从零搭建本地RAG知识库,你的文档终于能自己回答问题了!从安装到测试全流程讲解!
**看完你能得到什么:**一个跑在本地的私有RAG知识库,上传文档后可以直接对话提问。全程断网可用,数据不出你的电脑。
这篇文章适合谁
- 有不方便上传到公有云的文档(合同、内部手册、客户资料),想用 AI 检索
- 想在本地 GPU 上跑一个知识库问答系统,不想付费买云端方案
- 已经看过别人的教程但没跑通(这篇针对 RTX 4070 Ti 真实踩坑)
- 想尝试在自己电脑上搭建RAG的朋友
前置条件
| 项目 | 要求 |
|---|---|
| 硬件 | NVIDIA RTX 4070 Ti(12 GB 显存)或类似配置(最低 8 GB 显存) |
| 系统 | WSL2(Ubuntu 22.04)或原生Linux |
| CUDA 版本 | ≥ 11.8,推荐 12.1+ |
| 提前装好 | Git(https://git-scm.com/) |
| 下载量 | 模型约 5 GB(Qwen2.5-7B Q4_K_M) + 1.3 GB(bge-large-zh),建议预留30G SSD空间。 |
| 预计耗时 | 30-上不封顶(要下模型,取决于网速) |
| 难度 | 中等 |
为什么选 Langchain-Chatchat
也想尝试Dify、AnythingLLM、PrivateGPT。但是Dify 太重(Docker + PostgreSQL + Redis 全家桶),AnythingLLM 本地模型问答延迟高。Langchain-Chatchat 是一个纯 Python 项目,在 12 GB 显存上同时跑嵌入模型 + Qwen 量化 LLM,问答延迟不到 2 秒,中文生态也最好(社区全中文,有问题搜得到就好解决)。
架构速览
你的文档(PDF/Word/TXT) │ ▼嵌入模型(bge-large-zh-v1.5,1.3 GB 显存) │ 将文档转成向量 ▼向量数据库(FAISS) │ ▼LLM(Qwen2.5-7B-Instruct Q4_K_M,5 GB 显存) │ 根据检索到的文档片段生成答案 ▼回答显存预算( 12 GB )
| 组件 | 占用 |
|---|---|
| 嵌入模型 bge-large-zh-v1.5 (FP16) | ~1.3 GB |
| LLM Qwen2.5-7B Q4_K_M(Ollama) | ~5 GB |
| FAISS 向量索引(1 万份文档) | ~0.2 GB |
| 剩余给 KV Cache / 上下文 | ~5.5 GB |
| 合计 | 12 GB ✓ 刚好够 |
5.5 GB 的 KV cache 足够支持约 8000-12000 token 的上下文窗口,覆盖绝大多数文档问答场景。如果你的文档单篇超过 3 万字,建议切分后再上传。
环境准备
1 确认 CUDA 可用
nvidia-smi期望正确的输出举例:
+-----------------------------------------------------------------------+| NVIDIA-SMI 560.35.03 Driver Version: 560.35.03 CUDA Version: 12.6 ||---------------------+----------------------+----------------------+| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC || Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. ||========================+======================+======================|| 0 NVIDIA GeForce RTX 4070 Ti | 00000000:01:00.0 On | N/A || 30% 45C P8 9W / 285W | 1689MiB / 12282MiB | 0% Default |+---------------------------+----------------------+----------------------+以我的配置举例,输入指令后得到的反馈:
这里咱们重点关注三个数字:CUDA Version(我的右上角是 13.3)、12282 MiB(确认显存总量)、RTX 4070 Ti(确认显卡型号)。
以下是CUDA 版本要求
| 版本 | 能否使用 | 说明 |
|---|---|---|
| CUDA 12.x(12.1-12.6) | ✅ 推荐 | 完美匹配 PyTorch cu121,零磨合 |
| CUDA 11.8 | ✅ 可用 | 需改用 cu118 版 PyTorch(见下一步),功能无差异 |
| CUDA 11.0-11.7 | ⚠️ 不推荐 | PyTorch 官方已停止为这些版本提供预编译包 |
| 低于 11.0 | ❌ 不可用 | bge-large-zh 和 Qwen 的底层算子需要较新的 CUDA |
