微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
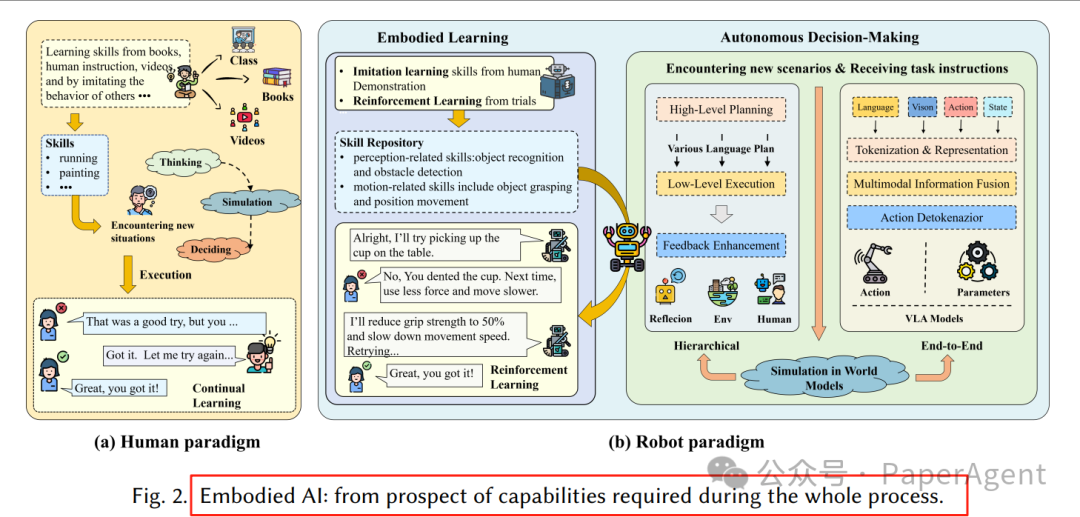
具身智能(Embodied AI)被视为通往通用人工智能(AGI)的关键路径,但传统方法在开放、动态环境中仍面临泛化瓶颈。 近两年来,大模型(LLM、LVM、LVLM、MLM、VLA等)的爆发为具身系统带来了新的感知、推理与学习能力。
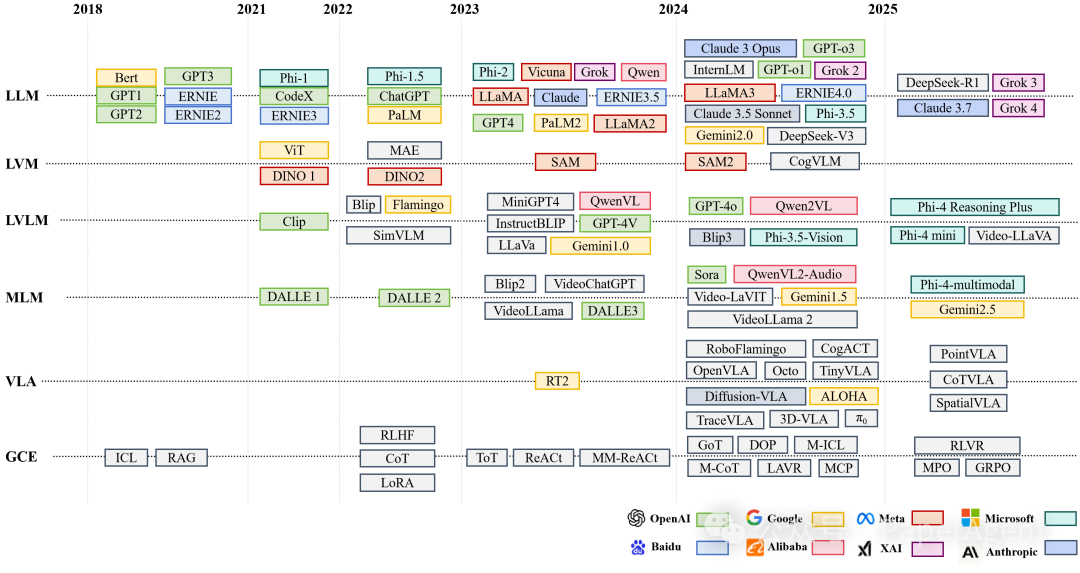
主要LLM时间线
电子科大最新综述系统(论文链接在文末)梳理了大模型如何赋能具身智能的两大核心——自主决策与具身学习,并首次将“World Model”纳入统一框架,为研究者提供了全景式路线图。

添加图片注释,不超过 140 字(可选)
