)
基于模型增强的无模型强化学习(Model-based Augmented Model-free RL)
(Dyna-Q, I2A)
Dyna-Q 算法
在学习到环境模型之后,可以利用该模型增强无模型算法。
无模型算法(如 Q-learning)可从以下两种类型的转移样本中学习:
- 真实经验(real experience):来自与环境的实际交互;
- 模拟经验(simulated experience):由模型生成的虚拟转移。
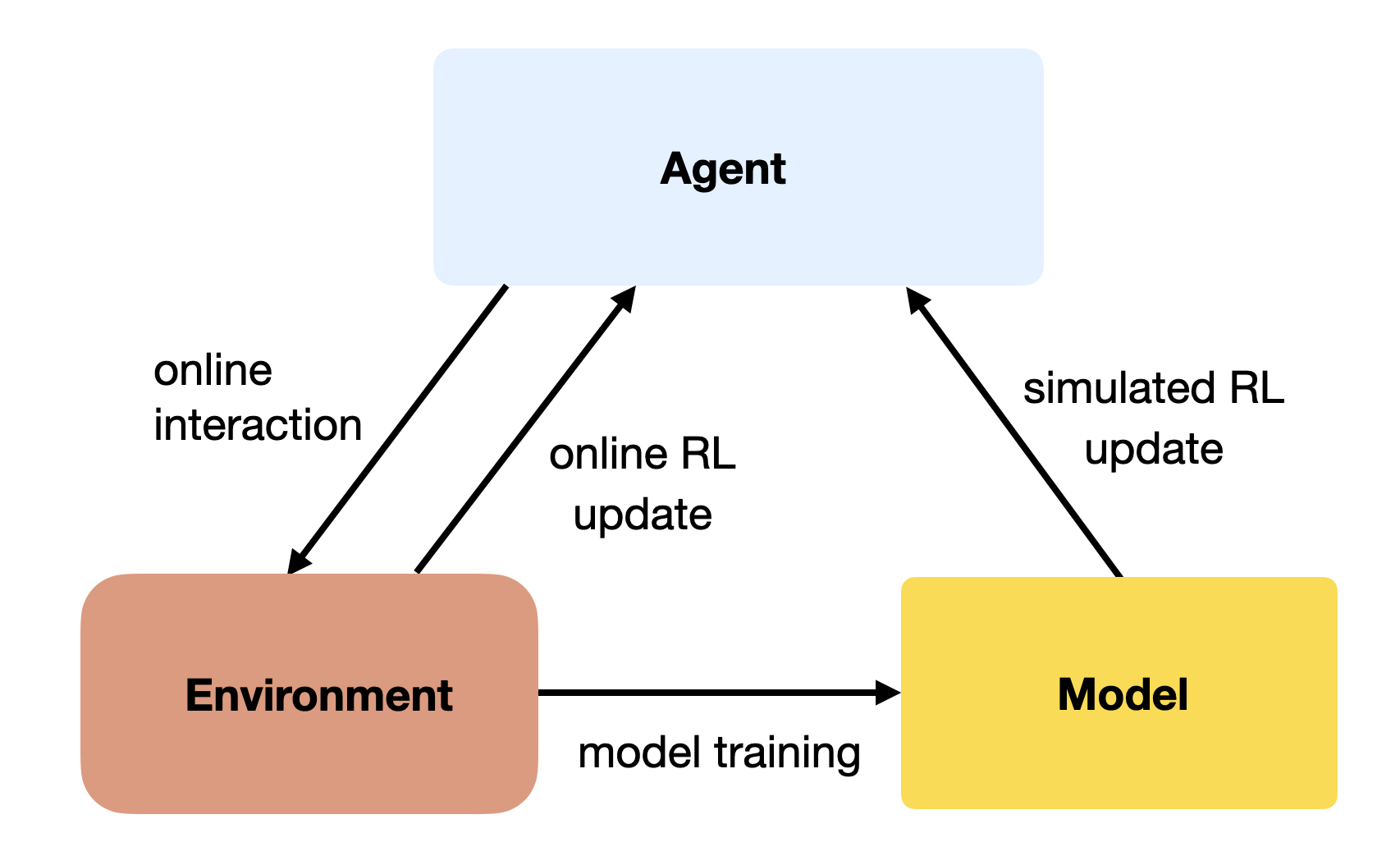
只要模拟转移足够逼真,Q-learning 就能在使用更少真实样本的情况下收敛,从而降低样本复杂度。
Dyna-Q 算法 [@Sutton1990] 是对 Q-learning 的扩展,它集成了环境模型 \(M(s,a)=(s',r')\),在真实环境更新与模型生成更新之间交替进行。
Dyna-Q 算法流程 [@Sutton1990]
- 初始化 Q 值表 \(Q(s,a)\) 和模型 \(M(s,a)\)。
- 对每个时间步 \(t = 1 \ldots T_\text{total}\):
- 使用当前 Q 值选择动作 \(a_t\),在真实环境中执行;
- 观察到 \(s_{t+1}\) 和 \(r_{t+1}\);
- 更新真实样本对应的 Q 值:\[\Delta Q(s_t,a_t) = \alpha (r_{t+1} + \gamma \max_a Q(s_{t+1},a) - Q(s_t,a_t)) \]