nvidia-smi 显示的 CUDA Version 和实际装的 CUDA Toolkit 是两回事:
nvidia-smi 右上角显示的是驱动最高支持版本(比如 12.6);你实际安装的 CUDA Toolkit 版本才是 PyTorch 编译时对标的版本。我们用 PyTorch 预编译包(cu121),不需要手动装 CUDA Toolkit——PyTorch 自带所需的 CUDA 运行时。只要驱动的 CUDA Version ≥ 11.8,你就放心往下走。
Langchain-Chatchat 依赖 GPU 加速——嵌入模型用 CUDA 比 CPU 快 10 倍以上,LLM 推理更是依赖 GPU。如果 nvidia-smi 报错或显存不足,后面所有步骤都是无效的。这一步是全链路的第一道关卡,5 秒钟,省掉后面半小时的盲目操作。
一些报错现象 原因 解决 nvidia-smi: command not found 没装 NVIDIA 驱动,或 WSL 内路径没配 WSL 用户:驱动必须装在 Windows 侧(不是 WSL 里)。去 NVIDIA 官网下载 Windows 版 Game Ready 驱动,安装后在 PowerShell 执行 wsl --shutdown,再重新打开 WSL 有输出但没有 NVIDIA GPU 集成显卡或 AMD 显卡 只有 NVIDIA 显卡才能用 CUDA。AMD 显卡需要用 ROCm,本教程不覆盖 显存 < 8 GB 显存不够同时跑嵌入模型 + LLM ① 嵌入模型用 CPU 跑(改 EMBEDDING_DEVICE = “cpu”,省 1.3 GB)② LLM 换成 Qwen2.5-3B(约 3 GB),但问答质量会下降 驱动版本 < 11.8 驱动太老 去 NVIDIA 官网下载最新驱动覆盖安装
2 安装 Ollama(管理 LLM)
一行命令就可以装上:
curl -fsSL https://ollama.com/install.sh | sh装好后打开就是这个样子:
这里我们有两个模型要管——嵌入模型(bge)和对话模型(Qwen)。嵌入模型很小(1.3 GB),直接用 Python 库加载就行;但 Qwen 7B 的量化版本有 5 GB,手动管理 GGUF 文件 + 配置推理参数很麻烦。Ollama 一行命令下载、一行命令启动服务、统一的 API 接口,比自己折腾 llama.cpp 省一半时间。
现象 解决 curl: command not found sudo apt install curl -y 下载速度极慢 / 连接超时 去 Ollama GitHub Releases 下载 .tar.gz,解压后 sudo mv bin/ollama /usr/local/bin/ 安装成功但ollama命令找不到 新开一个终端,或执行 source ~/.bashrc
安装后验证:
ollama --version得到ollama版本号代表安装成功:
3 创建 Python 虚拟环境
3.1 先进wsl系统:在终端输入wsl(忽视我的那两条报错)
wsl3.2 接着安装virtualenv,安装virtualenv是为了避免直接用python3安装虚拟环境而出现的sudu密码报错,所以我们这里直接用清华源安装virtualenv,然后用virtualenv创建环境
pip3 install --break-system-packages virtualenv -i https://pypi.tuna.tsinghua.edu.cn/simple3.3 用virtualenv创建环境
virtualenv ~/langchain-chatchat-env source ~/langchain-chatchat-env/bin/activate👆环境创建好之后,终端前缀会加上langchain-chatchat-env的字样,就代表虚拟环境配好了。
为什么要单独配一个虚拟环境:
Langchain-Chatchat 依赖十几个 Python 包(torch、transformers、sentence-transformers、faiss、langchain 等),版本之间有严格的兼容关系。如果你在系统 Python 里直接 pip install,很快会跟其他项目的依赖打架。
虚拟环境 = 给这个项目一个独立的小房子。就算里面打得天翻地覆,外面你的系统 Python 和 Hermes 完全不受影响。装坏了删掉重来就是一瞬间的事。
现象 解决 python3: command not found sudo apt install python3 python3-pip -y ensurepip is not available sudo apt install python3-venv -y。如果 sudo 不可用,直接 pip install --break-system-packages(不推荐但能救命) source 后终端前缀没变 确认路径正确:ls ~/langchain-chatchat-env/bin/activate 存在吗?
