:从内存模型到 Online Softmax)
在 “Attention Is All You Need” 这篇论文中,我们了解了注意力机制的三个关键矩阵:Q (Query)、K (Key) 和 V (Value)。
在标准的注意力计算流程中,核心步骤包括计算注意力得分矩阵 \(S=QK^T\) 以及 Softmax 后的概率矩阵 \(P\)。当序列长度 \(R\) 很大时,这些 中间结果(\(S\) 和 \(P\) 矩阵) 的维度高达 \((R,R)\),需要占用巨大的显存空间。
传统的实现方式必须频繁地在 GPU 高速缓存 (SRAM) 与 GPU 显存 (HBM) 之间读写这些巨大的中间矩阵。当矩阵规模扩大时,GPU 的计算能力实际上被 显存带宽(Memory Bandwidth) 限制,导致 GPU 单元大部分时间处于空闲等待状态,无法充分发挥其计算潜能。
为了解决这一瓶颈,FlashAttention 论文提出了一种方法。该方法不同于传统计算方法,设计该方法时是基于 IO 带宽受限这一前提,利用 Tiling(分块) 技术计算输出矩阵 \(O\),并在 SRAM 上不需要中间结果 \(S\) 和 \(P\) 矩阵就能完成 Softmax 归一化。这种方法能够极大程度地降低对 HBM 的访问次数,从而显著提升 GPU 的计算效率和速度。
硬件性能分析
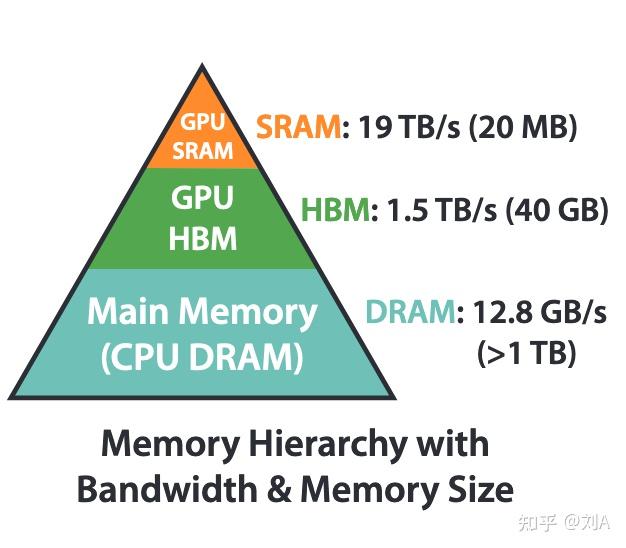
GPU 存储层次
跟 CPU 存储层次类似,在 GPU 中也存在不同的存储介质,不同的介质之间的访问速度以及容量有着巨大的差距,这里不再过多赘述:
两种计算操作
计算密集:程序运行时,GPU 处于满负荷工作状态的时间占据程序运行的绝大部分,这类程序主要受限于计算吞吐量,不会频繁大量的访问显存。典型应用为大矩阵乘法和多通道卷积计算。
访存密集:程序运行时需要频繁大量的访问显存,GPU 出现频繁的空等,导致 GPU 的计算资源被浪费,典型应用为如元素操作(激活函数、Dropout)以及归约化操作(求和、softmax、批归一化、层归一化)。
传统 Attention 实现
Attention 计算有三个关键矩阵,分别是 \(Q\), \(K\), \(V\) \(\in \mathbb{R}^{N \times d}\) ,其中 \(N\) 是输入序列的长度,\(d\) 是头维度,我们想使用以上三个矩阵计算出输出矩阵 \(O \in \mathbb{R} ^ {N \times d}\) :
在上面的公式中有两个中间变量,分别是 \(S\) 和 \(P\),每次生成这两个中间变量时都需要向显存中存储,之后计算下一步时再将其从显存中取出,但是最后这两个中间变量的值对我们又没有什么用。并且这两个中间变量矩阵非常庞大(\(S,P \in \mathbb{R}^{N \times N}\),\(N\) 的维度非常高,比如在 GPT 2 中,\(N\) = 1024),对显存的频繁大量访问将 Attention 操作变为了访存密集型程序,GPU 的算力资源被大大浪费了。
| 步骤 | 操作描述 (Operation) | 内存操作 (I/O) | 中间结果 |
|---|---|---|---|
| 1 | 加载 \(Q\) 和 \(K\) 分块,计算得分矩阵 \(S = QK^T\)。 | 读 (HBM) \(Q, K\) 分块,写 (HBM) \(S\) | \(S\) |
| 2 | 读取 \(S\),计算概率矩阵 \(P = \text{softmax}(S)\)。 | 读 (HBM) \(S\),写 (HBM) \(P\) | \(P\) |
| 3 | 加载 \(P\) 和 \(V\) 分块,计算输出矩阵 \(O = PV\)。 | 读 (HBM) \(P, V\) 分块,写 (HBM) \(O\) | \(O\) |
| 4 | 返回 \(O\)。 | - | - |
FlashAttention 核心思想
FlashAttention 旨在将 \(QK^T\)、Softmax 和 \(PV\) 三个步骤融合 (Fusion) 为一个 I/O 感知的操作,从而在 SRAM 上在线完成计算,避免将中间结果写入 HBM。
由于 SRAM 容量有限,无法加载全部 \(Q,K,V\) 矩阵,该方法利用 Tiling(分块) 技术,将大矩阵分解成小块,逐次加载进 SRAM 中进行计算,并将结果矩阵 \(O\) 一部分写回 HBM。
对于矩阵乘法 \(S=QK^T\) 和 \(O=PV\),利用现有的分块乘法即可处理。然而,对于 \(P=softmax(S)\) 来说,由于 Softmax 固有的全局依赖性(必须看到输入 \(S\) 矩阵的每一行(对应一个 \(Q\) Token)的全部值才能正确计算归一化分母)。因此,如何在这种分块限制下保证 Softmax 的正确性,才是 FlashAttention 解决问题的核心挑战。
稳定 Softmax 算法
在 Softmax 分块计算之前先介绍一下 Numercally Stable Softmax 算法。
原始 Softmax 的定义如下:
