1.算法运行效果图预览
(完整程序运行后无水印)
2.算法运行软件版本
matlab2022a/matlab2024b
3.部分核心程序
(完整版代码包含详细中文注释和操作步骤视频)
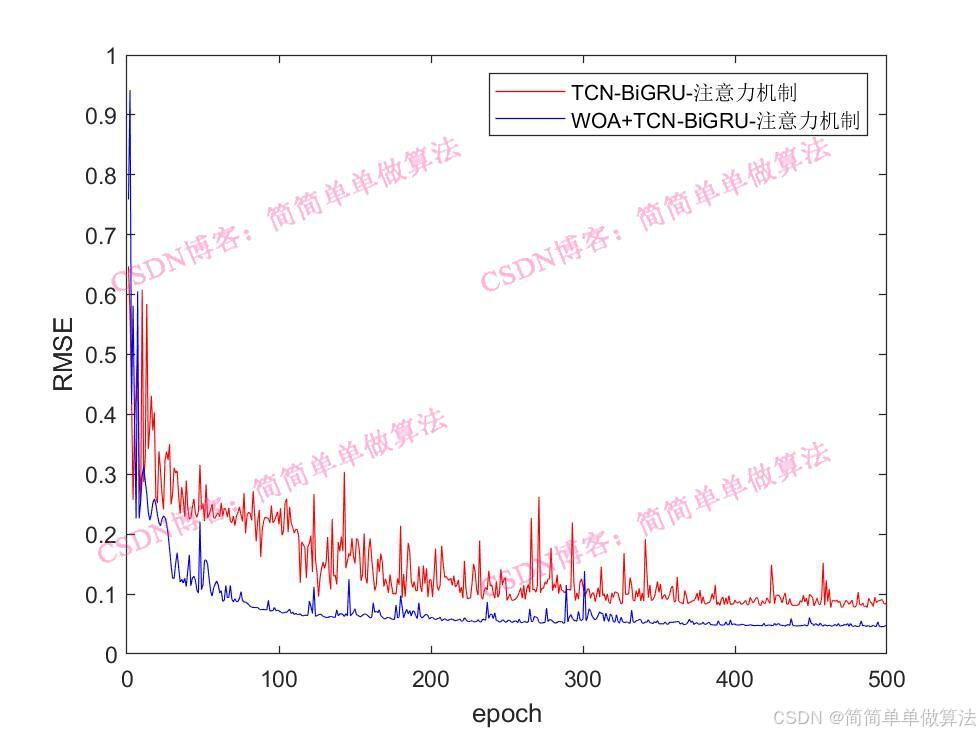
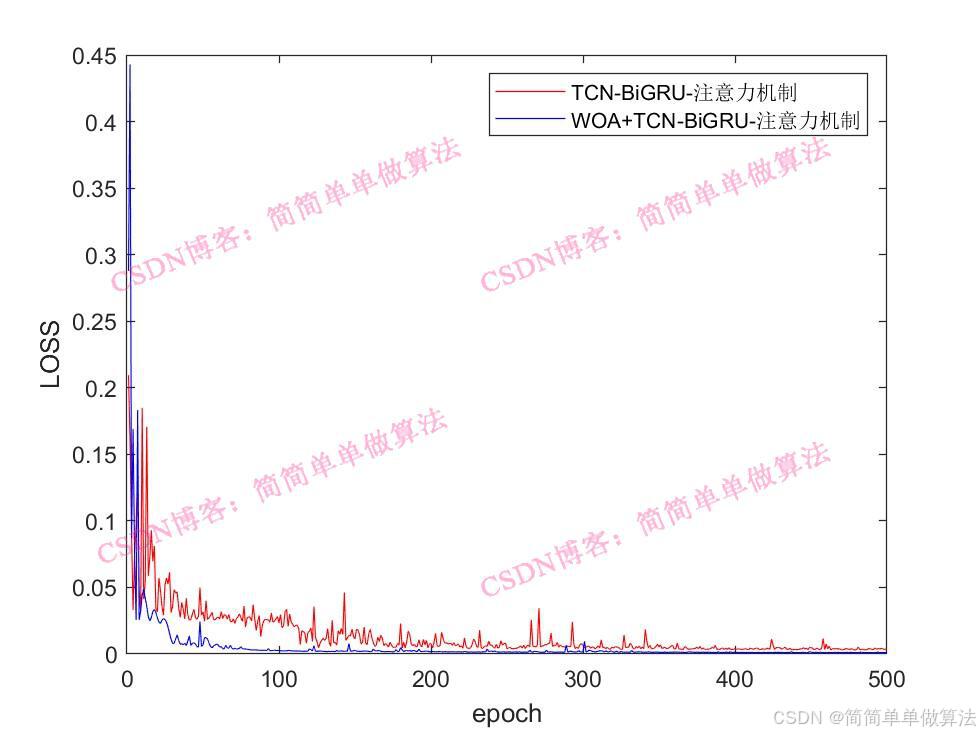
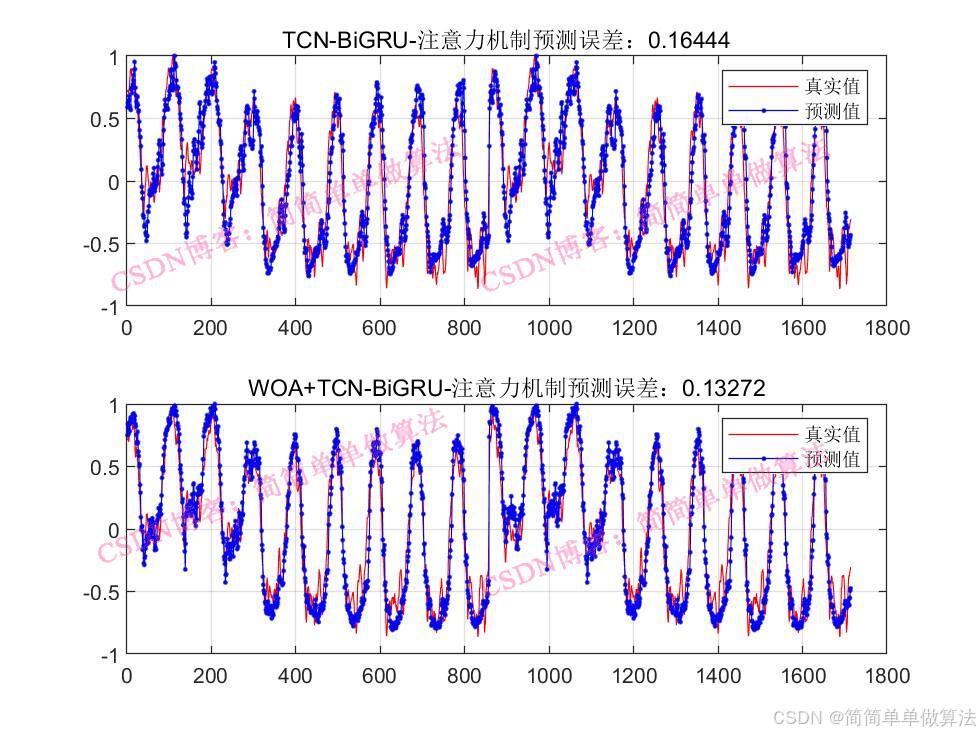
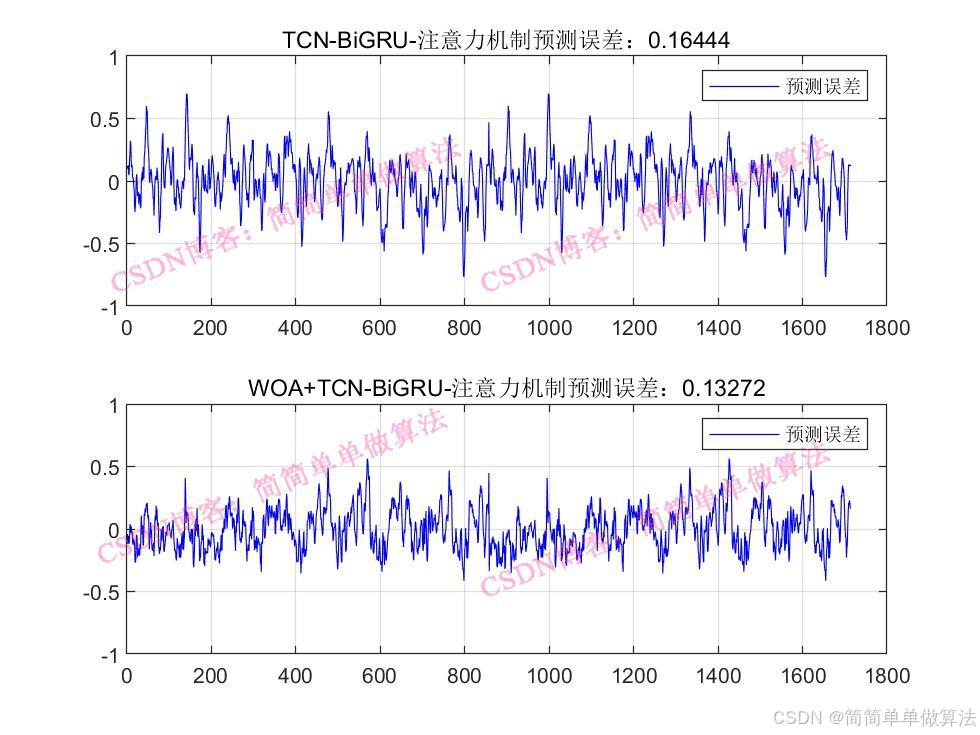
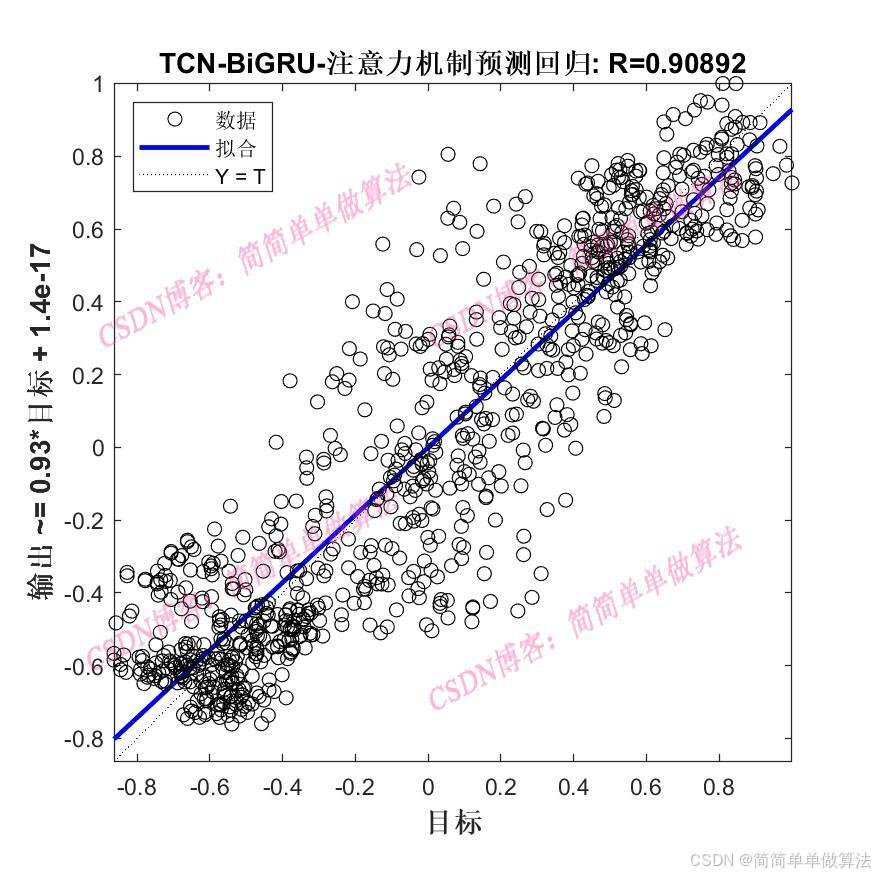
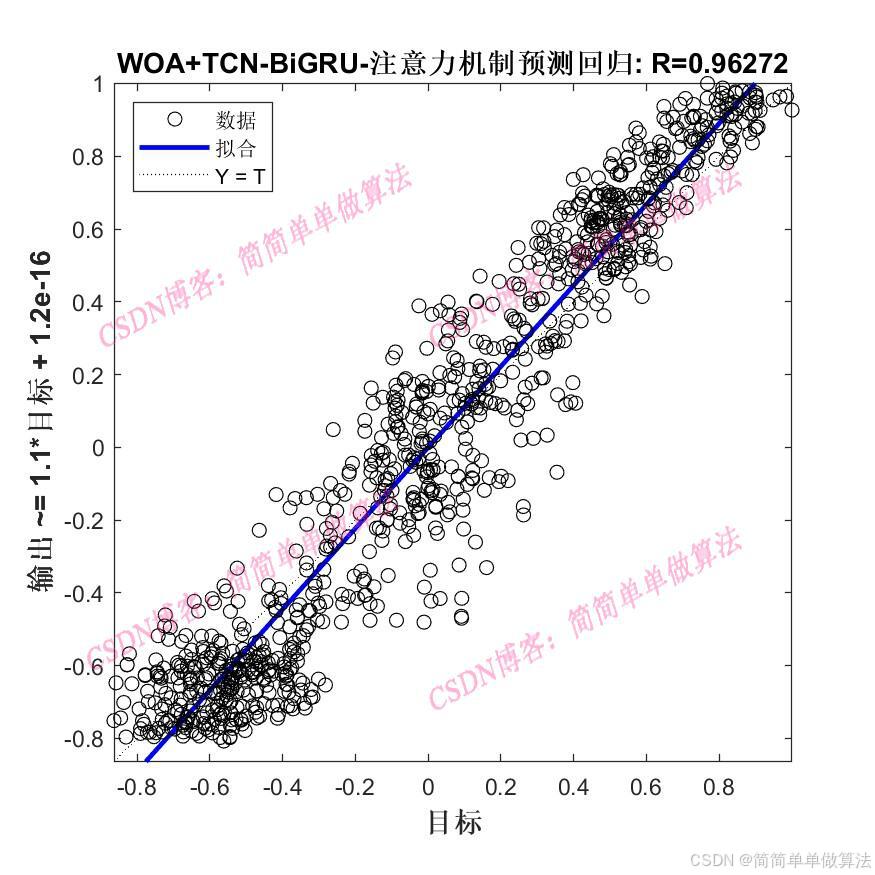
..................................................................%设置网络参数 %卷积核 Nfilter = floor(X(1));%8; %卷积核大小 Sfilter = floor(X(2));%5; %丢失因子 drops = X(3);%0.025; %残差块 Nblocks = floor(X(4));%4; %特征个数 Nfeats = Dims; %设置网络参数 lgraph=func_layers2(Dims,Dimso,X);%参数设置 options = trainingOptions("adam",... 'InitialLearnRate',X(5),... 'MaxEpochs',500,... 'miniBatchSize',2,... 'Plots','training-progress',... 'Verbose', false); %训练 [net,INFO] = trainNetwork(Ptrain_reshape, Ttrain_reshape, lgraph, options);Rerr = INFO.TrainingRMSE; Rlos = INFO.TrainingLoss;figure subplot(211) plot(Rerr) xlabel('迭代次数') ylabel('RMSE') grid onsubplot(212) plot(Rlos) xlabel('迭代次数') ylabel('LOSS') grid on%仿真预测 tmps = predict(net, Ptest_reshape ); T_pred = double(tmps{1, 1}); %反归一化 T_pred =T_pred-mean(T_pred); T_pred =T_pred/max(abs(T_pred)); %反归一化 % T_pred = mapminmax('reverse', T_pred, vmax2); ERR = mean(abs(T_test-T_pred)); ERRfigure plot(T_test, 'b','LineWidth', 1) hold on plot(T_pred, 'r','LineWidth', 1) legend('真实值','预测值') xlabel('预测样本') ylabel('预测结果') grid onfigure plotregression(T_test,T_pred,['回归']);save R2.mat Rerr Rlos T_test T_pred ERR 216