2. 大模型 × 具身智能:整体框架

Fig-1 论文整体架构
图1:综述章节组织,涵盖分层/端到端决策、具身学习、World Model
添加图片注释,不超过 140 字(可选)
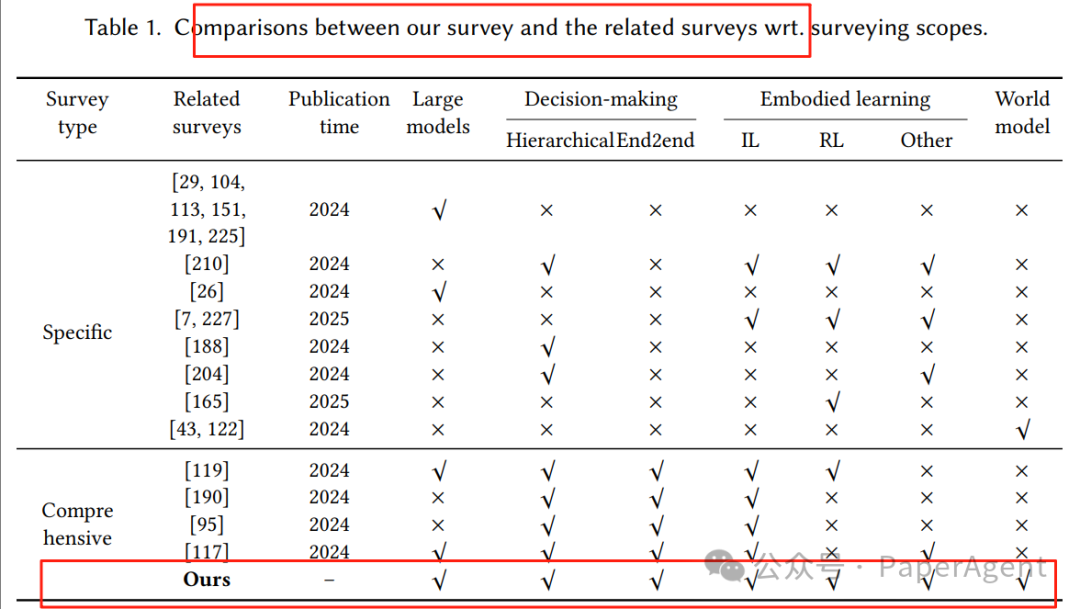
表1:对比现有综述,本文首次同时覆盖五大维度
3. 自主决策两大范式
3.1 分层决策(Hierarchical Decision-Making)

Fig-5 分层决策流程
感知 → 高层规划 → 底层执行 → 反馈增强
3.1.1 高层规划:让大模型“写剧本”
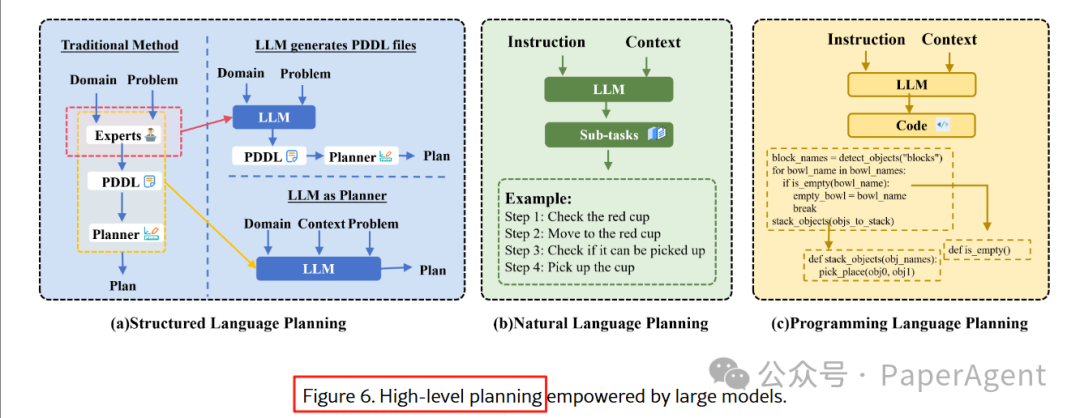
添加图片注释,不超过 140 字(可选)
-
结构化语言:LLM 生成 PDDL 规划,LLM+P、PDDL-WM 用外部验证器纠错。
