假设有N块GPU,模型有ψ个参数。
前提知识:每个参数对应一个梯度值,且SGD每个参数对应一个一阶动量,Adam每个参数对应一个一阶、一个二阶动量
DP(data parallel)
数据并行(单进程,多线程,只用一个cpu核),每个GPU上都保存完整的模型参数(param,or p)与优化器状态(optimizer state,or os)。磁盘读取数据,通过一个cpu进程将数据分成多份,每个GPU一份,反向传播结束后,得到各自完整的梯度,其他GPU将各自计算的梯度同步到GPU0上,由GPU0的优化器平均梯度后并更新GPU0的参数,再将更新后的参数广播给其他GPU。
各GPU的通信量如下:(其中N-1为其余GPU数,ψ为梯度更新一次的通信量)
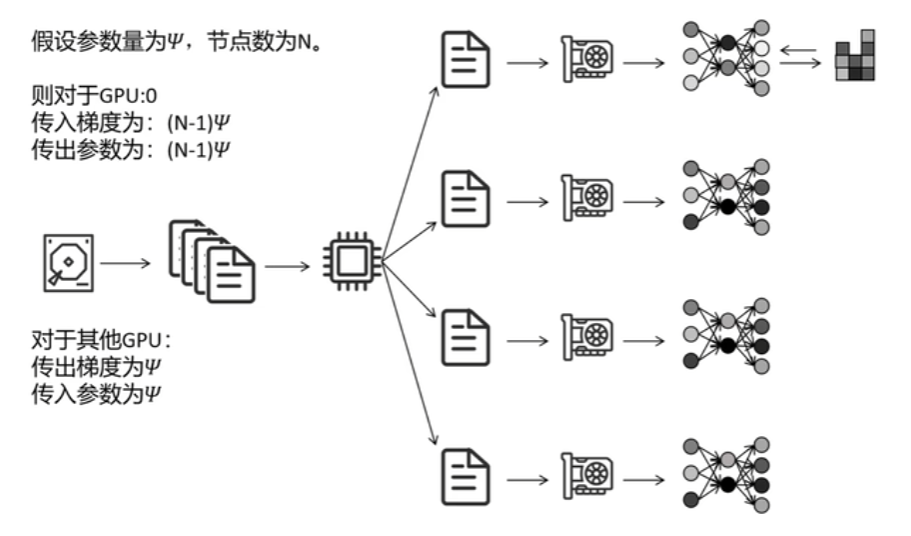
DP的问题在于:(1)单进程多线程,只能利用一个CPU核(2)GPU0的通信与计算压力大于其他GPU