目前常用的 FP16、FP32 浮点数格式所能表示的最大值分别是\(3.4 \times 10^{38}\) 和 \(65504\),当 \(x^i\) 比较大时,\(e^{x_i}\) 就会溢出,无法被正确表示。而当 \(x_i\) 比较小时,\(e^{x_i}\) 将会非常接近 0,则 \(Softmax(x)_i\) 将会出现除 0 下溢错误。
在指数函数中存在一种特性称为平移不变性,考虑这个公式:
将分子分母同除一个常数 \(C=e^c\):
因此,我们可以根据 Softmax 的平移不变性这一特性对原始公式进行改造:首先,获取输入向量 \(x\) 中的最大值 \(m(x)\),然后将 Softmax 公式的分子和分母都除以 \(e^{m(x)}\),这确保了 Softmax 的值保持不变。在这一缩放操作过程中,由于分子 \(e^{x_i}\) 中的 \(x_i\) 减去了 \(m(x)\),因此所有的分子项 \(e^{x_i}−m(x)\) 都将维持在一个 \((0,1]\) 的安全区间内,从而彻底消除了指数运算产生上溢的风险。同时,分母由所有这些分子项相加得到,并且其中至少存在一项 \(e^{{m(x)}−x_i=0}\) 等于 1,这使得分母能够保证大于等于 1,有效避免了分母为零导致的下溢问题。
完整公式如下:
Softmax 分块计算
现在有两个向量\(x^{(1)}, x^{(2)}\) ,将这两个向量拼接成一个向量 \(x=[x^{(1)}, x^{(2)}] \in \mathbb{R}^{2B}\),有以下公式:
对于第二个公式来说:
对于 \(f(x)\) 来说,并不像 \(m(x)\) 能够直接由 \(x^{(1)} \quad x^{(2)}\) 拼接而来,这是因为 \(f(x^{(1)})\) 和 \(f(x^{(2)})\) 的缩放基准分别为 \(m(x^{(1)})\) 和 \(m(x^{(2)})\),而非全局最大值 \(m(x)\)。为了将缩放基准转换为 \(m(x)\),需要找到一个合适的缩放因子 \(C_1\),使得 \(f(x^{(1)}) \cdot C_1 = e^{x^{(1)}-m(x)}\)。解一下这个方程,得出 \(C_{1} = e^{m(x^{(1)})-m(x)}\),同样的,得出 \(C_{2} = e^{m(x^{(2)})-m(x)}\),然后将这两个缩放因子与 \(f(x^{(1)})\) 和 \(f(x^{(2)})\) 相乘,得出整个 \(f(x)=[e^{m(x^{(1)})-m(x)}f(x^{(1)}) \quad e^{m(x^{(2)})-m(x)}f(x^{(2)})]\)。
我们再利用相反的思路来考虑这个问题,\(m(x)\) 肯定等于 \(m(x^{(1)})\) 或 \(m(x^{(1)})\),我们就假设 \(m(x)=m(x^{(2)})\),则 \(f(x)\) 的第二项就只剩 \(f(x^{(2)})\) 了,将第一项展开为 \(e^{m(x^{(1)})-m(x)}e^{x^{(1)}-m(x^{(1)})}=e^{x^{(1)}-m(x)}=e^{x^{(1)}-m(x^{(2)})}\),由此,我们成功地将两个 Softmax 分子项 \(f(x^{(1))})\) 和 \(f(x^{(2)})\) 都转换到了统一的、以 \(m(x^{(2)})=m(x)\) 为基准的数值空间。
对于公式 \((3)\) 来说,其原理与公式 \((2)\) 一致。
逐步更新
存在向量 \(x\),\(x = [x^{(1)}, x^{(2)}, \dots, x^{(N)}]\)
假设当前已经处理了前 \(k-1\) 块,得到了:
- 当前全局最大值: \(m^{(k-1)}\)
- 当前全局归一化项: \(\ell^{(k-1)}\)
现在处理新块 \(k\),它有: - 局部最大值: \(m_k\)
- 局部归一化项:\(\ell_k\)
然后更新全局最大值 \(m^{(k)}\) 与全局归一化因子 \(l^{(k)}\)
FlashAttention 算法伪代码
输入:
- 矩阵 \(Q, K, V ∈ \mathbb{R}^{N×d}\)(存放在 HBM)
- 片上 SRAM 容量 \(M\)
1. 设置分块大小
- \(B_c = \lceil \frac {M} {4d}\rceil\)
- \(B_r = min(\lceil {\frac {M} {4d}} \rceil, d)\)
2. 初始化(存于 HBM)
- \(O = 0_{N×d}\)
- \(\ell = 0_{N}\)
- \(m = -\infty_{N}\)
3. 分块
- 将 \(Q\) 按行划分为
\(T_r = \lceil \frac {N} {B_r} \rceil\)
得到块:\(Q_1 … Q_{T_r}\),每块大小 \(B_r × d\) - 将 \(K, V\) 按列划分为
\(T_c = \lceil \frac {N} {B_c} \rceil\)
得到:\(K_1 … K_{T_c}\)、\(V_1 … V_{T_c}\),每块大小 \({B_c × d}\) - 输出及辅助变量对应分成:
\(O_i, \ell_i, m_i\)(大小分别为 \(B_r × d\)、\(B_r\)、\(Br\))
4. 主循环

一些自己的理解
分块大小的选择
为什么要这样选择分块大小?