-
自然语言:SayCan、Text2Motion 用 RL 值函数或几何检查器过滤不可行动作。
-
编程语言:Code-as-Policy、Instruct2Act 将指令直接转为可执行 Python 代码。
3.1.2 底层执行:从 PID 到扩散策略
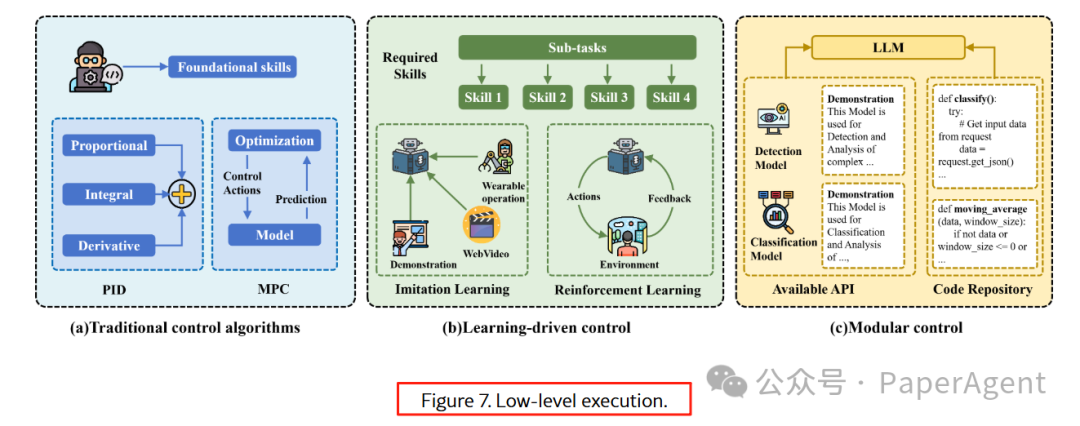
添加图片注释,不超过 140 字(可选)
-
传统 PID/MPC 与 LLM 调用 CLIP、SAM 等视觉 API 结合,实现模块化控制。
-
最新工作(π₀、Octo)用扩散模型输出连续轨迹,兼顾平滑与精准。
3.1.3 反馈闭环:三种来源
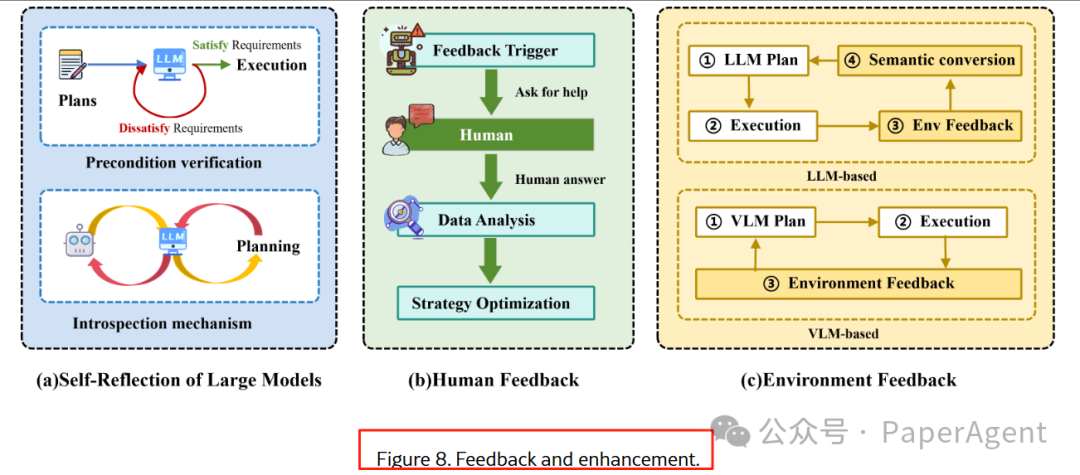
