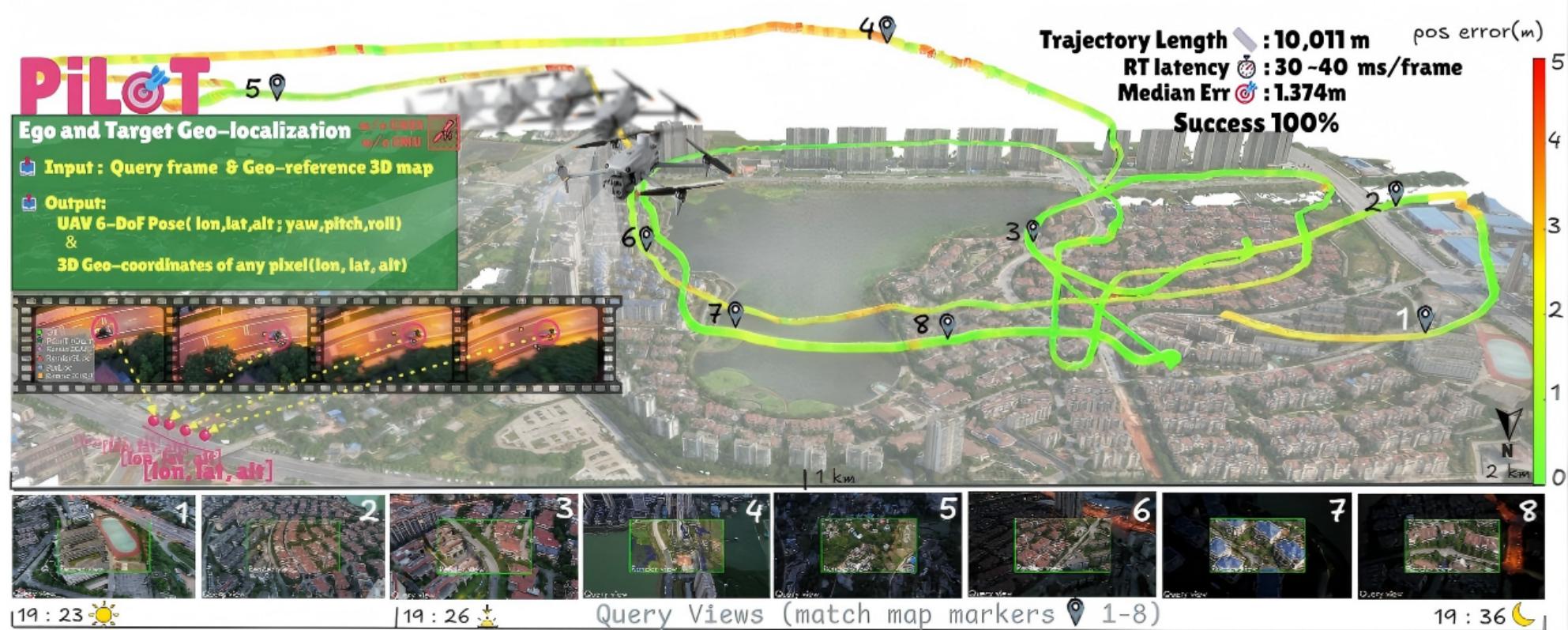
PiLoT 系统概述
该系统在没有 GNSS 和 IMU 信号的情况下,在昼夜和跨季节变化中取得了 1.37 米的中值误差、30
∼ 40 毫秒的每帧延迟以及 100% 的成功率。
系统以实时视频帧和地理参考的 3D 地图作为输入,输出
- 无人机的 6-DoF 位姿
- 任何目标像素的 3D 地理坐标
PiLoT 在 10 公里无人机轨迹上实现了无漂移、实时、长期的自我和目标地理定位,误差以颜色编码(绿色:低,红色:高)。
与传统定位方式的区别
传统方法依赖于解耦的流水线,该流水线融合GNSS和视觉惯性里程计(VIO)来进行自身姿态估计,并使用激光测距仪等主动传感器进行目标定位。(例如,大疆 Matrice 4 系列)
然而,这些方法在GNSS受限的环境中容易失效。
PiLoT通过将实时视频流直接与地理参考的3D地图进行配准,打破了这一范式。
关键技术点
为了实现鲁棒、准确和实时的性能,论文中提出了三项关键贡献:
-
一个双线程引擎,将地图渲染与核心定位线程分离,确保低延迟同时保持无漂移的精度;
-
一个具有精确几何标注(相机姿态、深度图)的大规模合成数据集。该数据集能够训练一个轻量级网络,该网络可以以零样本的方式从模拟数据泛化到真实数据;
-
一个联合神经引导随机梯度优化器(JNGO),即使在剧烈运动下也能实现鲁棒收敛。
相关工作
1. 基于UAV的自我定位
基于UAV的自我定位旨在估计全局坐标中的6自由度姿态。为了实现无漂移定位,一种主流范式是将UAV的视角与地理参考地图进行配准。
虽然SLAM和VIO方法在局部状态估计方面具有鲁棒性,但在没有全局参考的情况下容易发生漂移。
SLAM(Simultaneous Localization and Mapping,同时定位与建图)
