com/openeuler/openEuler-22.03-LTS-SP4/update/aarch64/
enabled=1
gpgcheck=0
EOFyum clean all
yum makecache yum install passwd -y# 设置root用户密码
echo "设置root用户密码..."
echo "root:xxxx-" | chpasswd# 配置SSH服务
echo "配置SSH服务..."
# 启用TCP转发
sed -i 's/^#AllowTcpForwarding yes/AllowTcpForwarding yes/' /etc/ssh/sshd_config
# 启用GatewayPorts
sed -i 's/^#GatewayPorts no/GatewayPorts yes/' /etc/ssh/sshd_config
# 添加端口6068(若不存在)
if ! grep -q "^Port 6068" /etc/ssh/sshd_config; thenecho "Port 6068" >> /etc/ssh/sshd_config
fi# 生成SSH密钥并重启服务
echo "初始化SSH服务..."
ssh-keygen -A
/usr/sbin/sshdecho "所有配置完成!root密码已设置,SSH服务已启动(监听端口6068)"
容器起来,ssh也安装好,可以远程连接容器运行example.py
模型下载
huggingface-cli download --resume-download Qwen/Qwen3-0.6B \--local-dir ~/huggingface/Qwen3-0.6B/ \--local-dir-use-symlinks False
快速开始
请参见 example.py 了解用法。该 API 与 vLLM 的接口基本一致,仅在 LLM.generate 方法上存在一些细微差异:
from nanovllm import LLM, SamplingParams
llm = LLM("/YOUR/MODEL/PATH", enforce_eager=True, tensor_parallel_size=1)
sampling_params = SamplingParams(temperature=0.6, max_tokens=256)
prompts = ["Hello, Nano-vLLM."]
outputs = llm.generate(prompts, sampling_params)
outputs[0]["text"]
example运行结果

环境
仅供参考
ascend-dmi -c #查看
- 硬件环境:
- 1.显卡:A3 910C
- 2.驱动版本:24.1.rc3.10
- 3.固件版本:7.5.0.109.220
- 软件环境:
- 1.CANN包 8.3.RC1
- 2.PTA版本:torch-npu 2.5.1.post2+gitd7a85f8,torch 2.5.1
Benchmark
See bench.py for benchmark.
Test Configuration:
- Model: Qwen3-0.6B
- Total Requests: 256 sequences
- Input Length: Randomly sampled between 100–1024 tokens
- Output Length: Randomly sampled between 100–1024 tokens
Performance Results:
Nano-vLLM-Ascend 实在太慢了只跑了10条seq
Nano-vLLM-Ascend可以忽略[哭脸]
| Inference Engine | Output Tokens | Time (s) | Throughput (tokens/s) |
|---|---|---|---|
| vLLM | 133,966 | 98.37 | 1361.84 |
| Nano-vLLM | 133,966 | 93.41 | 1434.13 |
| Nano-vLLM-Ascend | 4805 | 257.49 | 18.66 |
qwen3-0.6B layers
ModuleList((0-27): 28 x Qwen3DecoderLayer((self_attn): Qwen3Attention((qkv_proj): QKVParallelLinear()(o_proj): RowParallelLinear()(rotary_emb): RotaryEmbedding()(attn): Attention()(q_norm): RMSNorm()(k_norm): RMSNorm())(mlp): Qwen3MLP((gate_up_proj): MergedColumnParallelLinear()(down_proj): RowParallelLinear()(act_fn): SiluAndMul())(input_layernorm): RMSNorm()(post_attention_layernorm): RMSNorm())
)