- 更新模型:\[M(s_t,a_t) \leftarrow (s_{t+1},r_{t+1}) \]
- 进行 K 次虚拟更新:
- 从已访问的状态集合中随机采样 \(s_k\);
- 使用 \(Q\) 选择动作 \(a_k\);
- 用模型预测 \(s_{k+1}, r_{k+1} = M(s_k,a_k)\);
- 更新虚拟样本对应的 Q 值:\[\Delta Q(s_k,a_k) = \alpha (r_{k+1} + \gamma \max_a Q(s_{k+1},a) - Q(s_k,a_k)) \]
关系与启发
Dyna-Q 是 DQN 和其经验回放机制(Experience Replay)的重要启发来源:
| 方法 | 样本来源 |
|---|---|
| DQN | 复用真实历史样本(ERM) |
| Dyna-Q | 模型生成的虚拟样本 |
此外,Dyna-Q 的交替 on-policy / off-policy 更新思想也是 ACER(第 @sec-acer 节)的核心机制。
I2A:Imagination-Augmented Agents
I2A(Imagination-Augmented Agents)[@Weber2017] 是一种 基于模型增强的无模型方法:
它使用模型生成的虚拟轨迹(rollouts)来辅助无模型算法(A3C)的学习。
研究者在经典益智游戏 Sokoban 中展示了该算法的能力。
Sokoban 需要移动箱子到指定位置,但动作不可逆,且奖励稀疏,是对探索能力极具挑战的任务。
1. 环境模型(Environment Model)
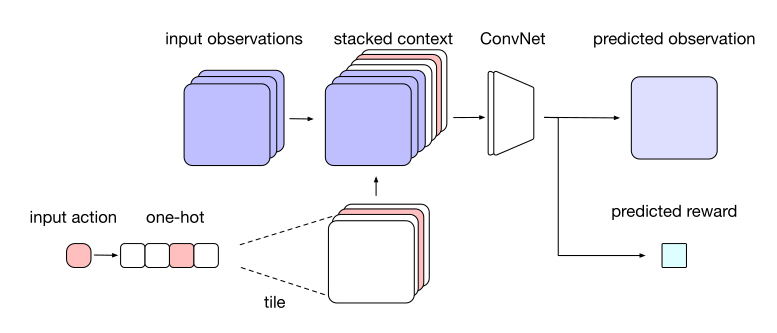
环境模型学习从最近 4 帧观测和当前动作预测下一帧与奖励:
由于 Sokoban 是部分可观测环境(POMDP),使用观测 \(o_t\) 替代状态 \(s_t\)。
该模型结构类似卷积自编码器(CNN autoencoder),输入包含图像和动作,输出为下一帧预测。
实际属于分割网络(如 SegNet [@Badrinarayanan2016] 或 U-Net [@Ronneberger2015])家族。
模型可先用随机策略预训练,再在训练过程中微调。
2. 想象核心(Imagination Core)
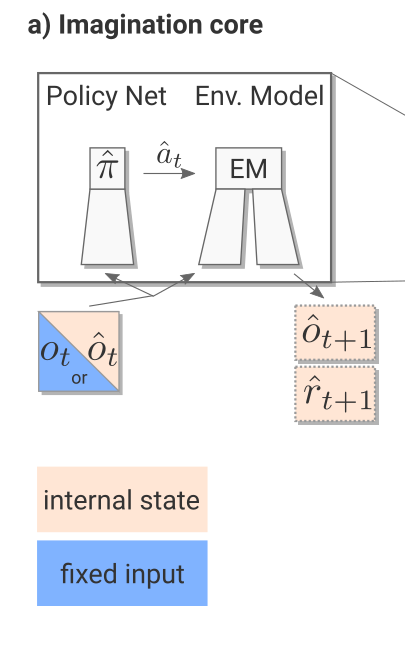
“想象核心”由两部分组成:
- 环境模型 \(M(s,a)\);
- 虚拟策略(rollout policy) \(\hat{\pi}\)。
\(\hat{\pi}\) 用于快速生成虚拟轨迹,可为:
- 预训练的 A3C 策略;
- 简化的近似策略;
- 甚至随机策略。
在 I2A 中,\(\hat{\pi}\) 通过策略蒸馏(policy distillation)从主策略 \(\pi\) 中学习得到。