**怎么知道虚拟环境已激活:**终端前缀会变成 (langchain-chatchat-env)。后面所有 pip install 和 python 命令都必须在这个环境下执行。如果关了终端,重新打开后需要重新执行 source 那行。
4 安装 PyTorch
如果你的CUDA是12.x(12.1-12.6),或更高比如我13.3,那用下面这串指令
pip install "torch>=2.6" torchvision --index-url https://download.pytorch.org/whl/cu121如果你nvidia-smi 的 CUDA Version 是 11.x
把 cu121 改成 cu118:
pip install "torch>=2.6" torchvision --index-url https://download.pytorch.org/whl/cu118输入指令后,就是等:
如果安装过程中出现下图我这种的黄色WARNING提示,并且Read timed out,不用担心,这可能是当时拉取下载时网络波动导致没下载到,会自动尝试重连下载,也就是WARNING后面会紧接着显示Downloading
整个下载过程大概会装20-30个包,大小大概3G。
等了大概10分钟,当看到出现Successfully installed就说明安装成功了。
然后我们验证一下,验证 GPU 可见:
python3 -c "import torch; print(torch.cuda.is_available()); print(torch.cuda.get_device_name(0))"输出True和 你的显卡型号 那就对味了**。**
PyTorch 默认从 PyPI 安装的是 CPU 版本,没有 CUDA 支持。如果装了 CPU 版跑 Langchain-Chatchat,嵌入速度从秒级变成分钟级,LLM 推理直接无法加载到 GPU 上。指定 cu121 索引确保下载的是 CUDA 12.1 编译版本。
一些可能遇到的报错现象 解决 torch.cuda.is_available() 返回 False 最常见:装了 CPU 版 PyTorch。pip list torch.cuda.get_device_name(0) 报错 GPU 序号问题。试试 python3 -c “import torch; print(torch.cuda.device_count())”,如果输出 0,回退到上一步排查驱动 pip 下载慢 加清华源:pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121 -i https://pypi.tuna.tsinghua.edu.cn/simple
5 克隆项目 + 安装依赖code-snippet__js # 克隆项目 git clone https://github.com/chatchat-space/Langchain-Chatchat.git # 进入项目文件,这里的名字必须和你下载的项目名字相同(如果你是在镜像下载名字可能会出现小写) cd Langchain-Chatchat
# 安装依赖,直接用手工安装 # 锁定 langchain 版本(必须!新版 langchain 1.x 不兼容) pip install langchain==0.1.17 langchain-core==0.1.53 langchain-community==0.0.36 \ langchain-openai==0.0.6 langchain-experimental==0.0.58 langchain-text-splitters==0.0.2 \ langsmith==0.1.17 sentence_transformers faiss-cpu PyMuPDF \ -i https://pypi.tuna.tsinghua.edu.cn/simple # 从本地子包安装项目本身 pip install libs/chatchat-server --no-deps -i https://pypi.tuna.tsinghua.edu.cn/simple # 批量补装剩余依赖 pip install htbuilder humanlayer jieba json_repair langchainhub loguru markdownify \ mcp nest_asyncio numexpr opencv-python