无人机一边飞,一边利用相机、激光雷达等传感器构建环境地图,同时估计自己的位置。
例如:无人机刚起飞时把当前位置设为 (0,0,0),之后靠连续观测推断自己飞到了哪里。
VIO(Visual-Inertial Odometry,视觉惯性里程计)
结合相机和IMU(加速度计、陀螺仪)估计运动轨迹。
本质上属于“增量估计”:当前位置 = 上一时刻位置 + 测出来的运动量。
而论文中采用的是Pixel-to-3D框架,通过大规模、基于地图的训练来减轻初始化敏感性并缩小航空领域差距。
早期方法使用二维卫星图像,仅能获得3自由度姿态(纬度、经度和偏航角),并且仅限于二维地图和简化的俯视假设。
为了恢复完整的6自由度姿态,近期研究转向了三维地图。这些方法通常通过检索或传感器先验来初始化姿态,然后通过匹配式或直接对齐方法进行优化。匹配式方法: 对于资源受限的无人机来说计算成本过高且耗时。
直接对齐方法: 如光度优化,对室外光照高度敏感,而特征度量优化提供了更好的鲁棒性,但仍然对初始化敏感,并且在航空无人机视角下的泛化能力较差。
2. 基于UAV的目标地理定位
目标是从图像中确定目标的3D世界坐标。
一种主要方法依赖于几何原理,结合相机模型和无人机姿态来推断目标坐标。该方法对姿态估计的质量非常敏感。为了提高精度,基于3D地图的地理定位已成为一种主流方法,采用渲染匹配和DSM投影等技术来获得精确的目标坐标。尽管这些方法精度很高,但通常受限于计算成本高昂的渲染匹配或与非实时自我定位管线的紧密耦合。
这使得它们无法实现动态目标应用所需的毫秒级响应,而该论文中的方法正是避免了以上的问题。
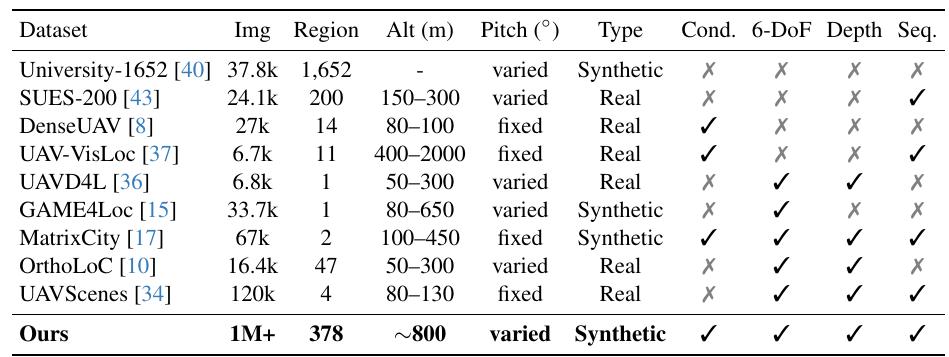
3.面向UAV的视觉定位数据集
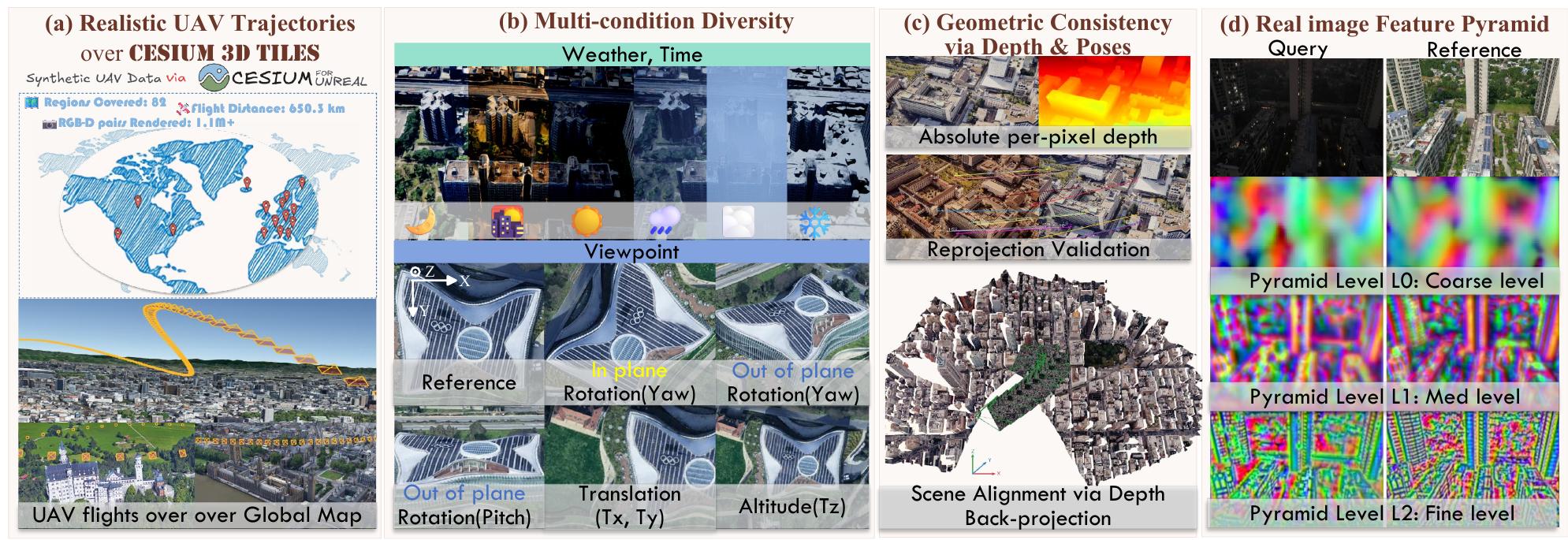