策略蒸馏(Policy Distillation)[@Rusu2016]
小型网络 \(\hat{\pi}\) 通过监督学习模仿教师策略 \(\pi\) 的输出:
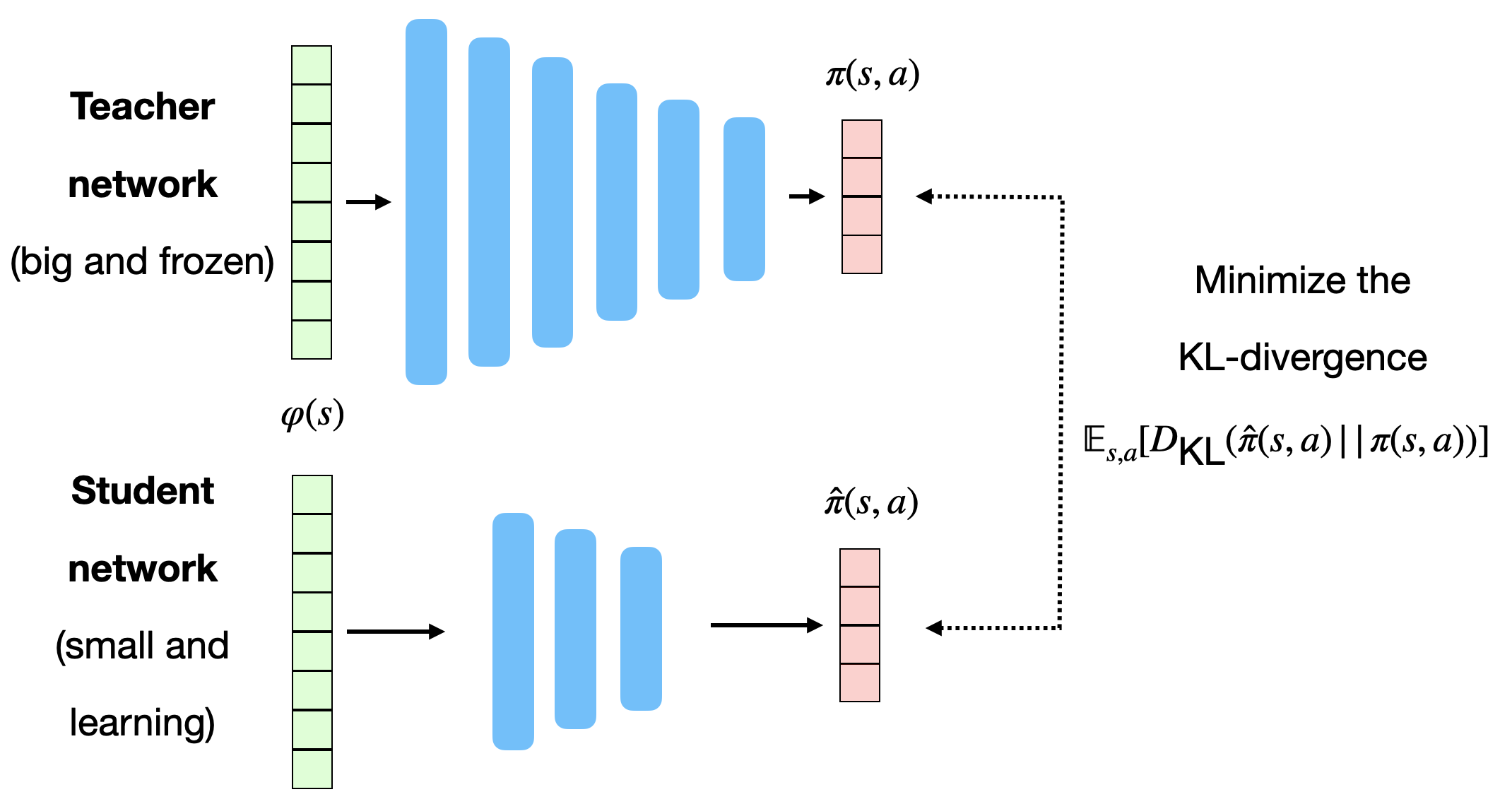
优点:
- 蒸馏后的 \(\hat{\pi}\) 参数更少,计算更快;
- 监督学习比强化学习更易收敛;
- 通常可在保持性能的同时减少 90% 参数量。
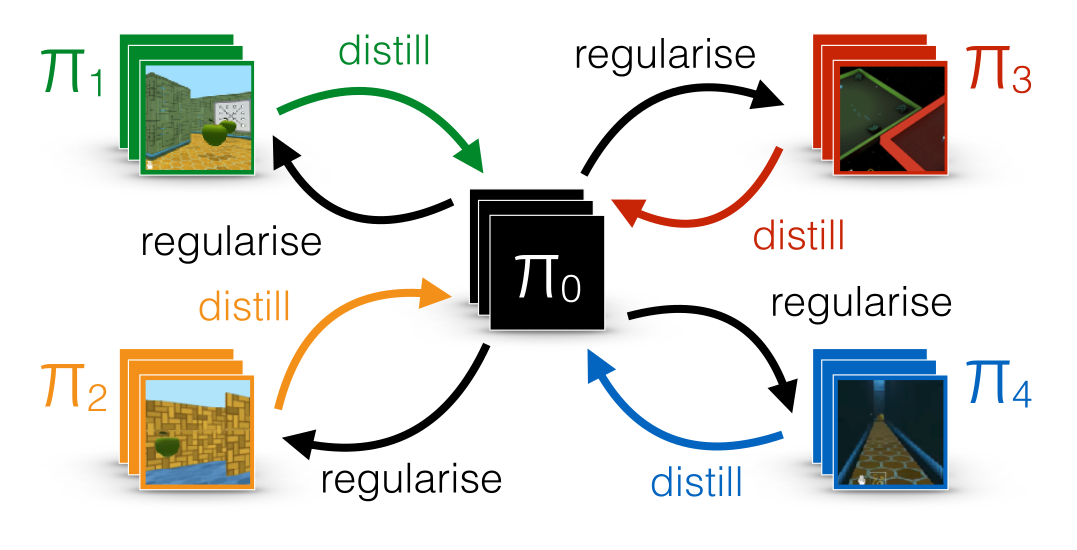
此思想还可扩展为 Distral 框架 [@Teh2017],即多个任务间共享“中心策略”以提升泛化:
3. 想象展开模块(Imagination Rollout Module)

该模块利用想象核心迭代预测未来 \(\tau\) 步:
生成的图像序列与奖励被送入一个 卷积 LSTM,从末帧反向传播至首帧,提取整个虚拟轨迹的嵌入向量 \(e_i\)。
由于 \(\hat{\pi}\) 为随机策略,不同 rollouts 会产生不同嵌入,体现了想象中的多样性。
4. 无模型路径(Model-free Path)
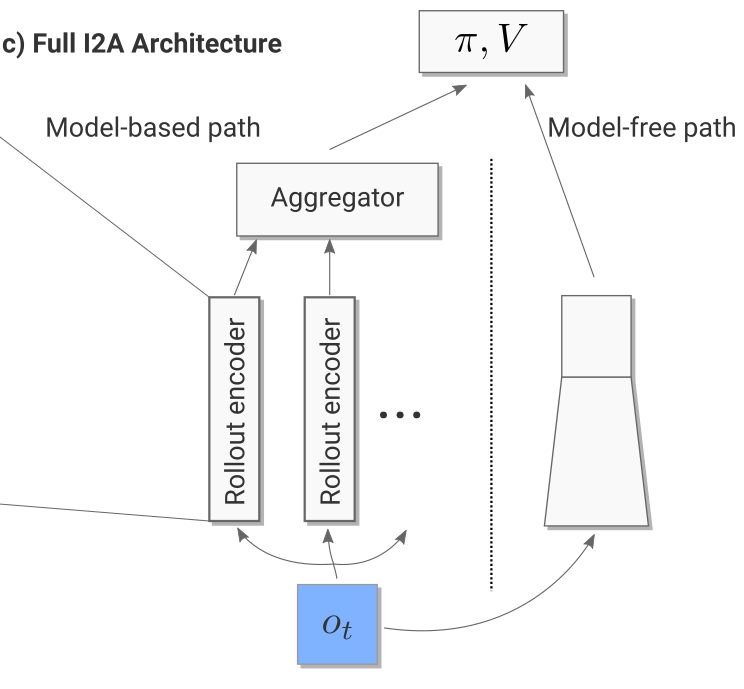
对当前观测 \(o_t\)(及前三帧),为每个可能动作生成一个 rollout(Sokoban 中共 5 个动作):
- 如果执行动作 1,会怎样?
