Part1 代码练习
螺旋分类实验过程
初始准备

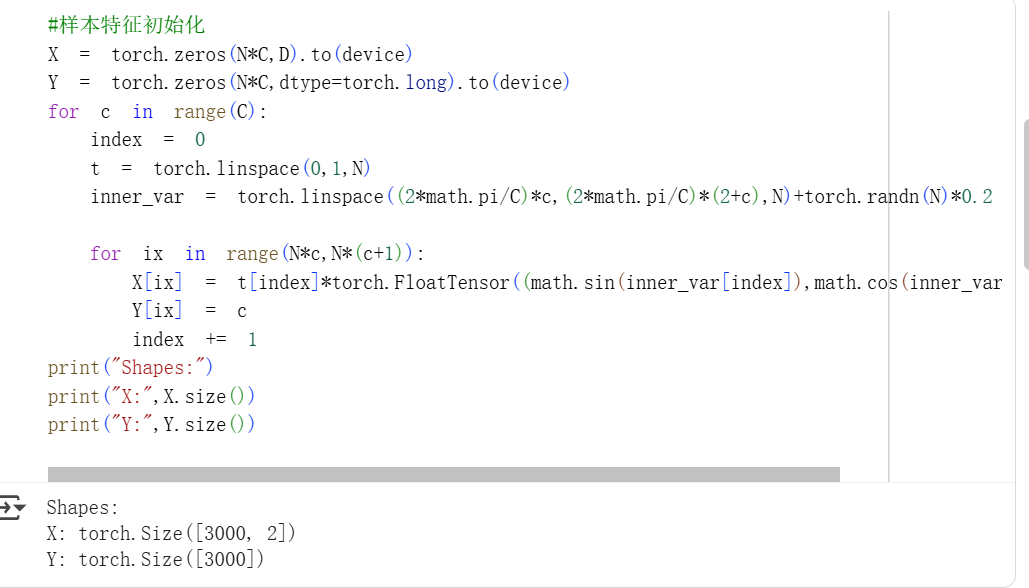
生成样本

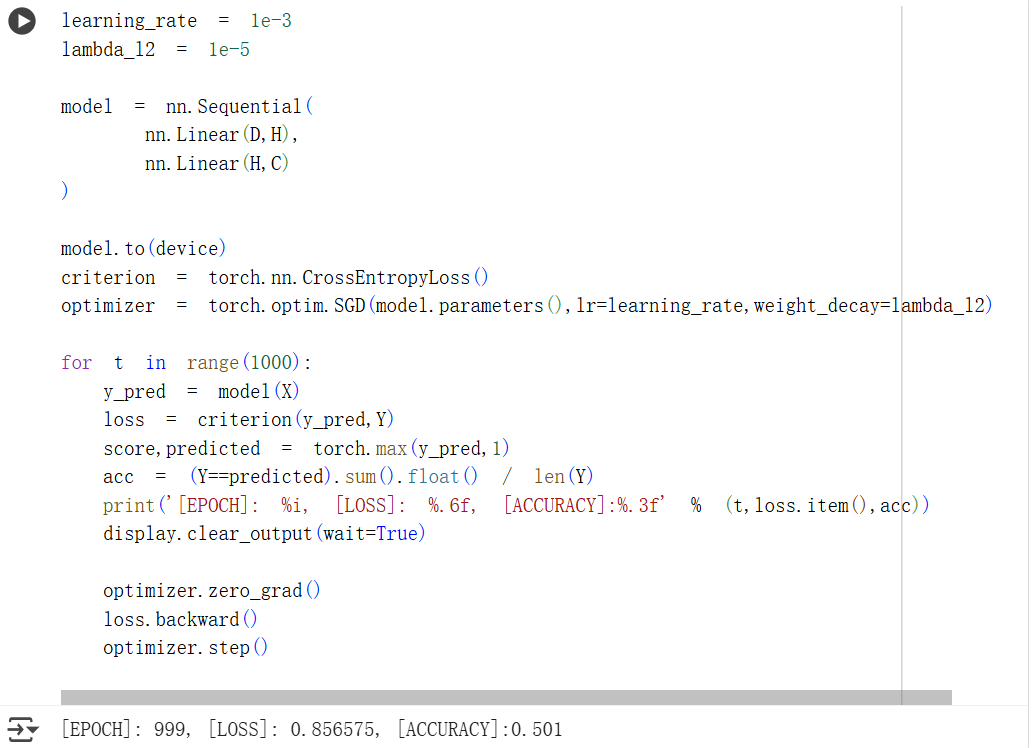
线性模型分类
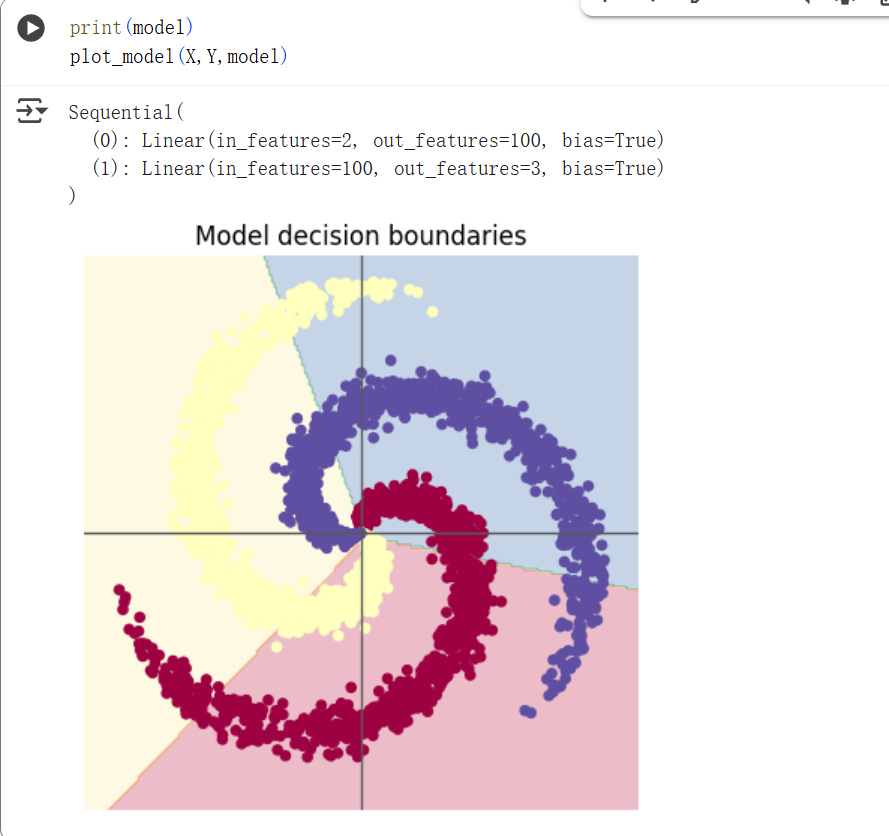
神经网络分类
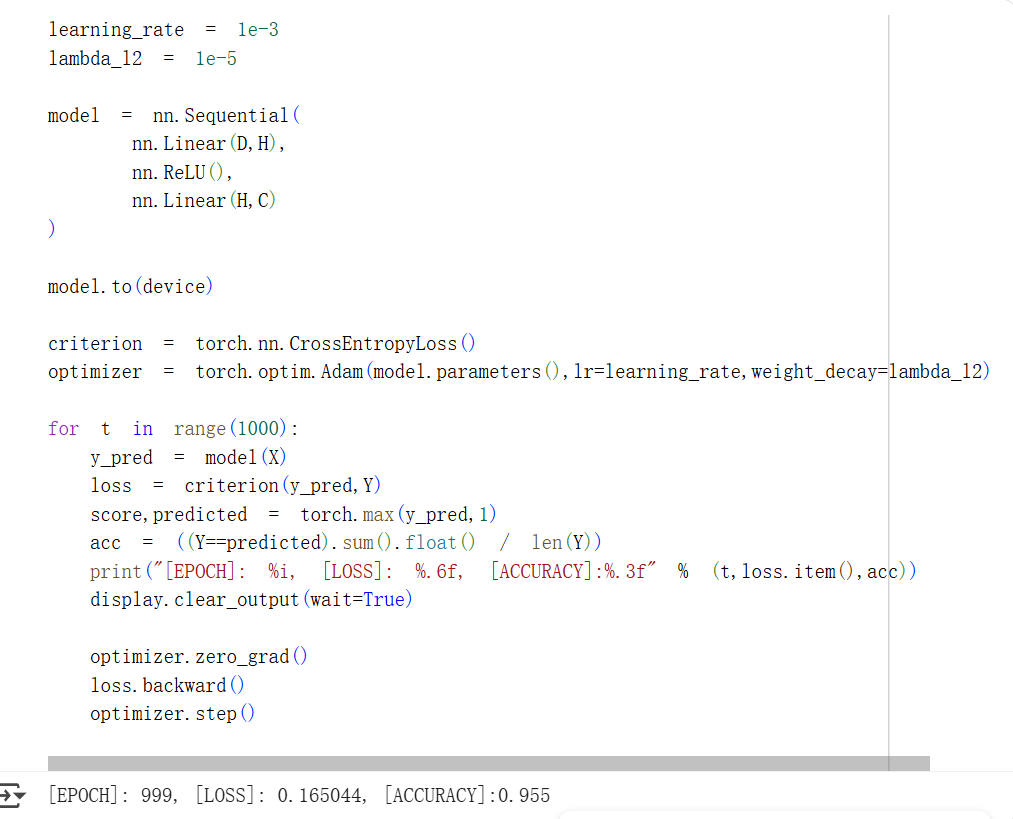

反思总结
问题与解决
首次尝试中,在进行神经网络分类时,损失和准确率的结果与线性模型基本一样,没有明显改善。
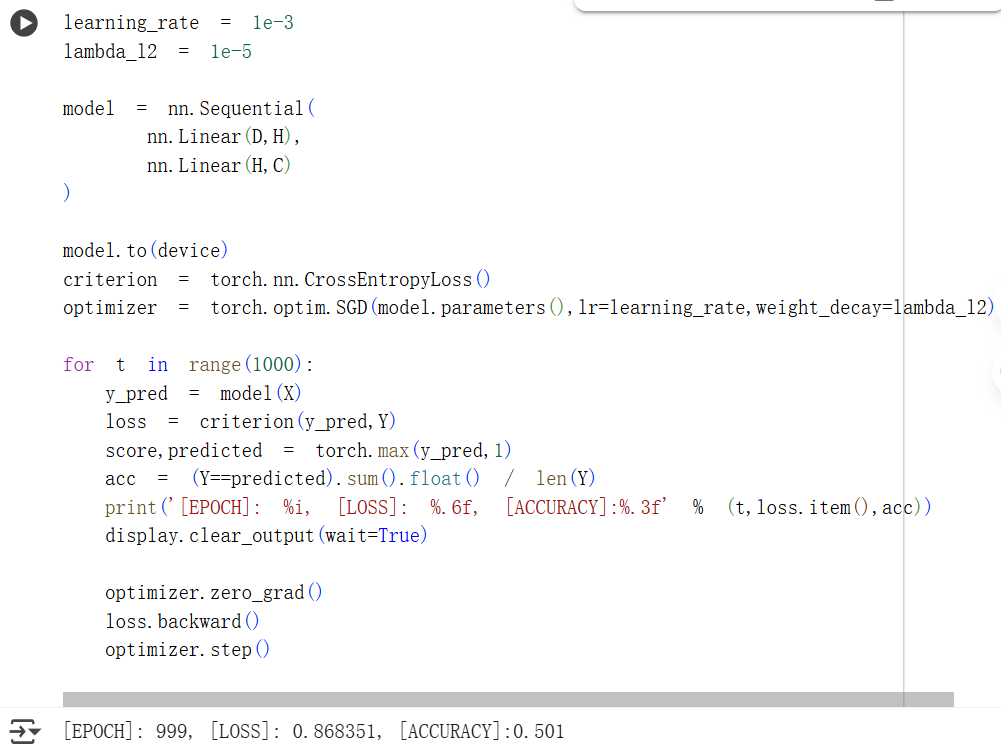
检查错误后,发现在设置优化器时,仍然使用的是SGD分类模型。
总结
模型优化过程对模型影响结果重大