openpyxl pathlib pyjwt pymysql \ python-docx python-multipart rank_bm25 rapidocr_onnxruntime ruamel_yaml \ streamlit==1.34.0 streamlit-aggrid==1.0.5 streamlit-antd-components==0.3.1 \ streamlit-chatbox==1.1.12.post4 streamlit-extras==0.4.2 streamlit-modal==0.1.0 \ streamlit-option-menu==0.3.12 streamlit-paste-button==0.1.2 strsimpy memoization \ httpx==0.27.2 chardet \ -i https://pypi.tuna.tsinghua.edu.cn/simple#安装项目 如果你的python是3.10-3.11 pip install langchain-chatchat -Ups:
为什么锁死所有版本号:langchain-chatchat 0.3.1.3 基于 langchain 0.1.x 开发,清华源默认装的是不兼容的 1.x。锁版本 = 一劳永逸。
为什么 streamlit 锁 1.34.0:新版移除了 experimental_dialog 等 API,项目 WebUI 依赖它们。
为什么 httpx 锁 0.27.2:新版移除了 proxies 参数,导致 API 通信全部报错。
注意:上方的安装方式适合大多数人,但是如果你的python跟我一样是3.12,由于官方明确表示目前是支持到了3.11,所以我们3.12安装大概率报错。跟我下面的代码进行安装即可。
#手动安装,跳过依赖,因为我们已经装过了 pip install faiss-cpu -i https://pypi.tuna.tsinghua.edu.cn/simple pip install . --no-deps -i https://pypi.tuna.tsinghua.edu.cn/simple装好之后验证一下全部依赖是否都安装上了:
#验证依赖,输出✓ 全部OK就代表安装依赖都成功 python3 -c "import langchain, fastapi, fitz, sentence_transformers; print('✓ 全部OK')"缺什么依赖会告诉你,复制后发给你的Agent,它会给你代码。
装完之后回到项目根目录,以便咱们继续后面的配置:
cd /mnt/c/Users/你的用户名/langchain-chatchat注意,装基础依赖的两次pip顺序不要搞反了;langchain-chatchat 是项目本身包。分开来是为了——如果装到一半报错,你能立刻定位是哪一步出了问题。揉在一起装,报错了根本不知道是谁的锅。
pip install -r requirements.txt这一步如果报错,就直接输入pip install
一些可能遇到的报错现象 解决 第一步克隆项目 git clone 超时 / 连不上 GitHub 建议大家直接用镜像 ① 用镜像:git clone https://ghproxy.com/https://github.com/chatchat-space/Langchain-Chatchat.git ② 去 Gitee 搜 Langchain-Chatchat 搬运仓库,我搜到的是:git clone https://gitee.com/mirrors/langchain-chatchat.git faiss-gpu 装不上 直接装 CPU 版:pip install faiss-cpu,然后编辑 requirements.txt 删掉 faiss-gpu 那行 externally-managed-environment 确认虚拟环境已激活。如果已激活还报错,加 --break-system-packages 参数 版本冲突(如 numpy) 先 pip install -r requirements.txt,看具体哪个包报错,手动指定兼容版本
下载模型
两个模型需要分别下载:嵌入模型(向量化文档)和 LLM(生成回答)。它们在系统里的角色完全不同。
嵌入模型:BAAI/bge-large-zh-v1.5