- 如果执行动作 2,会怎样?
- ……
这些 rollouts 的向量嵌入与无模型 CNN 提取的特征拼接,作为联合输入。
5. 完整结构
最终得到一个端到端可微分的整体网络:
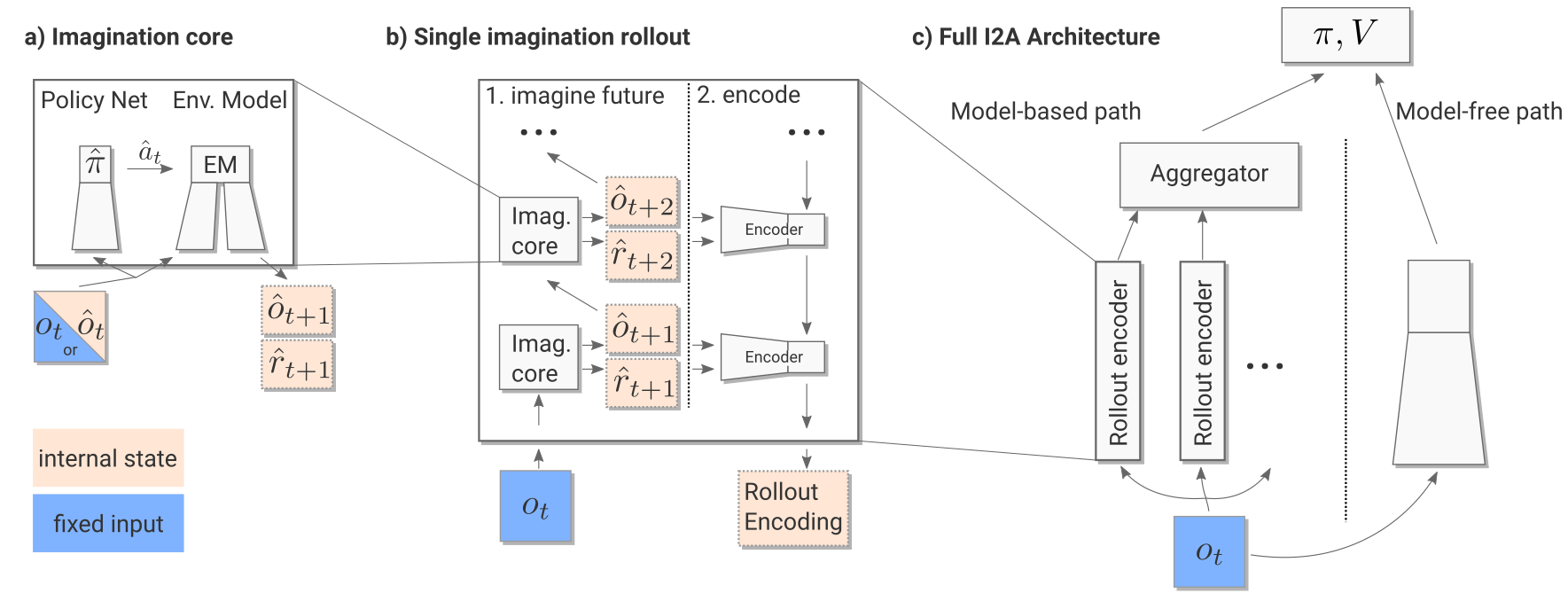
输入:观测 \(o_t\)
输出:策略 \(\pi_\theta\) 与价值函数 \(V_\varphi\)
训练方式:使用 n-step A3C 优化目标。
模型端到端可微分,因此可通过反向传播训练。
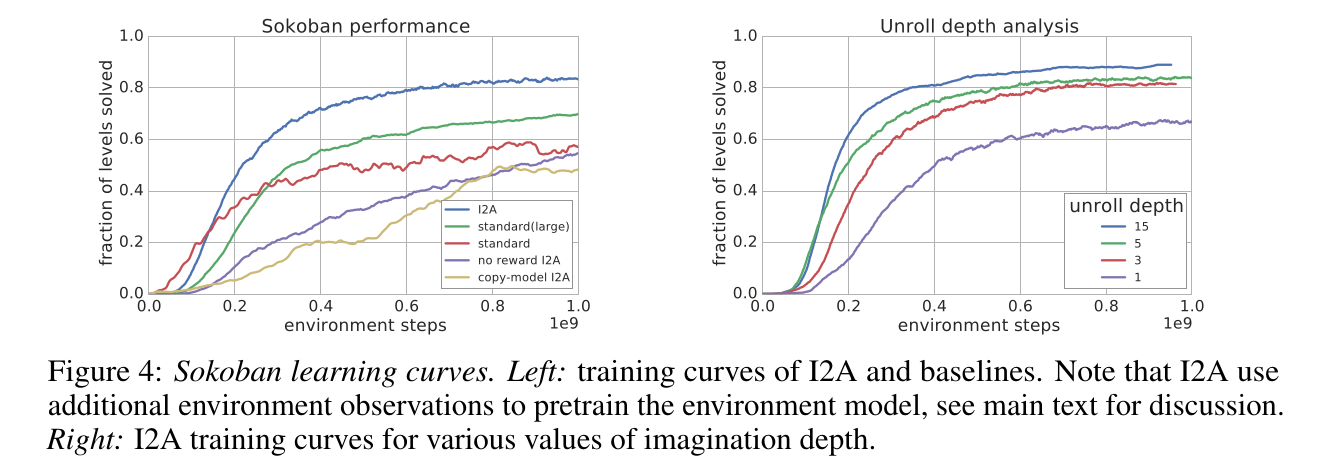
