下载项目
项目地址:
https://github.com/Intellindust-AI-Lab/DEIM
打开网页后,可以选择下载方式,本次用的是下载zip的方式,将下载得到的文件解压到E:\DEIM-main目录下:
接下来,跟着项目的README.md文件,一步一步部署和运行项目。
1、预训练模型
![]()
在GitHub的项目网页中,列出了下面两种预训练模型:
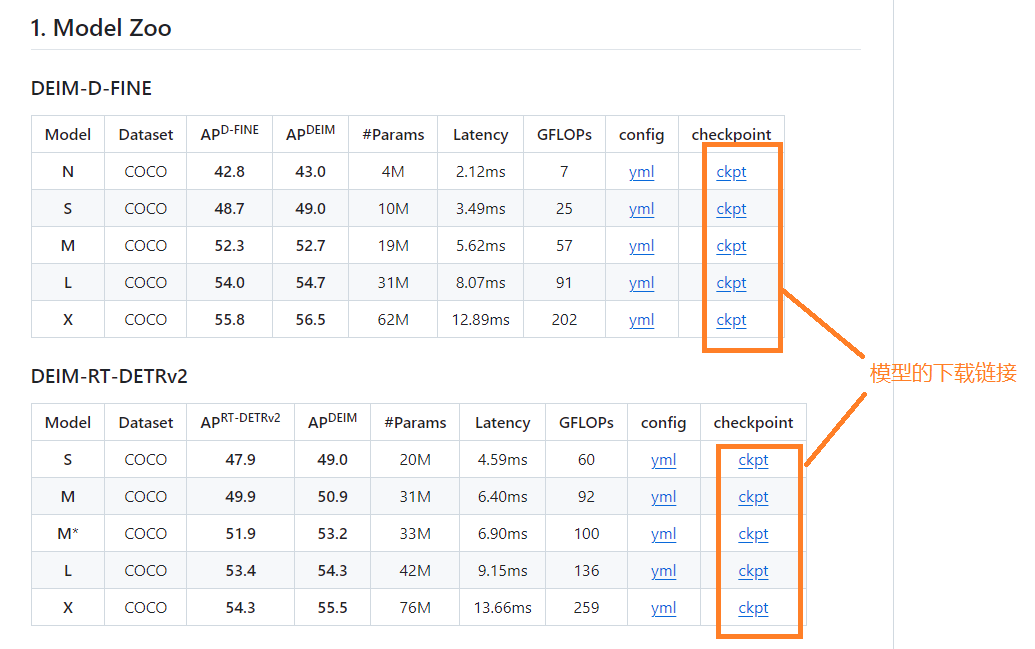
两种模型都很优秀,根据需要选择基于D-FINE或RT-DERT的DEIM模型。
如果想深入了解这两个模型,它们的项目地址:
https://github.com/lyuwenyu/RT-DETR/blob/main/README_cn.md
以及
https://github.com/Peterande/D-FINE/blob/master/README_cn.md
可以打开以上网址了解或下载。
两种模型的适用场景:
两种模型分别适用哪些应用场景,我问了豆包,总结如下:
基于 DEIMv2 技术改进的 D-FINE(如 DEIM-D-FINE)和 RT-DETRv2(及结合 DEIMv2 的版本),由于核心设计目标和性能侧重不同,适用场景存在明显差异,具体如下:
基于 DEIMv2 的 D-FINE(如 DEIM-D-FINE)适用场景
DEIM-D-FINE 的核心优势是在保持实时性的同时,通过 DEIM 的训练优化策略进一步提升检测精度,尤其强化了小目标和复杂场景的表现,因此更适合对精度有较高要求、且需要平衡速度的场景:
- 安防监控:需检测远距离小目标(如远处行人、车辆细节),同时要求实时反馈(如异常行为预警)。
- 无人机巡检:航拍场景中目标尺度差异大(从近处大型设备到远处小型部件),需高精度识别故障或异常,且无人机算力有限,需高效模型。
- 智能驾驶(低算力场景):如低速自动驾驶(园区、港口),需检测周边行人、障碍物(包括小目标如锥桶),同时适配车载中端芯片(如 NVIDIA Jetson 系列)。
- 工业质检:生产线中检测微小缺陷(如电子元件的划痕、焊点瑕疵),要求高精度且实时响应(不影响生产节拍)。
基于 DEIMv2 的 RT-DETRv2 适用场景
RT-DETRv2 本身是面向极致实时性的检测器,结合 DEIMv2 后进一步优化了效率和多尺度适应性,更适合对速度要求苛刻、硬件资源受限的场景:
- 移动端实时应用:如手机端视频特效(实时手势 / 物体跟踪)、短视频内容审核(快速识别违规物体),需在低功耗移动芯片(如骁龙、天玑)上实现毫秒级推理。
- 高速实时追踪:如体育赛事直播中的运动员实时追踪、车流监控中的高速车辆计数,要求模型在高帧率(30fps 以上)下稳定运行。