python3 -c "from sentence_transformers import SentenceTransformer; SentenceTransformer('BAAI/bge-large-zh-v1.5')"这里我直接用的镜像版,在下面“一些可能遇到的报错现象”板块复制我的这串镜像代码。
| 项目 | 数值 |
|---|---|
| 大小 | 1.3 GB(FP16) |
| 中文效果 | 在 C-MTEB 中文基准上排名前列 |
| 最大输入长度 | 512 token |
嵌入模型 = 图书管理员,负责把书分类上架;LLM = 学者,负责根据找到的书回答问题。你不能让学者同时管理图书馆。
**为什么是 bge-large-zh-v1.5:**BAAI(北京智源)出品,C-MTEB 中文检索任务常年第一。large 版本虽然 1.3 GB,但检索精度比 base 版本高出一截。在 12 GB 显存里,多花 1 GB 换更高的召回率完全值得——检索质量是知识库问答的天花板。
一些可能遇到的报错现象 解决 下载极慢(国内直连慢) export HF_ENDPOINT=https://hf-mirror.com 然后重新运行 也可以直接用这个: code-snippet__js HF_ENDPOINT=https://hf-mirror.com python3 -c "from sentence_transformers import SentenceTransformer; SentenceTransformer('BAAI/bge-large-zh-v1.5')"sentence_transformers 模块找不到 pip install sentence-transformers 下载到一半断了 模型缓存在 ~/.cache/huggingface/hub/,重新运行会断点续传。若混用了直连和镜像,删掉缓存重试
LLM:Qwen2.5-7B-Instruct(Q4_K_M 量化)
ollama pull qwen2.5:7b-instruct-q4_K_M| 项目 | 数值 |
|---|---|
| 大小 | ~5 GB |
| 量化方式 | Q4_K_M(4-bit,中等质量) |
| 中文能力 | 原生中文模型,中文问答效果极佳 |
为什么选 7B 而不是 3B 或 14B:
•3B:太小,知识面窄,复杂问题容易胡说。省下来的显存做不了别的事。
•14B:太大,量化后 8 GB,加上嵌入模型只剩不到 3 GB 给上下文。
•7B:刚好。Q4_K_M 量化后 5 GB,中文问答效果足够好,显存还剩 5.5 GB 给上下文。**为什么用 Q4_K_M:**Qwen2.5-7B 原始 BF16 是 14 GB,一张卡装不下。Q4_K_M 是 llama.cpp 团队调出来的 4-bit 甜点——比 Q5 省 2 GB,比 Q3 质量明显更好。实测几乎感觉不到和完整精度的区别。
**为什么用 Ollama:**集成 llama.cpp,自动处理量化加载、显存管理。你用 transformers 要手动写 20 行加载代码;Ollama 一行命令搞定,并提供了标准 OpenAI 兼容 API。
现象 解决 ollama: command not found Ollama 没装上。重新执行第 2 步 下载速度极慢 Ollama 注册表在国内直连可能慢。设置代理或手动下载 GGUF 后导入 显存不足警告 nvidia-smi 检查是否有其他程序占用显存
验证模型加载成功
# 测试嵌入模型HF_HUB_OFFLINE=1 python3 -c "from sentence_transformers import SentenceTransformerm = SentenceTransformer('BAAI/bge-large-zh-v1.5')print('嵌入模型加载成功, 输出维度:', m.encode('测试').shape)"# 测试 LLMollama run qwen2.5:7b-instruct-q4_K_M "你好,1+1等于几?"正确输出:
嵌入模型 → 嵌入模型加载成功, 输出维度: (1, 1024)
LLM → 你好!1+1等于2。
安装和下载都是异步的——你敲了命令,不代表东西真的对了。花 30 秒在这里验证,省掉后面排查 10 分钟。
另外,敲了验证代码请耐心等待,加载模型需要一定时间(超过5min就别等了问AI)。
配置
初始化配置