6. 实验结果
I2A 在 Sokoban 上显著优于 A3C:
Rollout 越深(即想象步数越多),性能越好。
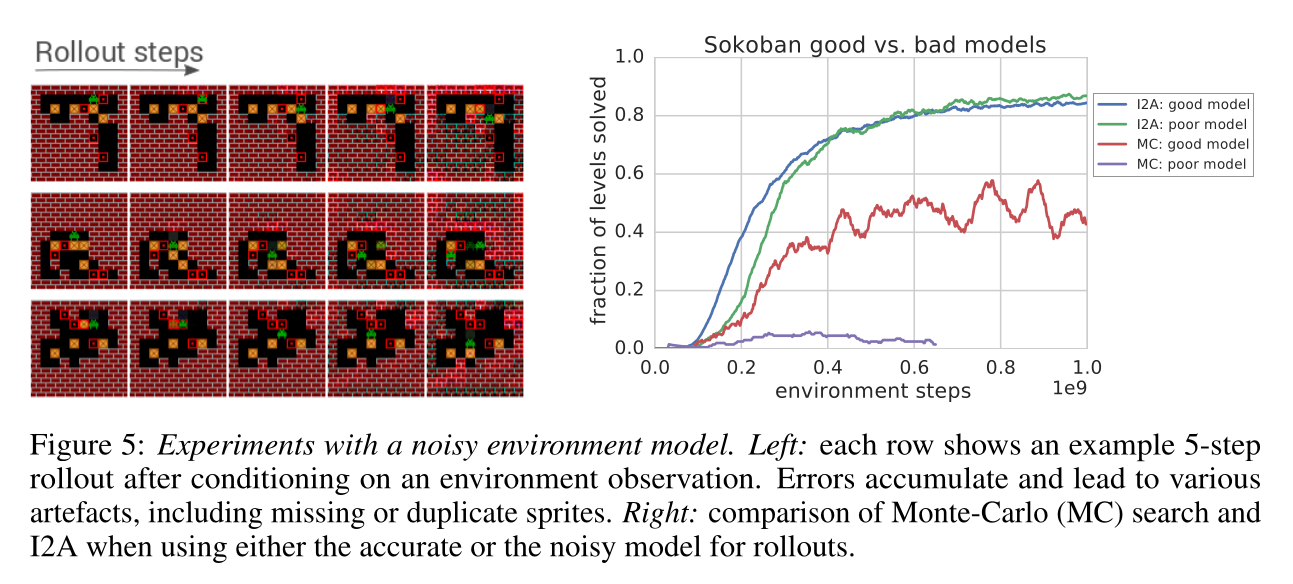
即使模型存在误差,A3C 的无模型分支仍能进行补偿,保持鲁棒性:
总结:
I2A 将基于模型的“规划”引入基于值的深度强化学习中,
通过在“想象环境”中进行多步预测,显著提升了策略的探索性与样本利用率。
其思想为后续如 Dreamer、PlaNet、MBPO 等算法奠定了基础。