- 边缘计算设备:如嵌入式摄像头(智能门铃、家用监控),硬件算力有限(通常为 ARM 架构),需轻量化模型满足实时性(延迟<50ms)。
- 大规模部署场景:如城市级摄像头联网监控,需在服务器集群中同时处理数千路视频流,模型需兼顾单路速度和资源占用(降低显存 / 内存消耗)。
核心差异总结
| 维度 | 基于 DEIMv2 的 D-FINE | 基于 DEIMv2 的 RT-DETRv2 |
|---|---|---|
| 性能侧重 | 精度优先,兼顾实时性(尤其小目标) | 速度优先,极致效率(多尺度适配) |
| 硬件适配 | 中端算力设备(如 Jetson、中端 GPU) | 低算力设备(移动端、边缘设备) |
| 场景关键词 | 小目标、复杂场景、高精度需求 | 高速实时、大规模部署、低功耗 |
选择时需根据场景的精度需求、硬件算力、实时性要求三者平衡:高精度 + 中小算力选 DEIM-D-FINE;高速度 + 低算力选 DEIMv2 优化的 RT-DETRv2。
模型下载
我下载了以上所有的yml文件和checkpoint文件,并上传到百度网盘,方便没法上科学网时下载。
https://pan.baidu.com/s/1n86W_Ud2XE2h3iscXWPzVQ?pwd=2emu 提取码2emu
2、快速开始

配置环境
按要求,创建conda环境并安装requirements.txt中指定的包。
conda create -n deim python=3.11.9
conda activate deim
pip install -r requirements.txt
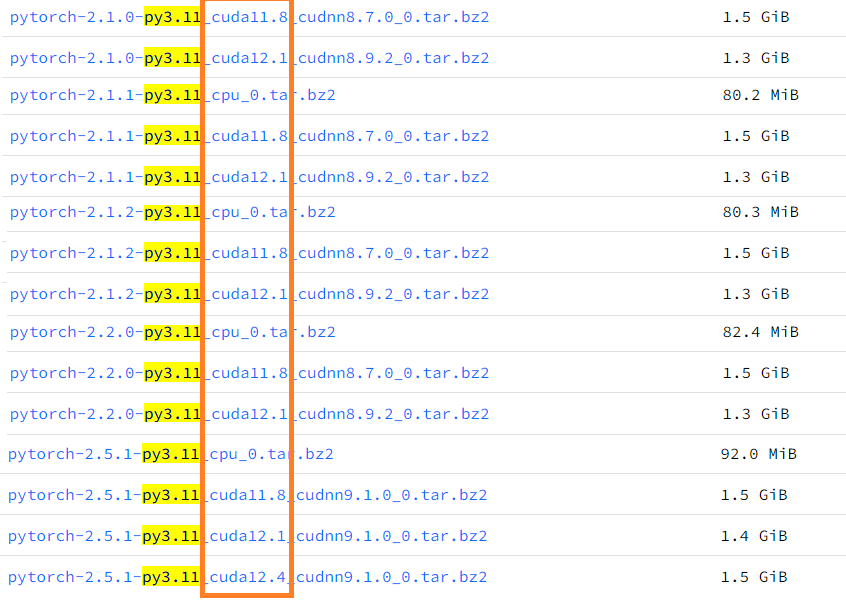
需要注意的是,cuda版本应该是11.8或12.1、12.4,因为requirements.txt中要求torch>=2.0.1,环境的python=3.11,符合这两个条件的cuda版本只有11.8和12.1、12.4,可以在下面的网页查询到合适的版本:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/linux-64/
查询的结果:
Windows系统下,直接安装requirements.txt,会安装一个CPU版的pytorch,无法使用GPU。所以需要把requirements.txt中的pytorch和torvision去掉,手动安装这两个(CUDA版的),然后再自动安装requirements.txt中的其余包。
安装torch的指令示例:
pip install torch==2.1.1+cu118 torchvision==0.16.1+cu118 --index-url https://download.pytorch.org/whl/cu118另外,如果按照项目的要求安装后,运行时遇到这个报错:
A module that was compiled using NumPy 1.x cannot be run in
NumPy 2.3.3 as it may crash. To support both 1.x and 2.x
versions of NumPy, modules must be compiled with NumPy 2.0.
Some module may need to rebuild instead e.g. with 'pybind11>=2.12'.
需要将numpy降版安装:
pip install "numpy<2.0"准备数据集
首先,准备图片,并将其存放在同一个文件夹内。我这里从coco数据集中选了200张图片作为实验数据,如果使用自己的图片,方法相同。
然后,选择一个标注软件进行标注。常见的标注软件有CVAT、labelme、makesense.ai等,这里选择了makesense.ai,相对来说简单易用。
- makesense.ai的使用方法:
打开网址:https://www.makesense.ai/,在网页中直接就可以进行操作。打开网页后点击:Get Starteted

然后:

选择100个文件:
 选择标注类型:
选择标注类型:
两种模式的区别:
- 目标检测(Object Detection):“框”出每个物体,告诉模型“图里有猫、狗,分别在哪”。
- 图片识别/分类(Image Classification):“整图”打标签,告诉模型“这张图就是猫,别管它在哪”。
这里选目标检测。
网页出现了选择类别标签的界面:
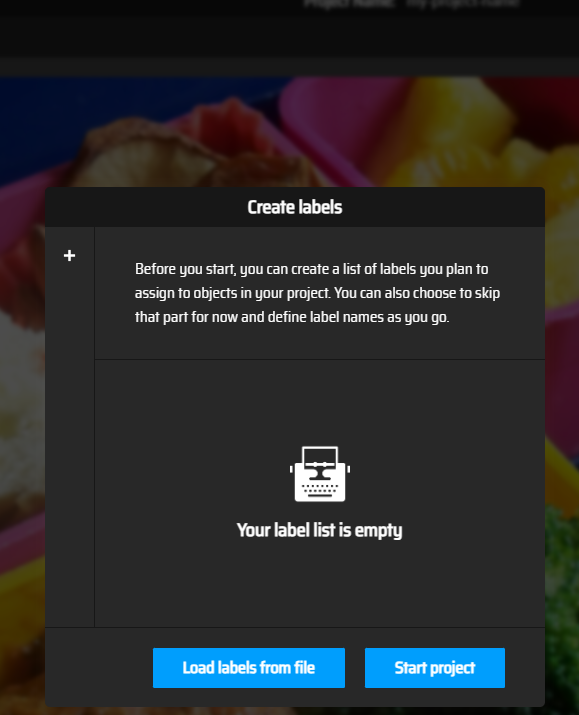
可以在网页上随时输入类别标签,也可以提前编辑好物体的类别,每一类占一行存为txt文件后,点击:Load labels from file导入txt文件。

导入成功:
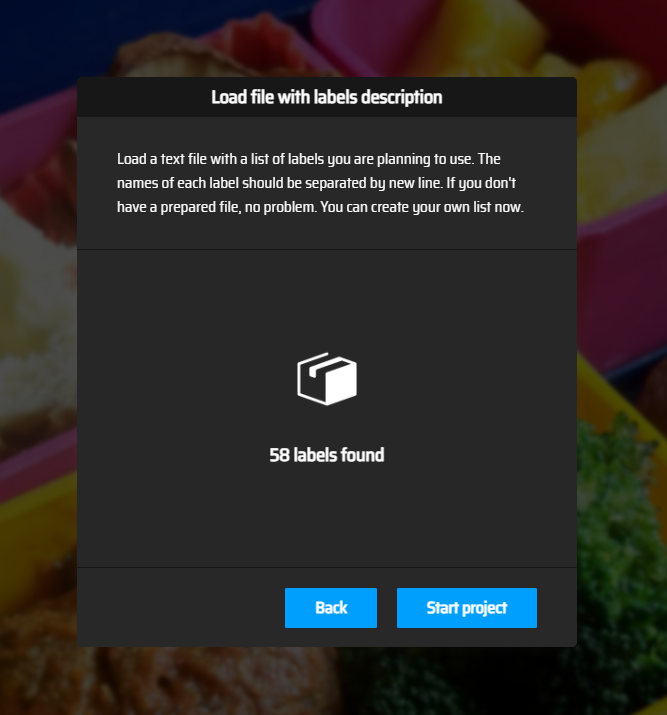
点击Start project开始标注,使用多边形工具:
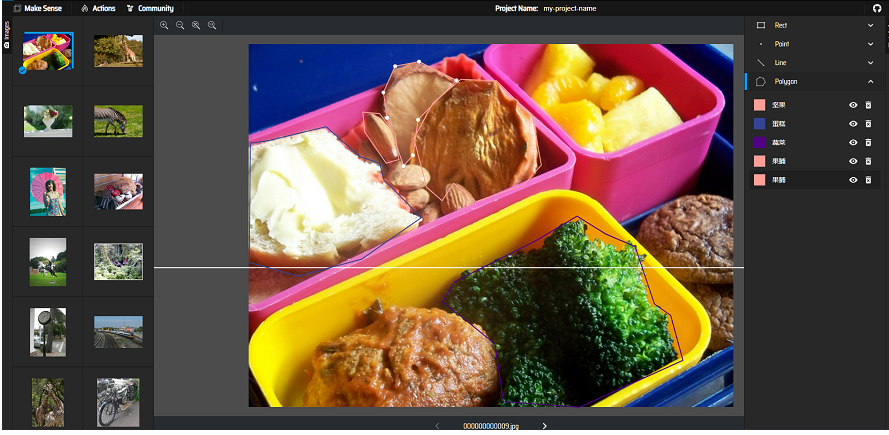
在标注过程中可以随时编辑和增加标签:
标注完成后,导出标注结果:
选择了coco格式:
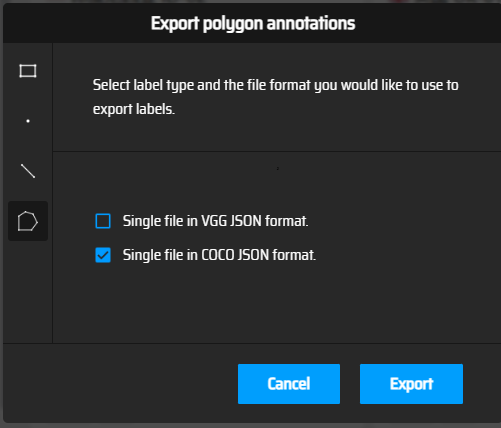
点击Export,浏览器会下载得到的标注文件,其内容如下:
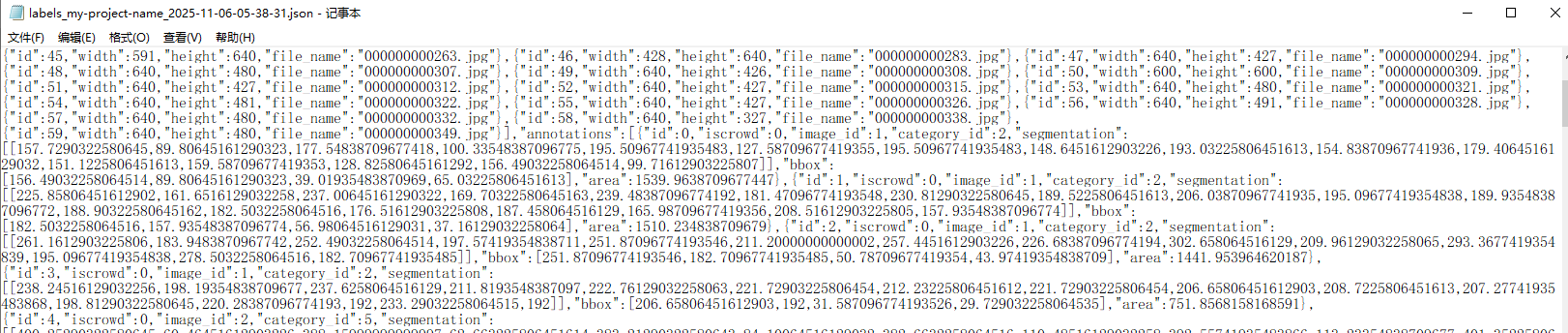
至此,得到了训练集的100张图片的标注文件。