Part2 问题总结
AlexNet有哪些特点?为什么可以比LeNet取得更好的性能?
- Alex使用了参数更大,计算复杂的更高的模型
- 使用了MaxPooling替换AverPooling,保留了更大的梯度,收敛更快
- 激活函数使用ReLU替换了sigmoid
- 加入了丢弃层实现正则
激活函数有哪些作用?
- 最核心作用:引入非线性
- 控制输出范围。sigmoid[0,1],ReLU[0,]
- 决定神经元。ReLU函数可以过滤负数输入。
梯度消失现象是什么?
在反向传播过程中,梯度趋近于0,导致参数无法被更新
神经网络是更宽好还是更深好?
该问题目前没有明确答案
深度和宽度的概念从MLP而来,宽度是每层的feature数,深度是提取阶段数
更宽的网络有更多的子网络,对比小网络更有产生梯度相干的可能;更深的网络,梯度相干现象被放大。
深度代表了函数的表示能力,宽度关联了优化的难易程度。
在参数固定的情况下,如果任务更关注局部特征、浅层特征,可以提高宽度;如果更关注全局特征,可以提高深度。
为什么要使用Softmax?
softmax用来进行归一化处理,将模型的线性输出转换为对应概率输出[0,1]。
为什么选择引入e,而非直接线性处理?
指数增长的特性:横轴变化很小的两,纵轴会有较大变化。引入e,可以增大两个相邻输出的概率差,可以更明确的分类。
SGD和Adam哪个更有效?
该问题没有明确答案
Adam简化了调参,且在小样本时,收敛速度快。但在样本较大时,后期学习率太低,且容易对前期出现的特征过拟合。
有人提出在优化过程中,前期用Adam,享受快速收敛的优势,然后切换到SGD,缓慢寻找最优解。
Part3 学习笔记