4.算法理论概述
TCN主要由因果卷积层、扩张卷积和残差连接构成。因果卷积保证了模型在时间序列上的因果关系,即当前时刻的输出仅依赖于过去时刻的输入,符合时间序列的特性。扩张卷积通过增加卷积核的间隔来扩大感受野,能以较少的层数捕捉到长距离的时间依赖关系。残差连接则有助于缓解梯度消失问题,加快模型的收敛速度。
GRU是循环神经网络(RNN)的一种改进变体,通过门控机制来控制信息的流动,解决了 RNN中梯度消失的问题。BiGRU则是由前向GRU和后向GRU组成,能够同时从正向和反向两个方向对时间序列进行处理,从而更好地捕捉时间序列中的长期依赖关系和上下文信息。
注意力机制的核心思想是让模型在处理时间序列时,能够自动学习到不同时间步的重要程度,为不同的时间步分配不同的权重,从而突出关键时间步的特征信息,提高模型的预测精度。
在本系统中,根据个体所代表的超参数组合,构建相应的 TCN-BiGRU 注意力机制网络模型。先搭建 TCN 层,确定因果卷积、扩张卷积和残差连接的参数;再搭建 BiGRU 层,设置隐藏单元数量和层数等;最后添加注意力机制层,确定相关权重矩阵等参数。