DDP(distributed data parallel)
分布式数据并行(多进程), 每个GPU上也都保存完整的模型参数(param,or p)与优化器状态(optimizer state,or os)。相比DP而言,用各自的优化器计算ring-allreduce后的梯度并更新参数,网络状态和优化器状态始终保持同步
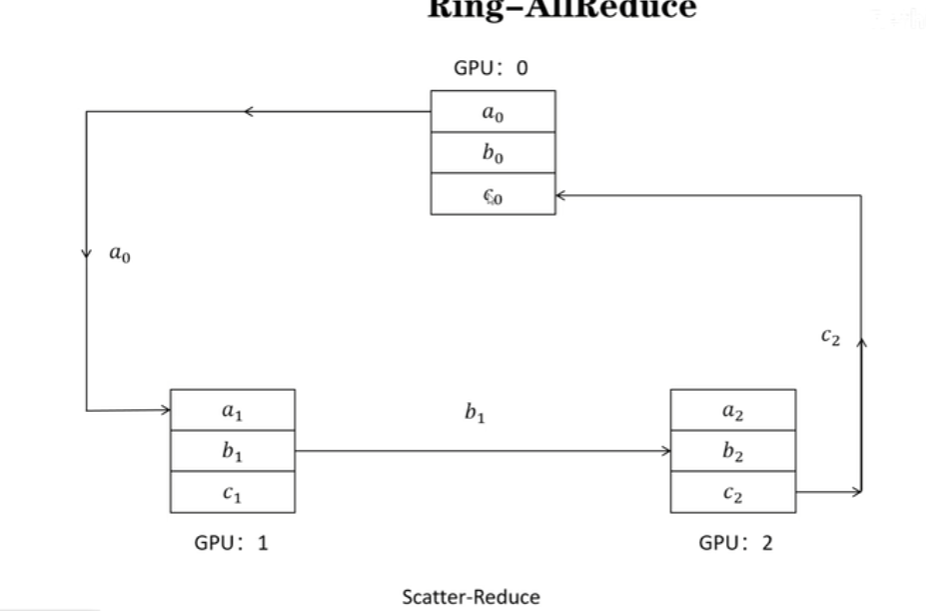
Ring-AllReduce两个阶段:scatter-reduce和allgather
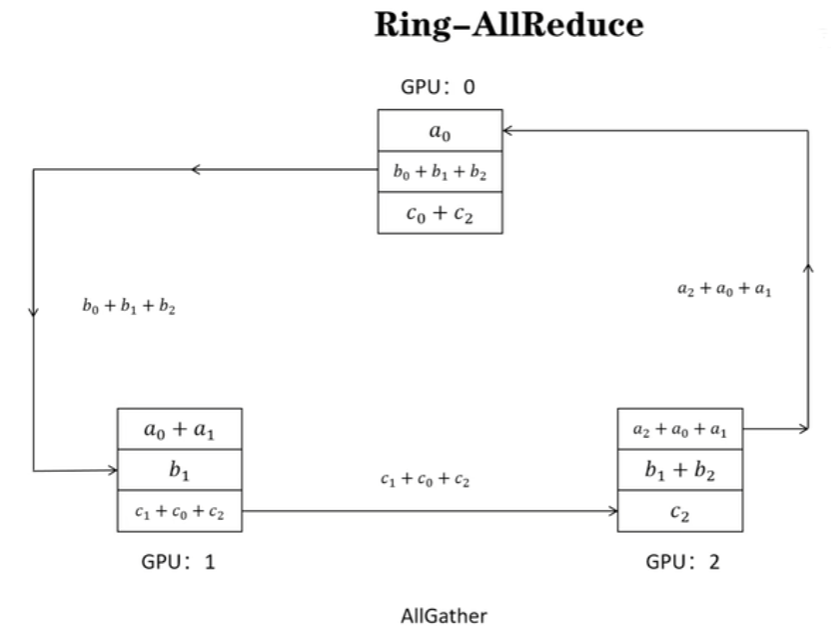
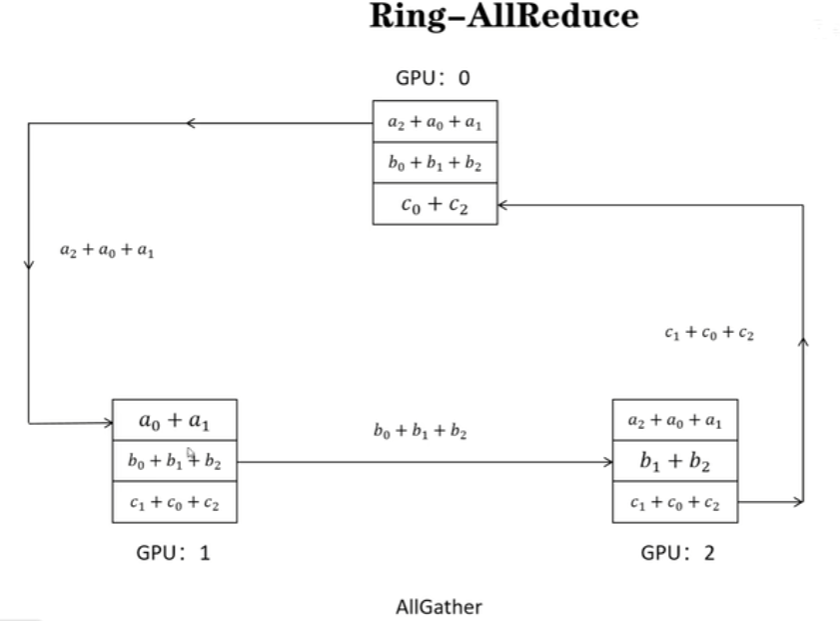
scatter-reduce示意图如下,每个GPU存有a、b、c,共3个梯度,经过3(模型参数量、梯度量即ψ)个通信回合,每个GPU上都有一个梯度值是完整的。(这个阶段梯度传递并相加)
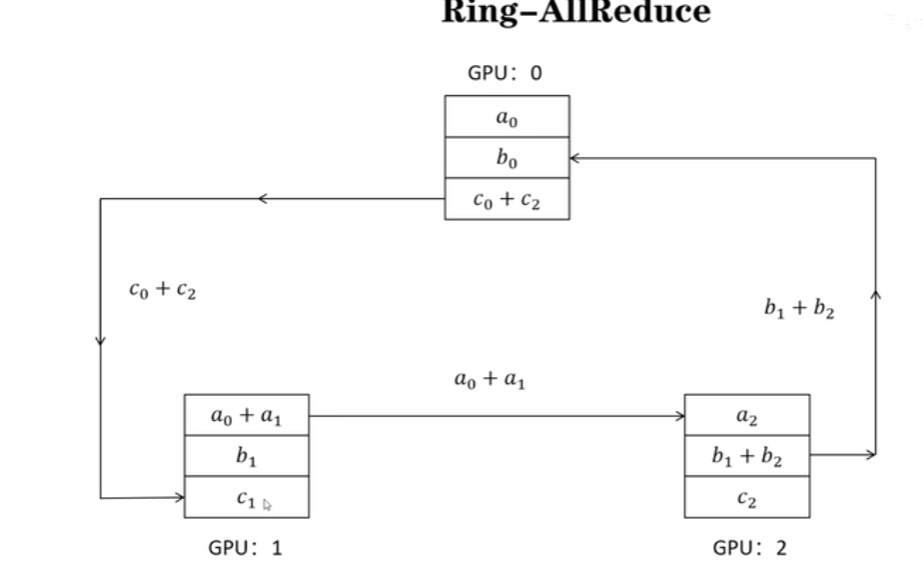