用同样的方法,再标注100张图片,作为验证集。
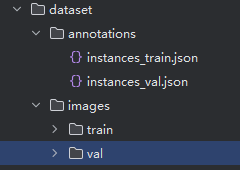
按照项目的要求,如果使用自定义数据,使用以下的文件结构:

按照要求,创建目录并将前面步骤训练集的100张图片复制到E:\DEIM-main/dataset/images/train/,验证集的100张图片复制到E:\DEIM-main/dataset/images/val/。训练集和验证集的标注文件复制到E:\DEIM-main/dataset/,并分别将文件名改为:instances_train.json和instances_val.json:
修改配置
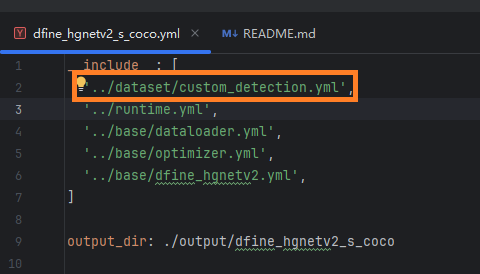
修改custom_detection.yml,它的文件位置在:
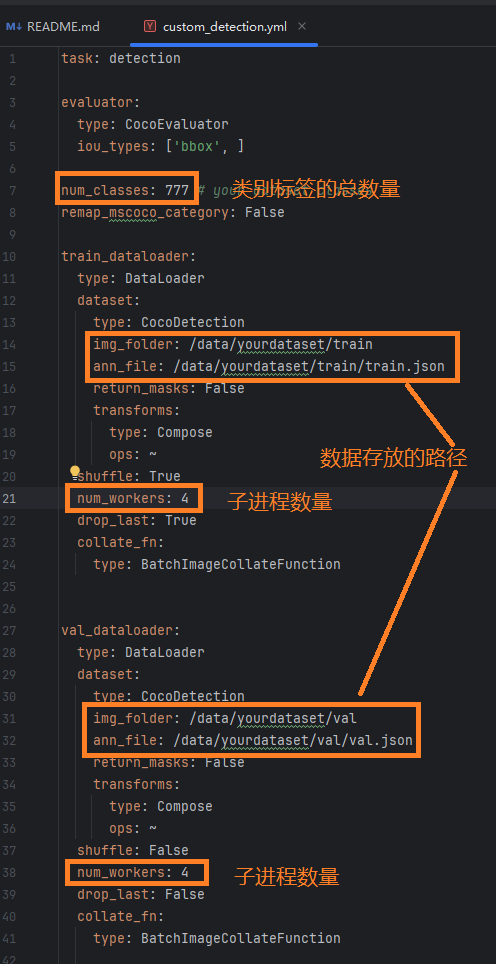
需要修改的内容:
修改后的实际文件:
task: detection
evaluator:type: CocoEvaluatoriou_types: ['bbox', ]
num_classes: 58 # your dataset classes
remap_mscoco_category: False
train_dataloader:type: DataLoaderdataset:type: CocoDetectionimg_folder: dataset/images/trainann_file: dataset/annotations/instances_train.jsonreturn_masks: Falsetransforms:type: Composeops: ~shuffle: Truenum_workers: 1drop_last: Truecollate_fn:type: BatchImageCollateFunction
val_dataloader:type: DataLoaderdataset:type: CocoDetectionimg_folder: dataset/images/trainann_file: dataset/annotations/instances_val.jsonreturn_masks: Falsetransforms:type: Composeops: ~shuffle: Falsenum_workers: 4drop_last: Falsecollate_fn:type: BatchImageCollateFunction3、使用方法
![]()
训练:
在项目中给出了一条训练的指令:
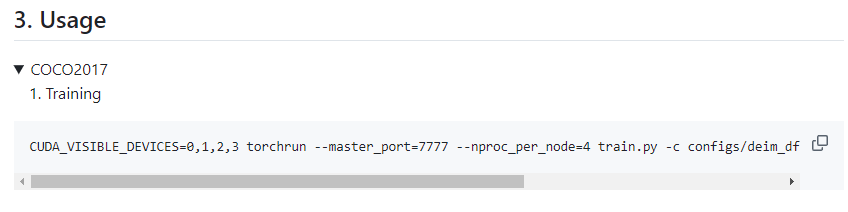
CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/deim_dfine/deim_hgnetv2_${model}_coco.yml --use-amp --seed=0
命令详解:
CUDA_VISIBLE_DEVICES=0,1,2,3:指定训练可使用的 GPU 设备编号为 0、1、2、3(共 4 张 GPU),限制程序只能访问这些 GPU。torchrun:PyTorch 官方推荐的分布式训练启动工具,替代了旧的torch.distributed.launch,能自动管理进程和节点通信。--master_port=7777:指定主节点(master)的通信端口为 7777,用于分布式进程间的初始化通信(需确保端口未被占用)。--nproc_per_node=4:指定每个节点(当前机器)启动 4 个进程,与可用 GPU 数量(4 张)对应,通常每个进程绑定一张 GPU。train.py:训练脚本的入口文件。-c configs/deim_dfine/deim_hgnetv2_${model}_coco.yml:通过-c参数指定训练配置文件路径,其中${model}是一个变量(需提前定义具体模型名称,如large、base等),配置文件包含数据集路径、模型参数、训练超参等设置。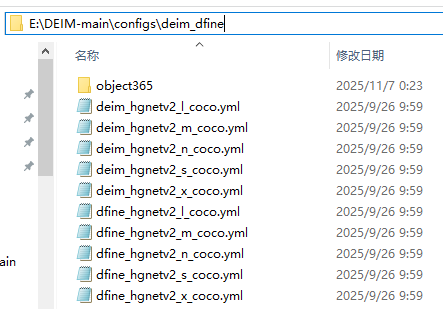
--use-amp:启用混合精度训练(Automatic Mixed Precision),加速训练并减少显存占用。--seed=0:设置随机种子为 0,保证实验的可复现性。更多的训练参数,在项目的train.py中有定义:
# priority 0parser.add_argument('-c', '--config', type=str, required=True) # 配置项,必需的parser.add_argument('-r', '--resume', type=str, help='resume from checkpoint') # 从检查点恢复parser.add_argument('-t', '--tuning', type=str, help='tuning from checkpoint') # 从检查点微调parser.add_argument('-d', '--device', type=str, help='device',) # 设备,可选的parser.add_argument('--seed', type=int, help='exp reproducibility') # 实验可重复性,可选的parser.add_argument('--use-amp', action='store_true', help='auto