for batch_prompt in prompt_dataset:batch_response = active_model.generate(batch_prompt)batch_data = concat(batch_prompt, batch_response)batch_scores = reward_model(batch_data)batch_all_probs, batch_probs, batch_all_values = active_model.forward_pass(batch_data)ref_all_probs, ref_probs, ref_all_values = ref_model.forward_pass(batch_data)kls = compute_KL(batch_all_probs, ref_all_probs)rewards = compute_rewards(batch_scores, kls)advantages = compute_advantages(batch_all_values, rewards)returns = advantages + batch_all_valuesfor i in range(epoch):active_all_probs, active_probs, active_all_values = active_model.forward_pass(batch_data)loss_state_value = torch.mean((returns - active_all_values) ** 2)ratio = active_probs / batch_probsloss_ppo = torch.mean(-advantages * ratio)loss = loss_ppo + value_loss_rate * loss_state_valueloss.backward()optimizer.step()optimizer.zero_grad()
上面的代码是PPO训练的整体代码,参考教学视频:
https://www.bilibili.com/video/BV1rixye7ET6?spm_id_from=333.788.videopod.sections&vd_source=da862fa7a218e81897b55d7e24fe26ee
https://www.bilibili.com/video/BV1iz421h7gb?spm_id_from=333.788.videopod.sections&vd_source=da862fa7a218e81897b55d7e24fe26ee