为了解决结构化无人机训练数据缺乏的问题,该研究团队构建了一个全自动化的 AirSim–Cesium–Unreal 流程,将大规模地理空间数据转换为具有精确 6 自由度姿态和深度图的地理对齐图像。
方法论
给定:
一个地理参考的三维地图
一个具有已知内参的单目视频流
第一帧的单个位姿先验
→在没有 GNSS 和 IMU 辅助的情况下基于无人机进行自我定位和目标地理定位的问题。
目标:
1. 知道无人机的位置
2. 知道无人机看到的东西的位置
PiLoT 的双线程框架
对于序列视频定位,一种朴素的策略是从最后一帧渲染参考视图,并对当前帧进行姿态精炼。
即:利用上一帧定位结果生成预测画面,再和当前真实画面对齐,通过优化得到当前帧位姿。
→这种线性依赖会产生固有的时间瓶颈,导致定位引擎在渲染任务完成之前被迫停滞。
与这种传统的线性流水线不同,论文中提出了一种解耦的双线程架构,该架构并行同步地图渲染和姿态优化。
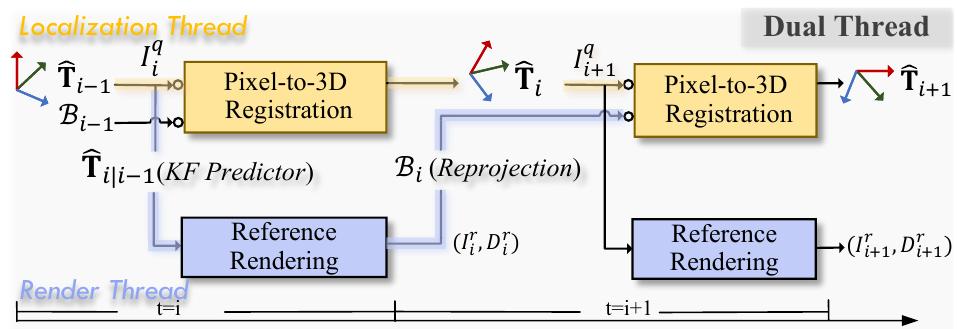
该系统策略性地渲染一个参考锚点,并利用一对多的策略。该方法利用共享渲染来优化姿态假设的集合,从而在没有多个参考视点的情况下实现广泛的搜索范围。
也就是利用一个视图,进行多个位姿假设。
两个线程按如下方式协调此过程:
-
渲染线程:
该线程运行以提供用于定位的地理配准视图。渲染线程首先使用恒定速度卡尔曼滤波器(KF)从上一个估计值预测参考位姿。从预测的位姿开始,渲染一个新的参考视图,并将其深度有效的像素反投影到世界坐标系中,形成一组三维地理锚点,并且打包成约束传送给本地线程。 -
定位线3程:
Pixelto-3D Registration 流水线针对每个新的查询帧 执行。它首先使用轻量级提取器从查询视图和参考视图 中提取多尺度特征和不确定性图。以参考束为锚点,JNGO 优化器随后执行全局探索与局部利用,以进行广域搜索并找到全局一致的姿态估计。随后将此新姿态传回渲染线程,为下一个周期准备参考束。