- \(B_c = \lceil \frac {M} {4d}\rceil\)
- \(B_r = min(\lceil {\frac {M} {4d}} \rceil, d)\)
这是因为 FlashAttention 的一次计算要在 GPU 的 SRAM 中至少存放四个矩阵:\(Q_{i}, K_{i}, V_{i} ,O_{i}\)
这四个矩阵总大小为:\(2B_{c}d+ 2B_rd\)。
在 FlashAttention 的设计策略倾向于一半的 SRAM 分配给 \(K/V\),一半给 \(Q/O\)。
假设 \(B_r\) 与 \(B_c\) 近似,则四个矩阵总大小为:\(4B_{r}d \approx 4B_{r}d\)。
为了保证这四个矩阵能够同时放入 SRAM,需要满足 \(B_{r} \leq \frac {M} {4d}\),而对于 \(B_r\) 的另一个值 \(d\) 来说,这是因为在计算 softmax 的时候,如果某行变得太大,则会降低计算效率。
主循环更新 \(O_i\) 操作
\(diag()\)函数为对角矩阵构造函数,该函数能够将一个向量转换为一个对角矩阵。
将\(O_i = diag(\ell^{new}_i)^{-1}(diag(\ell_i)e^{m_i - m^{new}_i}O_i+ e^{\tilde{m}_{ij} - m^{new}_i} \tilde{P}_{ij}V_j)\)拆分为三部分:
- Part1: \(diag(\ell_i)e^{m_i - m^{new}_i}O_i\)
- Part2: \(e^{\tilde{m}_{ij} - m^{new}_i} \tilde{P}_{ij}V_j\)
- Part3: \(diag(\ell^{new}_i)\)
因此整个公式可以简化为:\(O_{i}= \frac {Part1 + Part2} {Part3}\)
现在理解一下为什么要这样做,对于 Part1 来说,\(diag(\ell_i)O_i\) 操作在恢复旧的总和(\(\ell_i\)是旧的归一化常数),\(diag(\ell_i)e^{m_i - m^{new}_i}O_i\)再用新的归一化常数计算以新的 \(m^{new}_i\)为基准的旧总和;Part 2 是计算当前块 \(K_j,V_j\) 的贡献项。它是将基于局部最大值 \(\tilde{m}_{ij}\)** 算出的加权总和 \(\tilde{P}_{ij}\),通过乘以指数校正因子 \(e^{\tilde{m}_{ij}-m^{new}_i}\),平移校正为以新的全局最大值 \(m^{new}_i\) 为基准的贡献总和;Part3 作为新旧总和相加得到的新的全局总和的分母,也就是全局归一化常数 \(\ell^{new}_i\)。
经过以上操作,新的 \(O_i\) 就被计算出来了。
通俗类比:计算班级平均分
为了理解这个操作,我们可以想象你在计算一个不断有新学生进入的班级的平均分。
- \(O_i\) (旧输出):相当于 “A组学生的平均分”。
- \(\ell_i\) (旧分母):相当于 “A组学生的人数”。
- 新数据:相当于 “B组学生的总分”。
- 目标:计算 A组 + B组 的总平均分。
现在不能直接把“A组平均分”和“B组平均分”加起来除以2。必须这样做:
- 反归一化(还原总分):
A组总分=A组平均分×A组人数
(对应公式中的 \(diag(\ell_i)O_i\)) - 合并:
全班总分=A组总分+B组总分
(对应公式中的括号内相加) - 重归一化(算新平均):
新平均分=全班总人数全班总分
(对应公式中的 \({diag(\ell^{new_i})^{−1}}\))
FlashAttention 的公式就是在做这个“加权平均更新”,只不过它多了一个步骤:因为它处理的是指数函数 (\(e^x\)),所以还需要处理 \({m_i}\) 变化带来的“指数缩放修正”。