https://www.bilibili.com/video/BV1enQLYKEA5/?spm_id_from=333.1387.homepage.video_card.click&vd_source=da862fa7a218e81897b55d7e24fe26ee
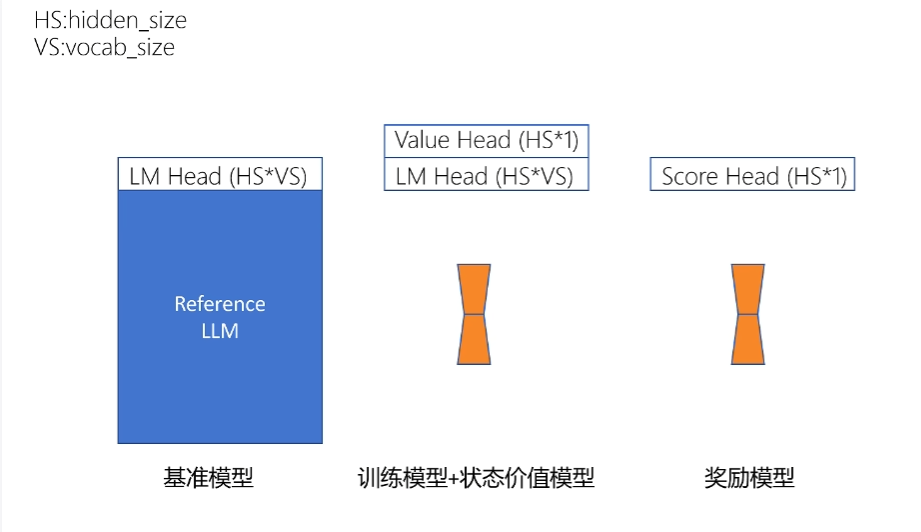
四个模型
基准模型(ref_model) 训练模型(activate model) 奖励模型(reward model) 状态价值模型(state_value model)
其中训练模型和状态价值模型只有输出头不同,在代码里体现为:active_model 同时包含策略头(policy head)和状态价值头(value head)
scores估算
batch_response = active_model.generate(batch_prompt) #采样一次
batch_data = concat(batch_prompt, batch_response) #拼接prompt+result
batch_scores = reward_model(batch_data) #PPO的奖励模型,只输出seq_len的最后一个位置的score,其他位置为0
batch_all_probs, batch_probs, batch_all_values = active_model.forward_pass(batch_data)
ref_all_probs, ref_probs, ref_all_values = ref_model.forward_pass(batch_data)
kls = compute_KL(batch_all_probs, ref_all_probs)
rewards = compute_rewards(batch_scores, kls) #eg. batch_scores+(-0.2)*kls
计算基准模型和训练模型的KL散度,并利用KL散度和scores计算rewards
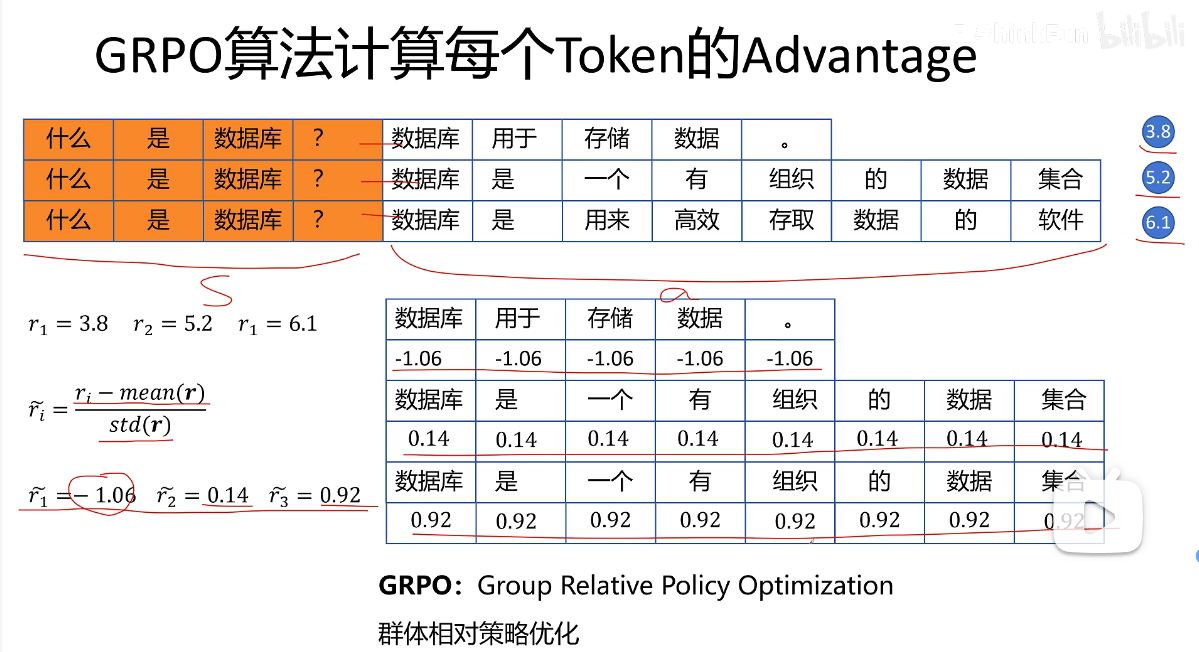
score计算,即GRPO(Group Relative Policy Optimization)的主要创新,相比PPO不只采样一次,而是使用active_model采样多次,得到result与多个scores序列,然后对其进行标准化。
GAE 广义优势估计:中和偏差与方差计算优势函数
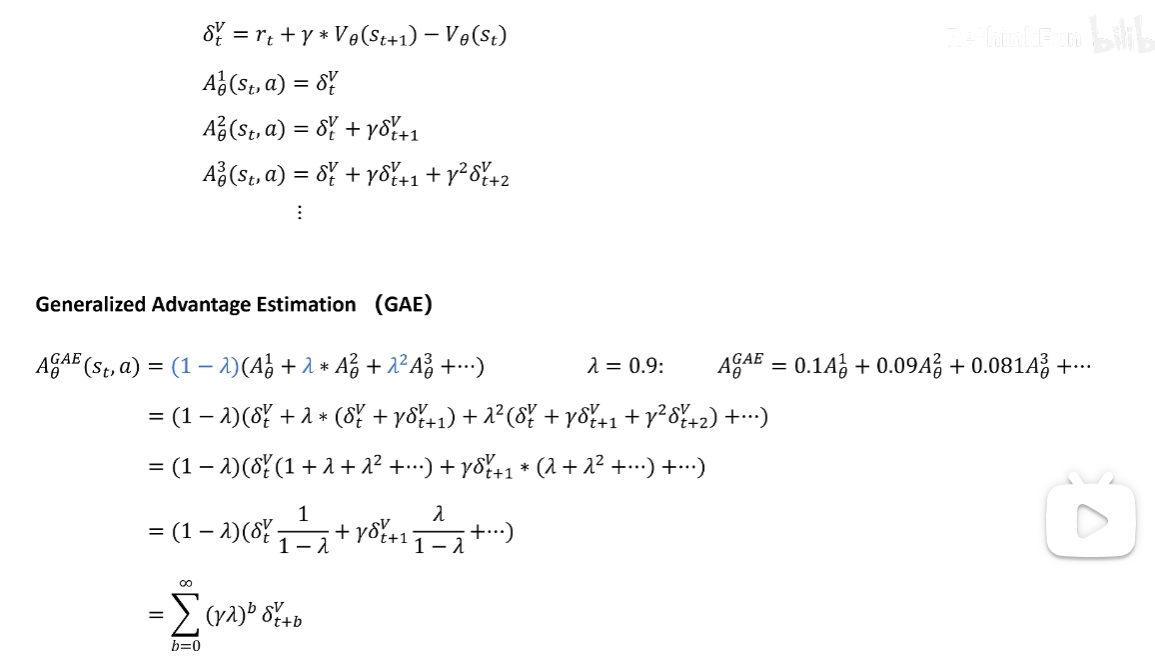
通过advantages和values相加计算values head labels即returns,让state_value model拟合这个returns值
一个batch训练阶段
对一个batch数据进行epoch次的更新,loss分别是loss_ppo和loss_state_value,更新active model