
Strom集群的安装
1 下载与安装
在主节点hadoop01上进入software目录
cd /usr/software
下载Storm安装包到software目录
wget https://mirrors.aliyun.com/apache/storm/apache-storm-1.2.4/apache-storm-1.2.4.tar.gz
解压Storm安装包到app目录
tar -zxvf apache-storm-1.2.4.tar.gz -C /usr/app
2 配置Storm集群
进入主节点hadoop01的storm的conf目录
cd apache-storm-1.2.4/conf
打开conf目录下的storm.yaml文件
vi storm.yaml
在文件的开头处添加以下内容(注意格式的对其与缩进!!!)
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.########### These MUST be filled in for a storm configuration
# ZooKeeper集群的主机列表
storm.zookeeper.servers:- "hadoop01"- "hadoop02"- "hadoop03"# 设置Storm的HA集群所需,Nimbus的节点列表,至少需要两个成员
nimbus.seeds: ["hadoop01", "hadoop02"]# Storm的web ui默认端口8080与其他程序默认端口容易产生冲突,所以这里需要修改为8081
ui.port: 8081# Storm集群运行时,需要存储状态的路径
storm.local.dir: "/opt/storm/tmp"# workers进程的端口,每个worker进程会使用一个端口来接收消息
supervisor.slots.ports:- 6700- 6701- 6702- 6703# 设置Supervisors运行状态的监控路径,开启对Supervisors的状态监控(可选)
storm.health.check.dir: "healthchecks"# 设置Supervisors健康检查的超时时间(单位:毫秒)
storm.health.check.timeout.ms: 5000########### These may optionally be filled in:
## List of custom serializations
# topology.kryo.register:
# - org.mycompany.MyType
# - org.mycompany.MyType2: org.mycompany.MyType2Serializer
#
## List of custom kryo decorators
# topology.kryo.decorators:
# - org.mycompany.MyDecorator
#
## Locations of the drpc servers
# drpc.servers:
# - "server1"
# - "server2"## Metrics Consumers
## max.retain.metric.tuples
## - task queue will be unbounded when max.retain.metric.tuples is equal or less than 0.
## whitelist / blacklist
## - when none of configuration for metric filter are specified, it'll be treated as 'pass all'.
## - you need to specify either whitelist or blacklist, or none of them. You can't specify both of them.
## - you can specify multiple whitelist / blacklist with regular expression
## expandMapType: expand metric with map type as value to multiple metrics
## - set to true when you would like to apply filter to expanded metrics
## - default value is false which is backward compatible value
## metricNameSeparator: separator between origin metric name and key of entry from map
## - only effective when expandMapType is set to true
# topology.metrics.consumer.register:
# - class: "org.apache.storm.metric.LoggingMetricsConsumer"
# max.retain.metric.tuples: 100
# parallelism.hint: 1
# - class: "org.mycompany.MyMetricsConsumer"
# max.retain.metric.tuples: 100
# whitelist:
# - "execute.*"
# - "^__complete-latency$"
# parallelism.hint: 1
# argument:
# - endpoint: "metrics-collector.mycompany.org"
# expandMapType: true
# metricNameSeparator: "."## Cluster Metrics Consumers
# storm.cluster.metrics.consumer.register:
# - class: "org.apache.storm.metric.LoggingClusterMetricsConsumer"
# - class: "org.mycompany.MyMetricsConsumer"
# argument:
# - endpoint: "metrics-collector.mycompany.org"
#
# storm.cluster.metrics.consumer.publish.interval.secs: 60# Event Logger
# topology.event.logger.register:
# - class: "org.apache.storm.metric.FileBasedEventLogger"
# - class: "org.mycompany.MyEventLogger"
# arguments:
# endpoint: "event-logger.mycompany.org"# Metrics v2 configuration (optional)
#storm.metrics.reporters:
# # Graphite Reporter
# - class: "org.apache.storm.metrics2.reporters.GraphiteStormReporter"
# daemons:
# - "supervisor"
# - "nimbus"
# - "worker"
# report.period: 60
# report.period.units: "SECONDS"
# graphite.host: "localhost"
# graphite.port: 2003
#
# # Console Reporter
# - class: "org.apache.storm.metric2.reporters.ConsoleStormReporter"
# daemons:
# - "worker"
# report.period: 10
# report.period.units: "SECONDS"
# filter:
# class: "org.apache.storm.metrics2.filters.RegexFilter"
# expression: ".*my_component.*emitted.*"
回到app目录下
cd /usr/app
将配置后的storm程序复制到节点hadoop02、hadoop03
scp -r apache-storm-1.2.4/ root@hadoop02:$PWD
scp -r apache-storm-1.2.4/ root@hadoop03:$PWD
在所有节点上打开配置环境文件
vi /etc/profile
在文件末尾添加以下内容
export STORM_HOME=/usr/app/apache-storm-1.2.4
export PATH=$PATH:$STORM_HOME/bin
3 启动集群
进入主节点hadoop01的storm下的bin目录
cd /usr/app/apache-storm-1.2.4/bin
在bin目录下,创建storm启动脚本
vi start-storm.sh
在文件中写入一下内容
#!/bin/bash#nimbus 节点
nimbusServers='hadoop01 hadoop02'
#supervisor 节点
supervisorServers='hadoop01 hadoop02 hadoop03'
#logviewer 节点
logviewerServers='hadoop01 hadoop02 hadoop03'# 启动所有的 nimbus
for nim in $nimbusServers
do
ssh -T $nim <<EOF
storm nimbus >/dev/null 2>&1 &
EOF
echo 从节点 $nim 启动 nimbus...[ done ]
sleep 5
done# 启动所有的 ui
for u in $nimbusServers
do
ssh -T $u <<EOF
storm ui >/dev/null 2>&1 &
EOF
echo 从节点 $u 启动 ui...[ done ]
sleep 5
done# 启动所有节点上的 supervisor
for visor in $supervisorServers
do
ssh -T $visor <<EOF
storm supervisor >/dev/null 2>&1 &
EOF
echo 从节点 $visor 启动 supervisor...[ done ]
sleep 5
done# 启动所有节点上的日志查看服务 logviewer
for logger in $logviewerServers
do
ssh -T $logger <<EOF
storm logviewer >/dev/null 2>&1 &
EOF
echo 从节点 $logger 启动 logviewer...[ done ]
sleep 5
done
在bin目录下,创建storm关停脚本文件
vi stop-storm.sh
在文件中参照以下格式写入代码
#!/bin/bash#nimbus 节点
nimbusServers="hadoop01 hadoop02"
#supervisor 节点
supervisorServers="hadoop01 hadoop02 hadoop03"# 停止所有的 nimbus 和 ui
for nim in $nimbusServers
do
echo 从节点 $nim 停止 nimbus 和 ui...[ done ]
ssh $nim "kill -9 \`ssh $nim ps -ef | grep nimbus | awk '{print \$2}' | head -n 1\`" >/dev/null 2>&1
ssh $nim "kill -9 \`ssh $nim ps -ef | grep UIServer | awk '{print \$2}' | head -n 1\`" >/dev/null 2>&1
done# 停止所有的 supervisor 和 logviewer
for visor in $supervisorServers
do
echo 从节点 $visor 停止 supervisor 和 logviewer...[ done ]
ssh $visor "kill -9 \`ssh $visor ps -ef | grep supervisor | awk '{print \$2}' | head -n 1\`" >/dev/null 2>&1
ssh $visor "kill -9 \`ssh $visor ps -ef | grep logviewer | awk '{print \$2}' | head -n 1\`" >/dev/null 2>&1
done
在bin目录下执行以下命令修改脚本文件的权限
chmod u+x c
chmod u+x stop-storm.sh
启动storm
start-storm.sh
启动完毕后在各节点上执行jps命令
hadoop01中的进程情况如下

hadoop02中的进程情况如下
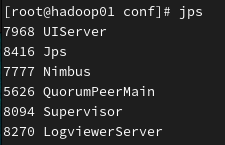
hadoop03中的进程情况如下

在浏览器中访问hadoop01:8081可打开stormUI界面如下:

在主节点hadoop01上执行以下命令可以关闭Storm集群
stop-storm.sh
如果jps启动后没有显示进程:
可能是conf目录下的strom.yaml的缩进不正确,修改缩进就行!