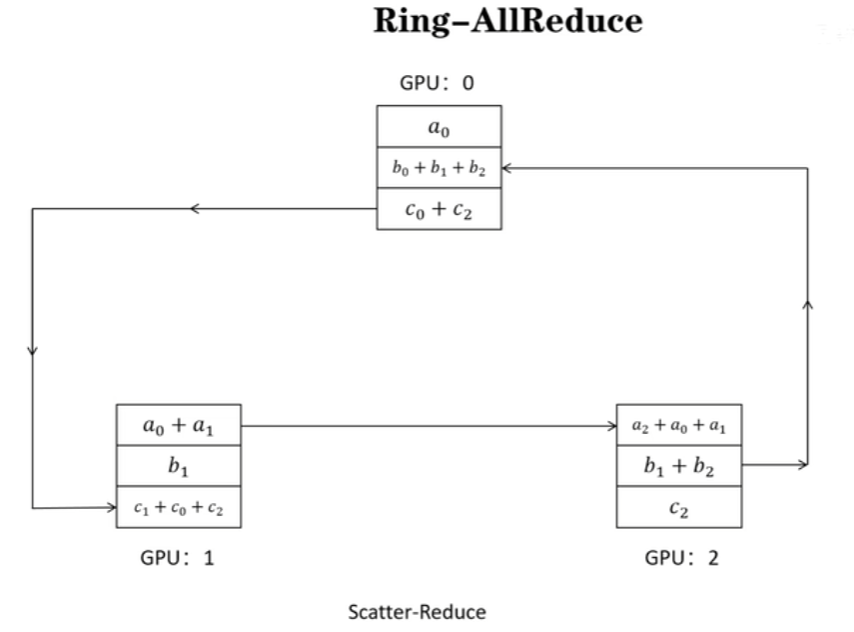
allgather示意图如下,(梯度传递并直接覆盖)。
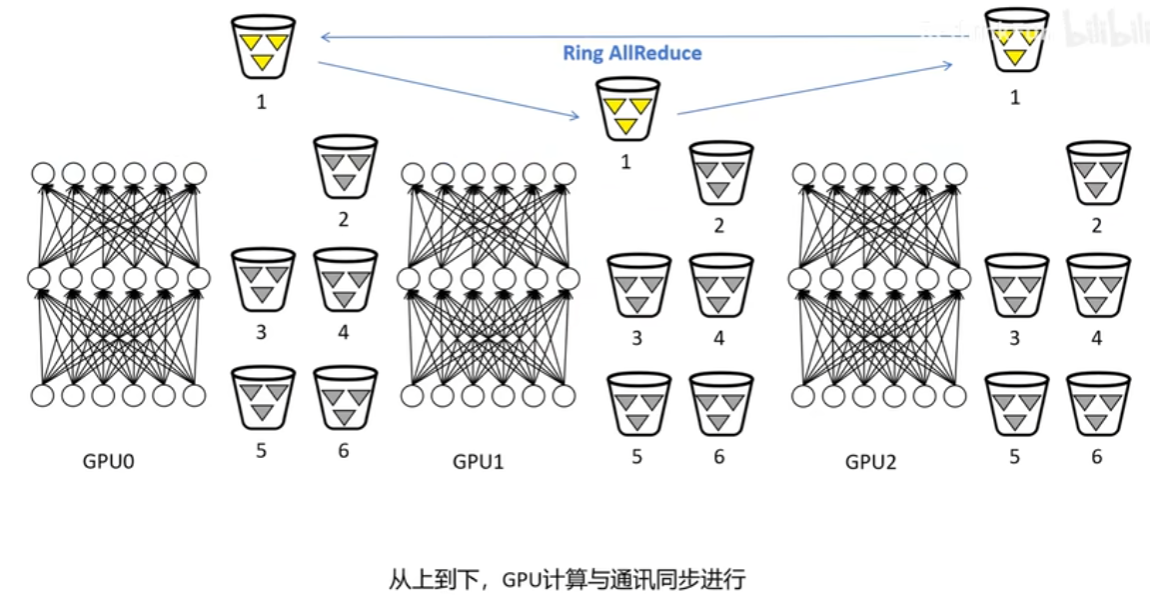
此外,为了提升效率,将梯度分组,先计算出来的那组梯度开始ring-allreduce同步,此时下一组梯度也正在被计算。
边计算边同步梯度
DDP通信量如下:(其中N-1为通信次数,ψ/N为单次通信量)

Deepspeed ZeRO
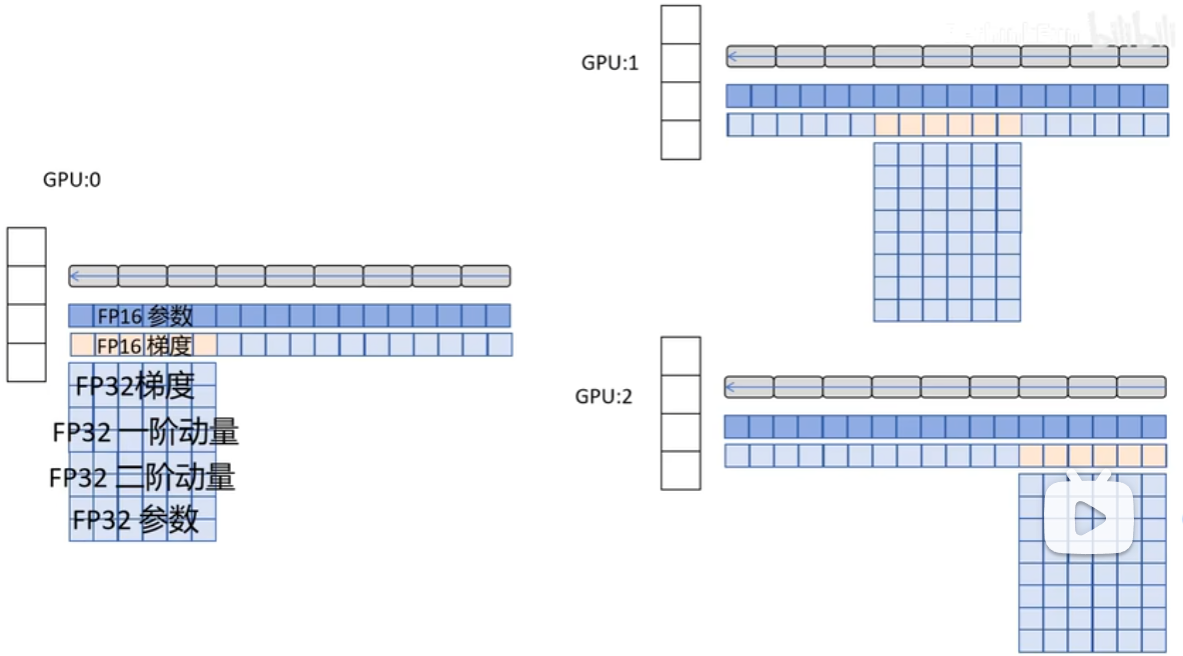
DP和DDP每个模型都需要存储完整的模型参数、梯度、优化器状态。使用Adam优化器的显存占用如图

而Deepspeed ZeRO-1、-2、-3分别对这三者做了处理,每张卡的显存占用如下图(baseline为标准DDP)
DDP的显存为fp16(2B)参数+fp16(2B)梯度+优化器(12B=4B一阶动量+4B二阶动量+4B参数)