添加图片注释,不超过 140 字(可选)
-
Self-Reflection:Re-Prompting、Reflexion 让 LLM 自评自改。
-
人类反馈:YAY Robot、IRAP 在线接受语言纠正。
-
环境反馈:Inner Monologue、DoReMi 把多模态观测转成自然语言再规划。
3.2 端到端决策:Vision-Language-Action (VLA) 模型
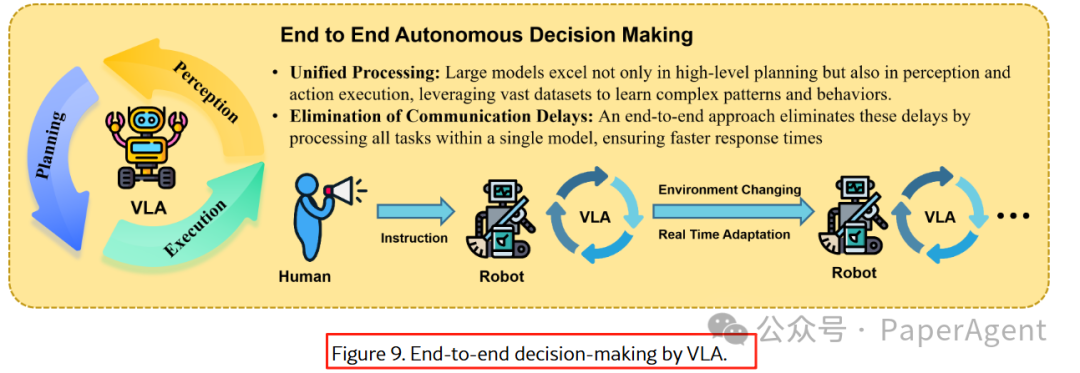
Fig-9 VLA 端到端框架
图9:VLA 直接映射多模态输入到动作
3.2.1 VLA 的三板斧
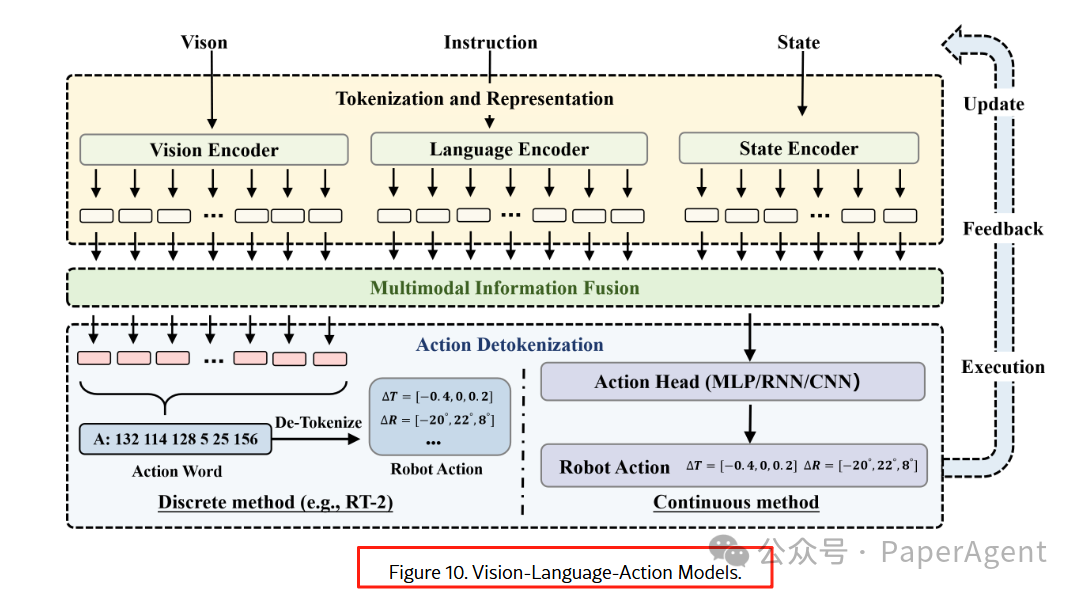
添加图片注释,不超过 140 字(可选)
3.2.2 三大增强方向