# 进入子包目录(新版是 monorepo 结构)cd libs/chatchat-server# 创建所需目录(新版不会自动创建)mkdir -p data/knowledge_base data/media data/temp data/logs# 初始化知识库python3 chatchat/init_database.py --recreate-vs新版没有 copy_config_example.py了,首次启动时配置自动生成,data目录需要手动创建,缺少任一目录启动都会报错。
需要修改的配置项
配置文件在data/basic_settings.yaml(首次启动后自动生成)。若使用默认 Ollama 配置则无需修改——项目会自动检测 Ollama 中的模型。如需手动配置:
# ========== LLM 配置 ==========LLM_MODELS = ["qwen2.5:7b-instruct-q4_K_M"]OLLAMA_API_BASE = "http://localhost:11434/v1"# ========== 嵌入模型配置 ==========EMBEDDING_MODEL = "BAAI/bge-large-zh-v1.5"EMBEDDING_DEVICE = "cuda"# ========== 向量库配置 ==========VECTOR_STORE = "faiss"VECTOR_STORE_PATH = "./knowledge_base"# ========== 文本分割配置 ==========CHUNK_SIZE = 500 # 每个文本块最大 token 数CHUNK_OVERLAP = 50 # 相邻块重叠 token 数| 参数 | 含义 | 建议值 | 为什么 |
|---|---|---|---|
| LLM_MODELS | 使用的对话模型 | qwen2.5:7b-instruct-q4_K_M | 12 GB 显存最佳选择,中文效果和显存占用的平衡点 |
| OLLAMA_API_BASE | Ollama 服务地址 | http://localhost:11434/v1 | 末尾 /v1 不能丢——这是 OpenAI 兼容接口的前缀 |
| EMBEDDING_MODEL | 向量化模型 | bge-large-zh-v1.5 | 中文检索精度最高的开源嵌入模型之一 |
| EMBEDDING_DEVICE | 嵌入模型运行设备 | cuda | 用 CPU 嵌入一份 500 页 PDF 需要几分钟;用 GPU 需要几十秒 |
| CHUNK_SIZE | 文本分块大小 | 500 | 太小语义断裂,太大检索不准。500 是甜点 |
| CHUNK_OVERLAP | 相邻块重叠量 | 50 | 防止关键信息恰好落在块边界被截断 |
| VECTOR_STORE | 向量数据库 | faiss | Meta 出品,纯 CPU,个人知识库最快最省事 |
启动 #终于要启动了
# 确保在子包目录下cd libs/chatchat-server# Windows 版 Ollama 用户在 WSL 里这样调"/mnt/c/Users/<用户名>/AppData/Local/Programs/Ollama/ollama.exe" serve &# 等 2 秒sleep 2# 启动python3 chatchat/startup.py -a**为什么先 ollama serve &:**Ollama 不是开机自启。如果没在跑,会报 connection refused。
**为什么 sleep 2:**ollama serve & 是异步的,2 秒让它初始化完。
**为什么 & 放到后台:**不加 & 会占据终端不返还。
**为什么 -a:**启动全部服务(API + WebUI)。不加只启动一个。
启动成功后显示:
浏览器打开http://localhost:8501(也可能是http://0.0.0.0:8501**)**,进入 Web 界面。
现象 解决 ModuleNotFoundError 虚拟环境没激活或依赖没装全。重新 source 激活环境,再 pip install -r requirements.txt Connection refused Ollama 没启动。手动 ollama serve 在前台跑一次看日志 启动卡住不动 第一次要加载两个模型到显存,正常需 30-60 秒。超过 2 分钟用 nvidia-smi 看显存 端口被占用 lsof -i :8501 找到 PID,kill -9 后重试 WSL 用户 localhost 打不开 ip addr show eth0 找 WSL IP,用那个 IP 替代 localhost