ds-zero-1:相比DDP优化了优化器显存
ds-zero-2:相比DDP优化了优化器显存+梯度显存
ds-zero-3:相比DDP优化了优化器显存+梯度显存+参数显存

Deepspeed ZeRO-1
以3个GPU为例(Aadm+AWP),每个GPU上的梯度和参数是完整的,但优化器不是,整个过程如下:
-
同步:每个GPU从后往前计算梯度,当最后1/3的梯度计算完成,GPU0和GPU1将其同步给GPU2,计算呢后1/3的梯度均值;与此同时,3个GPU计算计算中间1/3的梯度,并同步给GPU1;前1/3的梯度,同步给GPU0;到此各GPU都拿到了自己负责那部分的梯度均值(fp16)。
-
更新:接着将fp16转为fp32(不存储)->进行缩放->更新优化器的fp32一阶动量和二阶动量->更新fp32的参数(master-weights)
->更新各自fp16的参数。
-
广播:广播各自那部分的fp16参数给其他GPU。
通信量分析:(N-1表示GPU数量,ψ/N为其余每个GPU同步的梯度量)

Deepspeed ZeRO-2
相比ZeRO-1,梯度不再是每个GPU都需要保存,而是以桶(DDP中的桶)的形式同步给负责该部分梯度的GPU后释放该部分显存占用。
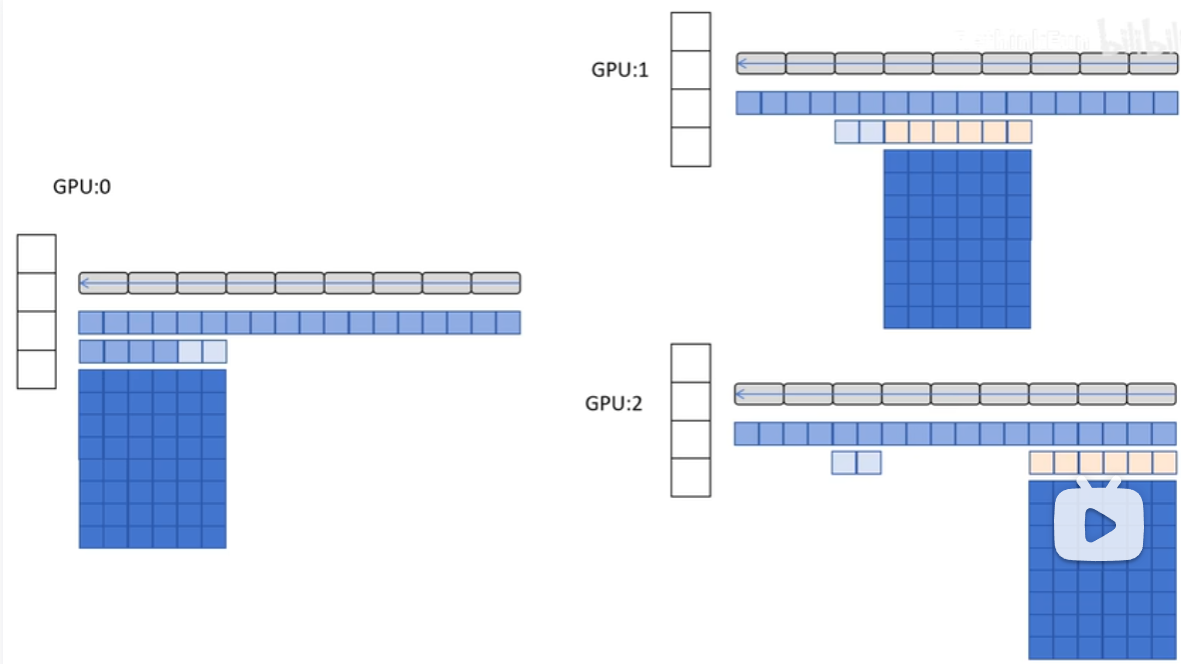
- 同步:每个GPU从后往前计算梯度,当一桶的梯度计算完成,就将梯度同步给负责该部分梯度的GPU,其他GPU立即释放该部分的显存占用。
- 更新:反向传播完成,每个GPU都有了自己所负责部分的平均梯度,像ZeRO-1 2.那样更新参数。
- 广播:广播各自那部分的fp16参数给其他GPU。
通信量分析:与ZeRO-1通信量相同,显存进一步减少
Deepspeed ZeRO-3
再ZeRO-2的基础上对参数也进行划分。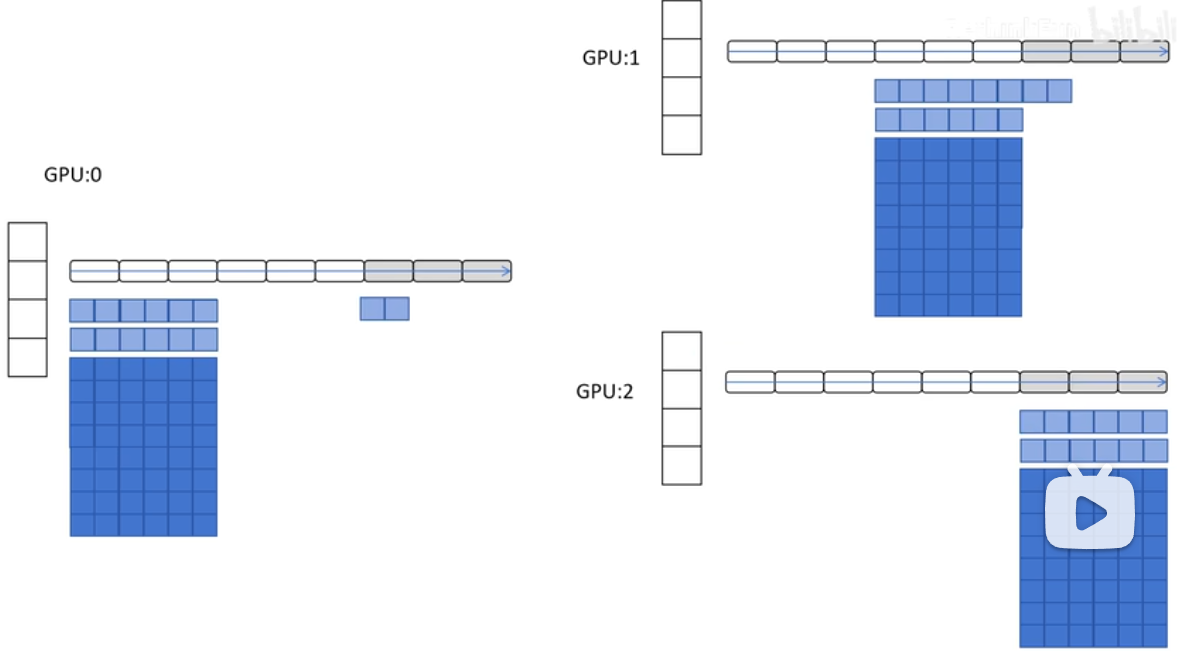
- 计算梯度:广播参数,进行前向传播,计算该部分输出后释放所占用显存;反向传播时,再广播参数,进行梯度计算,并释放该部分参数显存。
- 更新:反向传播完成,每个GPU都有了自己所负责部分的平均梯度,像ZeRO-1 2.那样更新参数。
通信量分析:相比之前,不再需要第三步广播参数,但是仍然需要前向传播时分块广播参数,这个地方通信量不变;但是新增了反向传播时的参数广播开销约等于ψ,故单GPU的传入/传出:3ψ。

总结:
deepspeed就是在DDP的基础上,减少单个GPU的显存占用的同时,-1、-2保存通信量不变,-3增加到了1.5倍,常用-2版本。
分布式训练的概览是这样,具体一些细节还在探索中~
参考:
https://www.bilibili.com/video/BV1mm42137X8/?spm_id_from=333.337.search-card.all.click&vd_source=da862fa7a218e81897b55d7e24fe26ee