学习深度神经网络并行策略时,常常混淆各种通信原语 Reduce/Scatter/Gather ... 本文尝试给出一种统一的抽象模型,将各类原语看作模型下一种个例。尝试简单调研并行计算理论,暂时没有找到完全一致对应的理论术语,故本文中许多术语概念临时创造使用,有较强民科意味,阅读时注意避免混淆。欢迎读者指点讨论!
GEMM 维度回顾
从最基础的矩阵乘法例子开始:
一共是 Batch/Token Length 、Input Dimension、 Output Dimension 三个维度,更常用的维度记号是 M/N/K,个人习惯使用 B/I/O ,语义更直观一些。
考虑虽然 layer 和 layer 之间数据依赖上呈现串行特征,类似 ILP 可从用户并行度上拉出 Pipeline,故部署大致考虑 L/B/I/O 四个维度。X/W/Y 三个变量和 L/B/I/O 四个维度之间关系如下表,我们把变量-维度之间的关系用相关/不相关表示,比如 X 和 L/B/I 维度相关,X 和 O 维度不相关,该术语会用在后文分析之中。
| 变量 | L | B | O | I | |
|---|---|---|---|---|---|
| X | √ | √ | - | √ | |
| W | √ | - | √ | √ | |
| Y | √ | √ | √ | - |
分布式系统变量的三态
考虑某个变量在分布系统中有三种存在状态,假设变量的大小是 M ,节点的数量是 N:
| 状态 | 定义 | 系统中占用存储量 | |
|---|---|---|---|
| 分散 (Partitioned) | 每个节点拥有变量的一部分 | M | |
| 复制 (Replicated) | 变量被复制到所有节点 | MN | |
| 集中 (Centralized) | 只有一个节点拥有变量,其余节点不保存该变量 | M |
理论上变量在分布式机器中的映射关系超出这 3 类,比如在部分机器上进行复制/分散等,但为了讨论方便,仅以这三类状态进行讨论推导。
变量在不同的状态间切换则会产生通信开销,三个状态间并不是两两间可以互相直接转换,集中状态和任意状态间可以切换,而复制和分散之间的切换要经过集中状态。根据转换过程的起始和终点状态可定义通信原语,直接转换叫做一阶通信原语,转换两次的叫做二阶通信原语,二阶通信原语在逻辑上可以看作两个一阶通信原语的组合,实际物理实践并不存在一个中间过程,只是一个助记概念。All-Gather 名称要是叫做 Gather-Broadcast 一下就明晰了……
严格意义上每个机器存储的部分和 (Partial Sum)数据并不一致,部分和并不属于复制。但其维度特性流量特性和输出特征 Y 相似,为了建立统一理论分析,妥协将多份部分和视作 Y 在不同节点上的复制,故涉及复制到集中的 reduce 操作发生了变量的转换。故 Reduce-Scatter + All-Gather 的 All-reduce 按下面图示理解似乎没有发生状态变换,实际从部分和变为了输出特征。
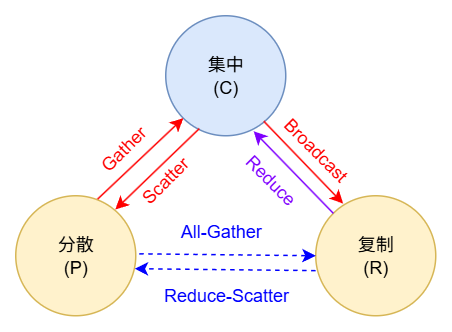
| Source\Target | 分散 | 复制 | 集中 |
|---|---|---|---|
| 分散 | - | All-Gather(2) | Gather |
| 复制 | Reduce-Scatter(2) | - | Reduce |
| 集中 | Scatter | Broadcast | - |
不同状态间切换产生的流量开销如下,为方便计算,分析时近似 N>>1:
| 通信原语 | 阶数 | 流量开销 |
|---|---|---|
| Gather/Scatter | 1 | \(\frac{N-1}{N}M \approx M\) |
| Broadcast/Reduce | 1 | \((N-1)M \approx NM\) |
| All-Gather/Reduce-Scatter | 2 | \(\frac{N-1}{N}M + (N-1)M \approx NM\) |
深度学习并行策略定义
静态分析:以维度划分定义并行策略
基础的某种并行策略即沿着单个维度进行切分,根据前文 L/B/I/O 的建模, 理论上存在 4 种划分策略。对相关维度的划分使得该变量状态为分散,而对无关维度的划分使该变量状态为复制。仅考虑前向过程,前向仅包含 X、W、Y 三个变量而不包括他们的导数 dX、dW、dY。对某个维度划分会出现两种情况:
- B / O / I :出现两个相关变量,一个无关变量
- L :出现三个相关变量
| 划分维度 | 策略名称 | X | W | Y |
|---|---|---|---|---|
| Layer | Pipeline Parallelism (PP) | P | P | P |
| Batch | Data Parallelism (DP) | P | R | P |
| Output | Tensor Parallelism @ColumnLinear(TP) | R | P | P |
| Input | Tensor Parallelism @RowLinear (TP) | P | P | R |
在 Intra-kernel 划分下可以带入各个变量大小 \(M_X\)、\(M_W\)、\(M_Y\) 计算系统存储需求,注意针对 L 维度而言虽然所有变量都是相关维度,对于 W 假设不存在更上位的存储,需要所有层全部存入,而对于 X 和 Y 除了 PP 各层 L 同时出现,其余并行策略 L 在时间上串行,存储需求是对时间轴求最大值,此时 L 不纳入存储计算:
| 划分维度 | 策略名称 | X | W | Y | Total |
|---|---|---|---|---|---|
| Layer | Pipeline Parallelism (PP) | LBI | LOI | LBO | LBI + LOI + LBO |
| Batch | Data Parallelism (DP) | BI | NLOI | BO | BI + NLOI + BO |
| Output | Tensor Parallelism @ColumnLinear(TP) | NBI | LOI | BO | NBI + LOI + BO |
| Input | Tensor Parallelism @RowLinear (TP) | BI | LOI | NBO | BI + LOI + NBO |
动态分析:策略流量需求推导
前文提到变量在状态之间切换需要通过通信原语,推理中状态转变来自于不同层对于 Activation 变量 X/Y 状态的变换,这一层的 Y 是下一层的 X。
此外即使变量状态没有切换也有两种情况,二者在同一节点或者不同节点,不同节点间(PP)产生等同于该数据量的流量开销,相同节点(DP)则无额外流量开销。为表示简单,假设所有 Layer O/I embedded 维度相同为符号 D。
| 划分维度 | 策略名称 | Y/X | 通信原语 | 流量 |
|---|---|---|---|---|
| Layer | Pipeline Parallelism (PP) | P/P | - | LBD |
| Batch | Data Parallelism (DP) | P/P | - | 0 |
| Output | Tensor Parallelism @ColumnLinear(TP) | P/R | All-Gather | NLBD |
| Input | Tensor Parallelism @RowLinear (TP) | R/P | Reduce-Scatter | NLBD |
挖坑:待补充反向过程和专家并行策略分析……