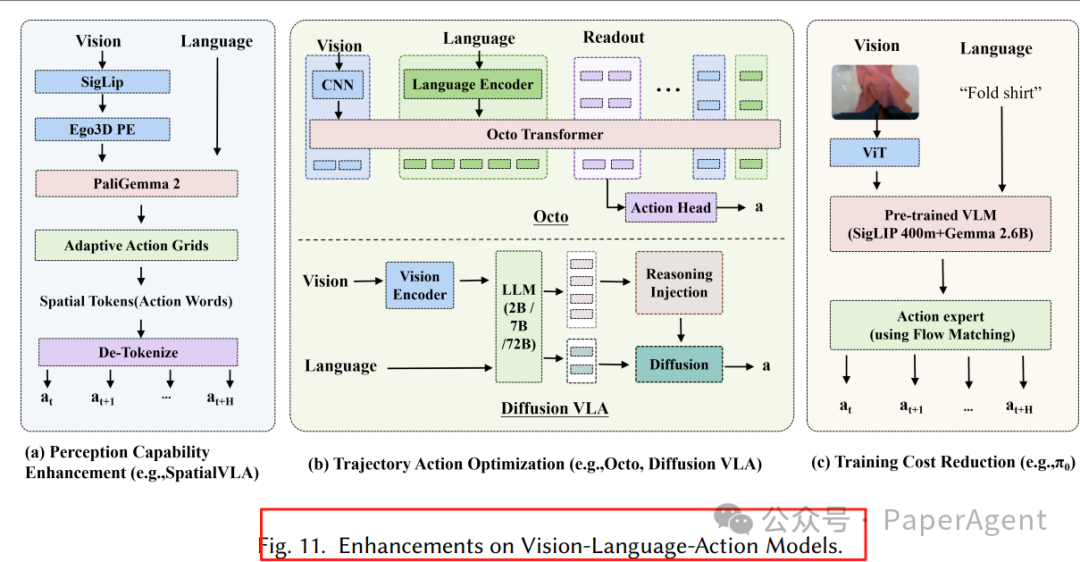
添加图片注释,不超过 140 字(可选)
-
感知增强:BYO-VLA 运行时去噪、3D-VLA 引入点云。
-
轨迹优化:Diffusion-VLA 用扩散头生成平滑轨迹;π₀ 采用流匹配提速。
-
成本降低:TinyVLA 知识蒸馏 + 量化,边缘端 30 ms 推理。
3.2.3 主流 VLA 对比
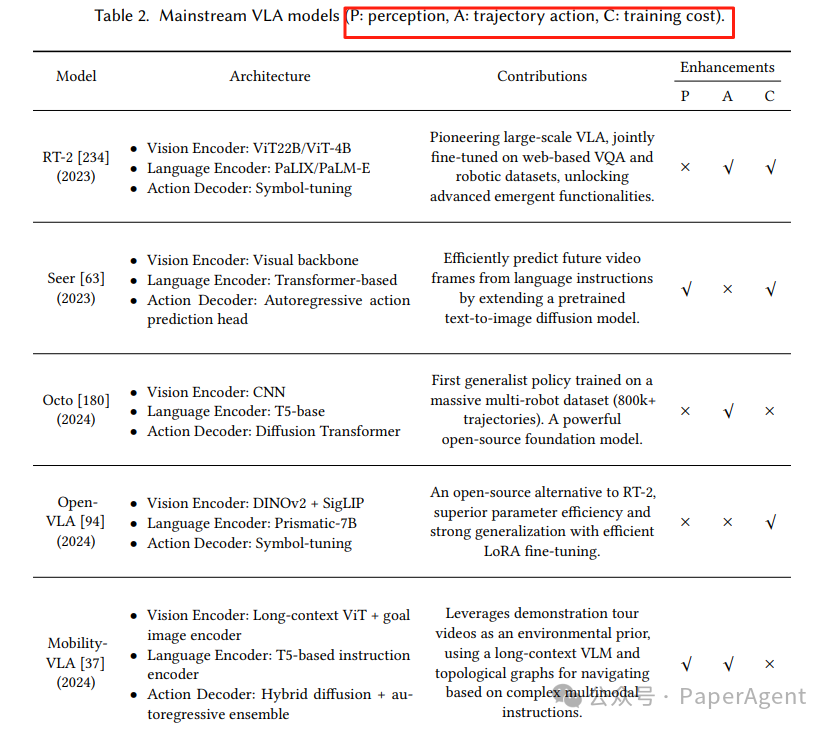
添加图片注释,不超过 140 字(可选)
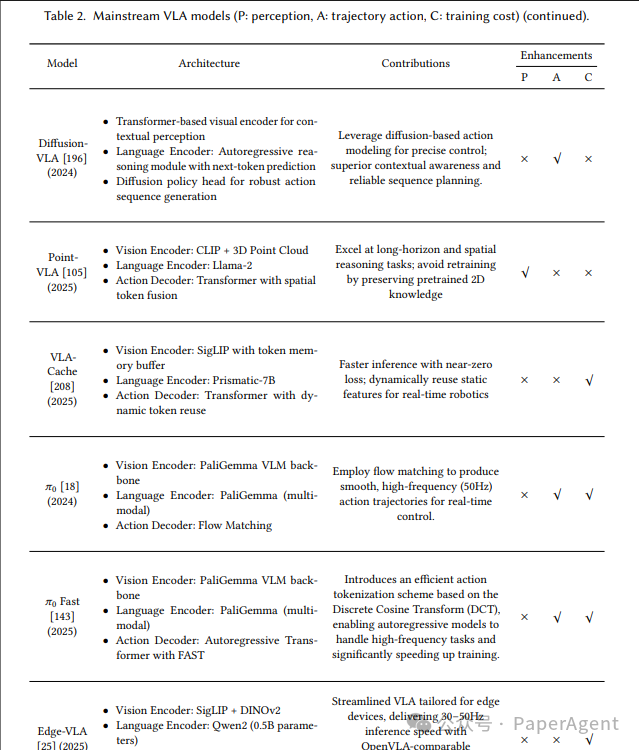
添加图片注释,不超过 140 字(可选)
表2:主流 VLA 一览(节选)
4. 具身学习:从模仿到强化,大模型全面提效