mixed precision training') # 自动混合精度训练,可选的parser.add_argument('--output-dir', type=str, help='output directoy') # 输出目录,可选的parser.add_argument('--summary-dir', type=str, help='tensorboard summary') # 张量板,用于指定 TensorBoard 日志文件(summary 文件)的存储目录parser.add_argument('--test-only', action='store_true', default=False,) # 仅测试,可选的# priority 1parser.add_argument('-u', '--update', nargs='+', help='update yaml config') # 更新yaml配置# envparser.add_argument('--print-method', type=str, default='builtin', help='print method') # 打印方法,默认内置parser.add_argument('--print-rank', type=int, default=0, help='print rank id') # 打印rank id,默认0parser.add_argument('--local-rank', type=int, help='local rank id') # 本地rank id比如,想要在训练中断后继续原来的检查点训练,就可以增加指令:
--resume /checkpoints/check007.pth再如,想要在预训练模型的基础上微调,就增加指令:
-t deim_dfine_hgnetv2_n_coco_160e.pth # 权重文件位于项目的根目录或:
-t /ckpts/deim_dfine_hgnetv2_n_coco_160e.pth # 当权重文件不在根目录下,就指定目录
其中的deim_dfine_hgnetv2_n_coco_160e.pth是从项目网页中下载的预训练权重。
- 根据自己的实际情况修改上面的指令。
比如我本次训练用的指令:
CUDA_VISIBLE_DEVICES=0,1 torchrun --master_port=7777 --nproc_per_node=2 train.py -c configs/deim_dfine/deim_hgnetv2_s_coco.yml --use-amp --seed=0