上传文档并测试 #先快速拿到结果增长信心
准备测试文档
用你自己的文档做测试。如果没有,先用一段文本试试:创建 test.txt,最好是写一段你擅长的领域知识,我是让Hermes直接出了个md格式的测试数据集,比如(下文为部分片段):
Hermes 采用声明式工具定义,每个工具包括三个核心属性: ```yaml tool: name: "terminal" description: "Execute shell commands on Linux environment" parameters: - name: "command" type: "string" required: true - name: "timeout" type: "integer" default: 180工具的调用流程为:用户输入 → Gateway 解析 → 匹配工具 → 生成 tool_call → 执行 → 结果注入上下文 → 模型生成回复。
> 大家尽量用自己熟悉的文档测试——AI 答错了你才能立刻判断。第一轮测试决定你对这个工具的信心。 ### 上传到知识库 1. WebUI → 知识库管理 → 新建知识库,填好名称、简介 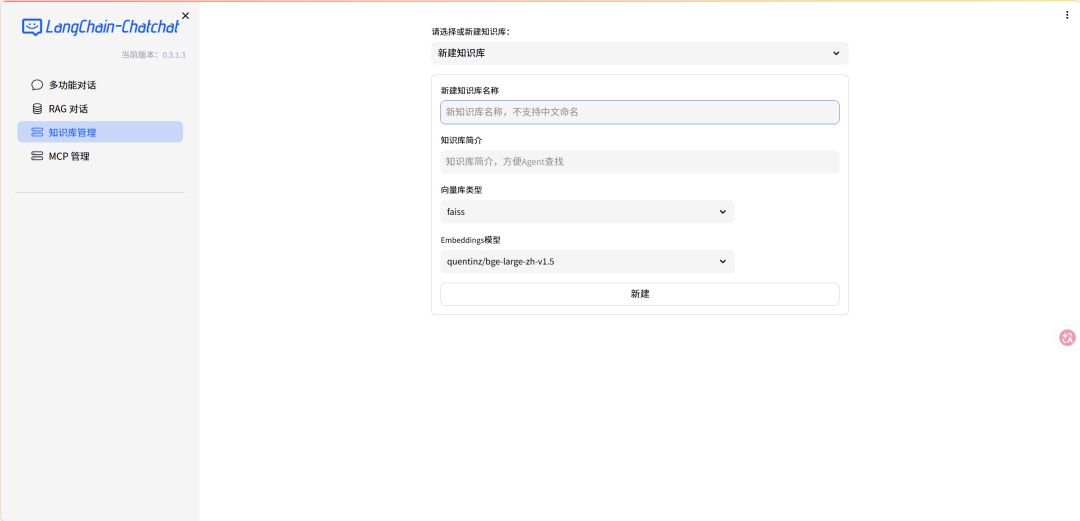 2. 上传知识 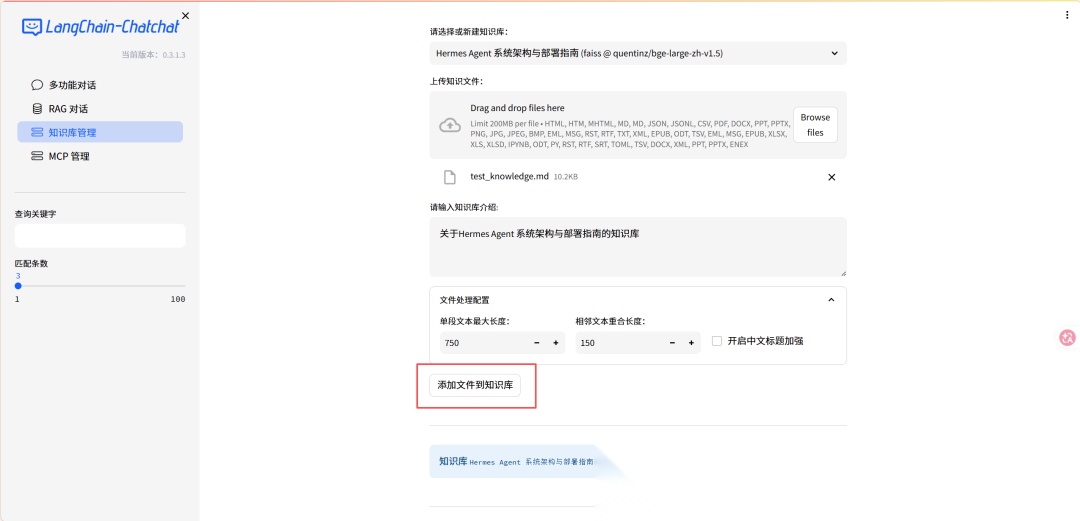 3. 看到文档内容被正确分割成片段,就代表导入成功 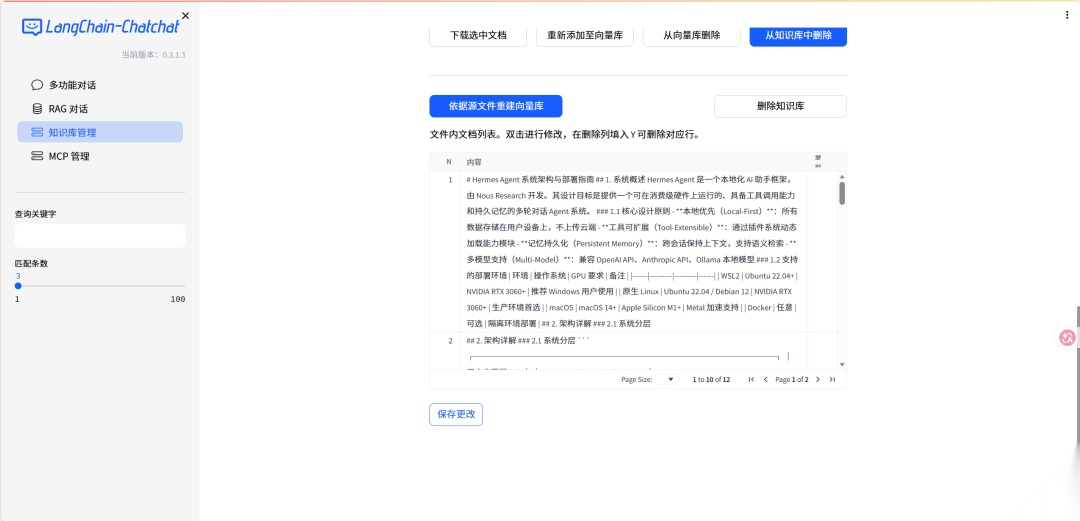 ### 测试问答 在对话界面选择刚才创建的知识库 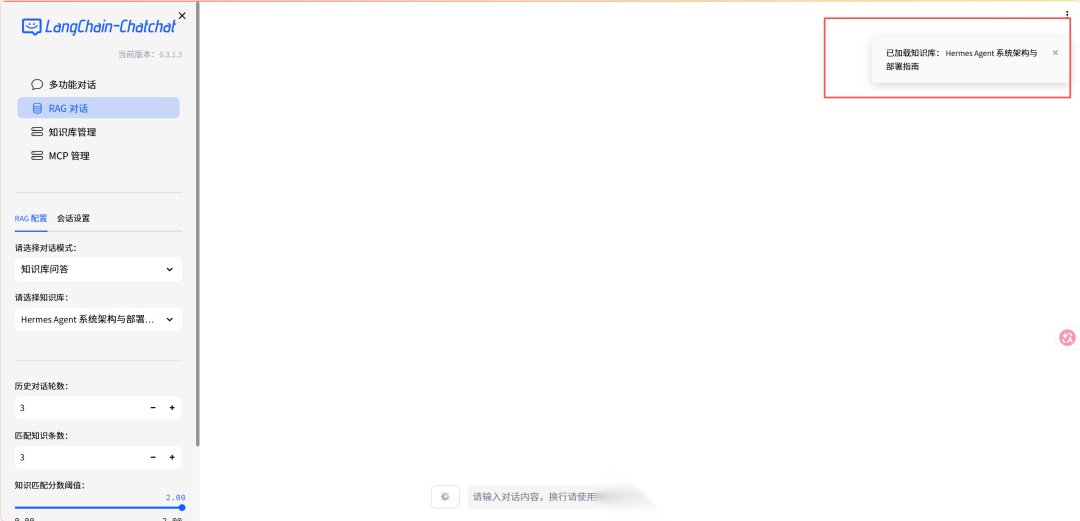 提问1: ```plaintext Hermes Agent的核心调度器叫什么?它负责哪些职责?可以看到匹配到了知识库的内容并引用了来源
**正确回答:**回答 Gateway,列出消息路由/工具调度/模型选择/上下文管理。
提问2:
bge-large-zh-v1.5的输出维度是多少?中文MTEB排名第几?索引正确。
回答正确**:1024 维,#1**
知识库问答最大的风险是 LLM 胡说八道。来源引用让你能追溯到原始文档——没有来源引用的回答,默认当它不存在。
现象 原因 解决 回答完全不对,无来源引用 知识库没选对,或向量化没完成 确认对话界面选了正确知识库。回知识库管理检查向量化状态 回答大方向对但细节有误 LLM 幻觉——没检索到精确片段 把 CHUNK_SIZE 调小(如 300),让检索更细 回答像通用聊天 检索没召回内容 提问改得更精确,直接引用文档里的关键短语
常见问题速查
| 问题 | 解决 | 根因 |
|---|---|---|
| nvidia-smi 不显示 CUDA 版本 | WSL 内需安装 Windows 端的 NVIDIA 驱动 | WSL 的 GPU 驱动在 Windows 侧 |
| Ollama connection refused | 先执行 ollama serve | Ollama 是手动启动的 |
| 嵌入模型下载极慢 | export HF_ENDPOINT=https://hf-mirror.com | HuggingFace 国内直连慢 |
| CUDA out of memory | 关闭其他占用显存的程序 / 调小 CHUNK_SIZE / 换更小 LLM | 显存被占用 |
| faiss 安装失败 | pip install faiss-cpu | faiss-gpu 依赖特定 CUDA 版本 |
以上,整体就算搭建完成了,如果你跟着我的教程做,也难免会遇到很多报错的地方,请放宽心态,多和Agent对话,或者直接后台私聊我,我看到了都会第一时间帮你们解决,后面也整理了一份踩坑实录以及完整依赖清单,希望可以帮到大家。
这个工具在我的 AI 链里放在哪
Hermes 负责执行任务,Obsidian 负责记笔记,Langchain-Chatchat 负责检索我的知识库。三个工具串起来:知识库查到的东西 → 喂给 Hermes → 结果写进 Obsidian。
下一篇预告
把 Langchain-Chatchat 的知识库接进 Hermes,让 AI 助手直接检索你的私有文档来回答问题。你会发现——你不需要记住任何东西,因为你的 AI 链已经帮你记好了。
踩坑记录
以下是我从零搭建 Langchain-Chatchat 过程中踩过的所有坑。RTX 4070 Ti + Python 3.12 + 国内网络环境实录。