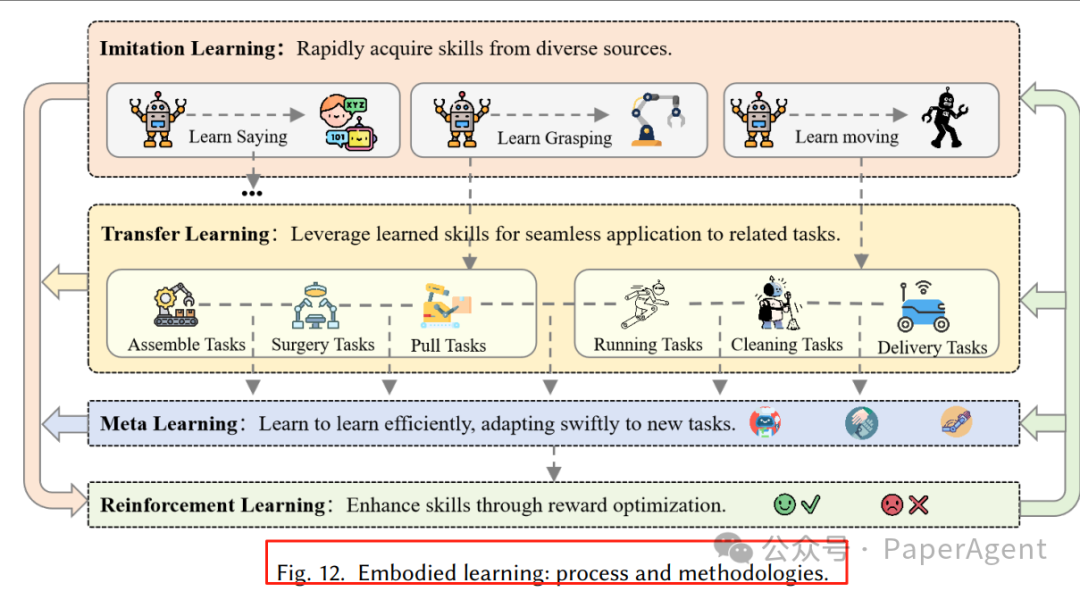
Fig-12 具身学习方法论
图12:模仿学习、RL、迁移学习、元学习协同示意图
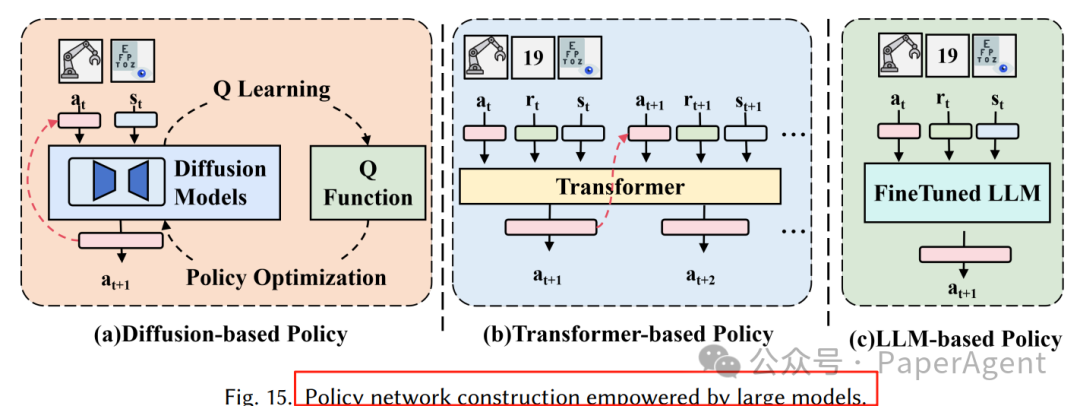
4.1 模仿学习:扩散 & Transformer 双轮驱动
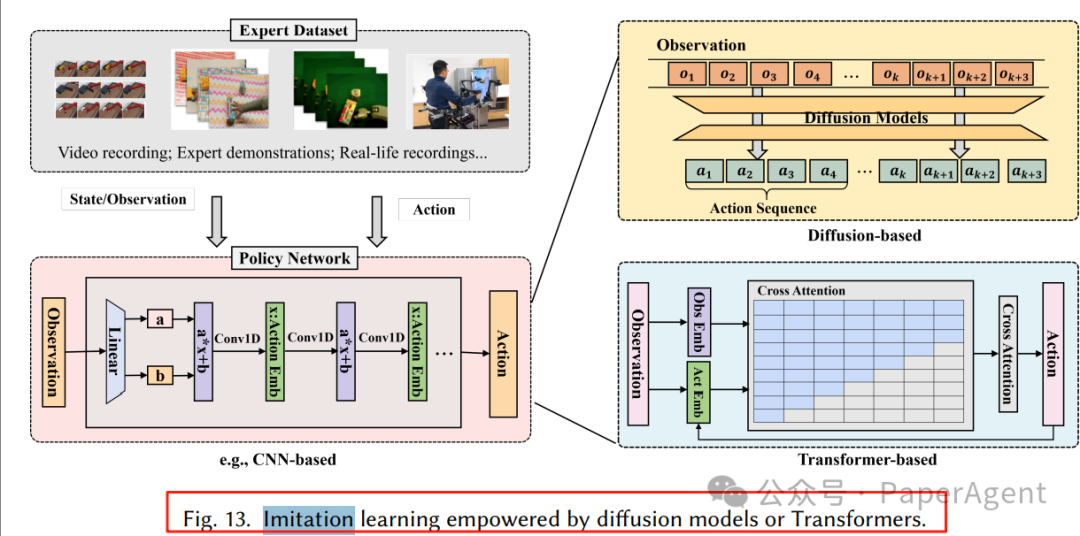
添加图片注释,不超过 140 字(可选)
-
扩散策略:Diffusion Policy、3D-Diffusion 用 U-Net 建模多模态动作分布,抗噪声、长程一致。
-
Transformer 策略:RT-1、ALOHA、Mobile ALOHA 用 Decision Transformer 结构,端到端输出动作序列。
4.2 强化学习:大模型解决两大痛点