这是Linux下的命令,如果在Windows下运行,需要把相应的指令根据Windows的格式需要改为:
set CUDA_VISIBLE_DEVICES=0,1 && torchrun --master_port=7777 --nproc_per_node=2 --rdzv_backend=c10d train.py -c configs/deim_dfine/deim_hgnetv2_s_coco.yml --use-amp --seed=0本次的Windows机器是单显卡的,要去掉指令中的有关分布式训练的指令,否则会报错,所以最终的实际运行指令是:
set CUDA_VISIBLE_DEVICES=0 && "C:\Users\DY\.conda\envs\deim\python.exe" train.py -c configs/deim_dfine/deim_hgnetv2_s_coco.yml --use-amp --seed=0需要注意的是,由于是使用了自定义数据集,所以还需要修改本次训练用的模型的配置,将它的调用yml文件指向自定义的yml:
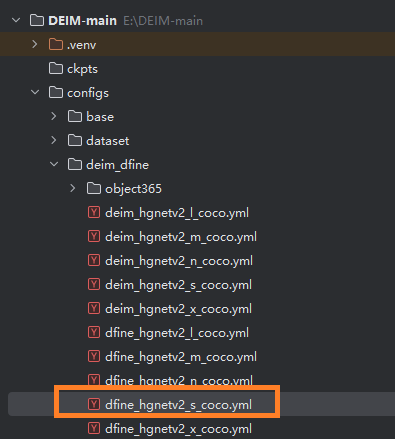
把第一行的yml修改为custom_detection.yml:
在Windows下运行,会报错:
File "C:\Users\DY\.conda\envs\deim\Lib\site-packages\faster_coco_eval\core\coco.py", line 326, in load_json _data = json.load(io) ^^^^^^^^^^^^^ File "C:\Users\DY\.conda\envs\deim\Lib\json\__init__.py", line 293, in load return loads(fp.read(), ^^^^^^^^^ UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position 92490: illegal multibyte sequence
原因是COCO 数据集的标注文件均为 UTF-8 编码,而 Windows 系统默认文件编码为gbk,因此直接读取会导致解码错误。解决方法:
将C:\Users\DY\.conda\envs\deim\Lib\site-packages\faster_coco_eval\core\coco.py的第325行,
with open(json_file) as io: _data = json.load(io)改为:
with open(json_file, encoding="utf-8") as io:即可正常训练。