关键点:
- 渲染提前一帧准备
- 一个渲染生成多个位姿预测
Pixel-to-3D Registration
像素到三维配准
无人机特定特征提取
-
轻量化网络。
采用了一个现成的MobileOne-S0编码器(深度=3,ImageNet初始化),并结合了一个紧凑的U-Net解码器,该解码器由查询和参考分支共享。给定一张H × W的RGB图像,它在1/4(粗糙)、1/2(中等)和1(精细)分辨率下输出一个三层金字塔,具有紧凑的通道宽度C=32,从而得到查询特征和不确定性以及参考特征和不确定性。 -
使用大规模数据集进行训练。
训练此神经网络依赖于具有密集深度和精确相机姿态的大规模数据集以进行几何监督。论文引入了一个新的大规模合成数据集,该数据集专门设计用于支持几何感知学习。(该团队开发了一个基于AirSim-Cesium-Unreal Engine流水线的全自动化模拟器,用于生成该数据集。)Unreal:负责逼真画面
Cesium:负责全球真实地图
AirSim:负责无人机飞行模拟要求大模型学习到3D特征,而非与亮度强相关的色彩特征。
联合神经引导随机梯度优化器
激进的无人机运动通常会引起大的帧间位移,这对容易陷入局部最优的、传统基于梯度的优化器提出了重大挑战。为了解决这个问题,论文引入了 JNGO,它通过协同全局探索和局部开发来驾驭具有挑战性的非凸优化地形。
-
旋转感知假设生成
基于无人机影像中 视在像素位移 对旋转 比 对平移 更敏感的观察,论文中设计了一种旋转感知采样策略,通过自适应地扩大沿运动敏感轴(俯仰和偏航)的搜索范围来生成假设。
除此以外,还有:- 大范围采样避免局部最优
- 多个假设并行优化
- 先粗定位再细调
- 对特征优化,不直接优化RGB
- 自动降低不可靠区域影响
的处理。