坑 1:python3 -m venv 报 ensurepip is not available
**现象:**创建虚拟环境时报错需要 apt install python3-venv,但 sudo 需要密码。
**解决:**用 virtualenv 替代——pip install virtualenv && virtualenv ~/langchain-chatchat-env。功能完全相同,不需要 sudo。
坑 2:GitHub git clone 超时或速度慢如蜗牛跑马拉松
**现象:**Receiving objects 极慢,最终 RPC failed: Connection timed out。
**解决:**用 Gitee 官方镜像 git clone https://gitee.com/mirrors/langchain-chatchat.git,速度可达 8 MiB/s。
坑 3:pip install langchain-chatchat 报 Python 3.12 不支持
**现象:**所有版本都标记了 !=3.12.*,pip 拒绝安装。
**解决:**从本地子包源安装,绕过 PyPI 版本检查——cd libs/chatchat-server && pip install . --no-deps。
坑 4:poetry 依赖解析卡死
**现象:**poetry install 永远停在 “Finding the necessary packages for the current system”。
**解决:**放弃 poetry,手工用 pip + 清华源逐组装依赖。
坑 5:langchain 版本地狱
**现象:**反复出现 ModuleNotFoundError: langchain_core.pydantic_v1、AttributeError: experimental_dialog、TypeError: proxies 等错误。
**原因:**langchain-chatchat 0.3.1.3 基于 langchain 0.1.x 开发,清华源默认装 1.x,大版本 API 不兼容。
**解决:**锁死版本:langchain 系列 → 0.1.x、streamlit → 1.34.0、httpx → 0.27.2。
坑 6:HuggingFace 模型下载被墙
**现象:**Network is unreachable,即使模型已下载到本地,加载时仍超时。
**解决:**永久方案——echo ‘export HF_ENDPOINT=https://hf-mirror.com’ >> ~/.bashrc。离线模式——HF_HUB_OFFLINE=1 python3 -c “…”。
坑 7:torch 版本过低导致模型加载失败
**现象:**ValueError: upgrade torch to at least v2.6。
**解决:**pip install torch --upgrade。
ps:教程的安装代码已帮你们排雷,已限制只安装torch>=2.6的版本
坑 8:WSL 里找不到 Ollama
**现象:**Command ‘ollama’ not found。
**解决:**建别名指向 Windows 版——alias ollama=“/mnt/c/Users/<用户名>/AppData/Local/Programs/Ollama/ollama.exe”。
坑 9:faiss-cpu 版本约束太死
**现象:**要求 faiss-cpu<1.8.0,但清华源最低只有 1.8.0。
**解决:**先 pip install faiss-cpu 装最新版,再用 --no-deps 跳过校验。
坑 10:启动时缺少 data 子目录
**现象:**RuntimeError: Directory data/media does not exist / sqlite3 unable to open database file。
**解决:**mkdir -p data/knowledge_base data/media data/temp data/logs 一次性全建好。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋
📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~