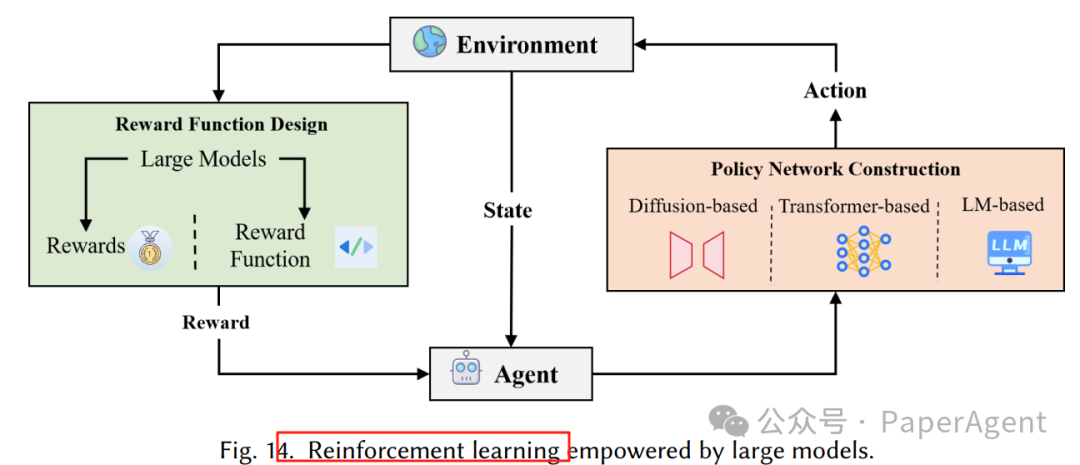
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
5. World Model:决策与学习的新引擎
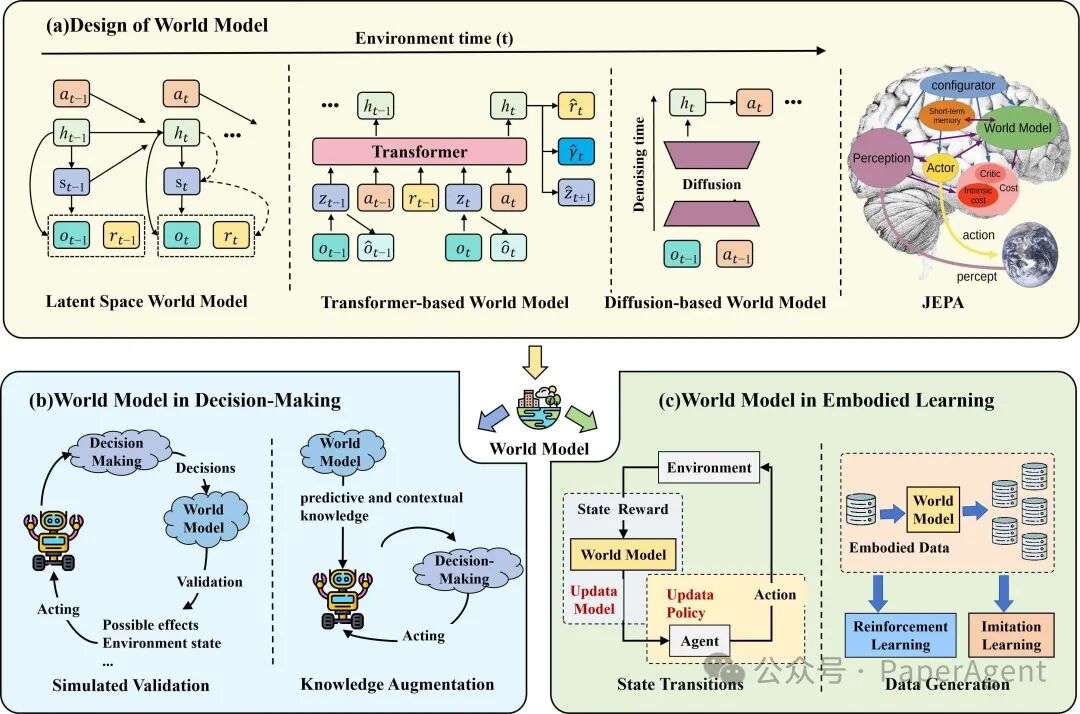
添加图片注释,不超过 140 字(可选)
图16:World Model 在决策与学习中的双重角色
5.1 四大设计路线
-
Latent Space:RSSM → Dreamer 系列,低维潜空间预测。
-
Transformer:Genie、IRIS 用自注意力建模长程依赖。
-
Diffusion:UniPi、Sora 直接在像素空间生成未来帧。
-
JEPA:LeCun 提出非生成式联合嵌入预测架构,强调常识推理。
5.2 两大应用场景
-
决策:在“脑内”模拟验证动作,降低真实交互成本(UniSim、NeBula)。
-
学习:提供虚拟交互环境 + 合成数据,提升样本效率(SynthER、SWIM)。
添加图片注释,不超过 140 字(可选)
微信视频号:sph0RgSyDYV47z6
快手号:4874645212
抖音号:dy0so323fq2w
小红书号:95619019828
B站1:UID:3546863642871878
B站2:UID: 3546955410049087
参考文献链接
https://arxiv.org/pdf/2508.10399Large Model Empowered Embodied AI: A Survey on Decision-Making and Embodied Learning