
论文信息
论文标题:Structure-aware Propagation Generation with Large Language Models for Fake News Detection
论文翻译:基于大型语言模型的结构感知传播生成用于虚假新闻检
论文作者:陈梦阳、魏灵伟、周伟、胡松林
论文来源:EMNLP 2025
发布时间:2025
论文地址:
论文代码:https://github.com/ICTMCG/GenFEND总结:
1 研究动机&&研究背景
-
研究问题1:基于传播的虚假新闻检测方法在传播数据不完整时性能显著下降,如何缓解该问题?
研究背景:现有虚假新闻检测的传播类方法,通过建模新闻与评论的时间序列、传播树 / 传播图等拓扑结构捕捉传播模式,但受限于社交媒体数据收集的局限性及恶意用户互动等因素,实际场景中常面临传播数据不完整的问题,导致这类方法检测效果大幅受损。 -
研究问题2:现有基于大语言模型(LLM)生成合成传播的方法,因忽略真实传播的结构模式,生成内容与真实传播存在语义 - 结构不匹配,如何提升合成传播的真实性与结构一致性?
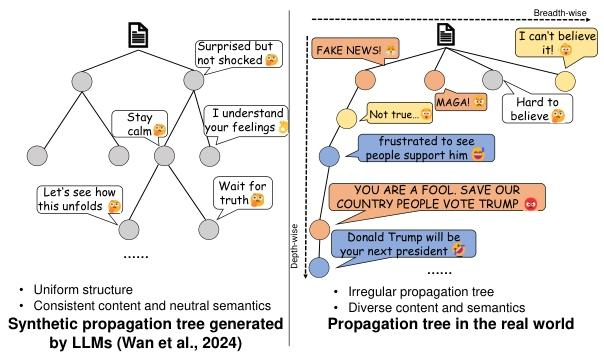
研究背景:近年 LLM 被用于通过角色扮演生成合成传播以缓解数据稀缺,但这类方法仅关注语义层面,生成的传播树存在结构过于均匀、缺乏真实传播的不规则分支与层级深度等问题,且内容情感多样性不足、语气趋于通用化,与真实传播的结构动态和语义特征存在显著差异,难以有效支撑下游虚假新闻检测(尤其在早期检测、跨平台泛化场景)。 -
语言模型(LLM)生成合成传播的方法,因忽略真实传播的结构模式,生成内容与真实传播存在语义 - 结构不匹配,如何提升合成传播的真实性与结构一致性?
研究背景:近年 L义 - 结构不匹
2 介绍
LLM 生成合成传播的现状与核心缺陷
3 方法
3.1 核心概述(Overview)
框架
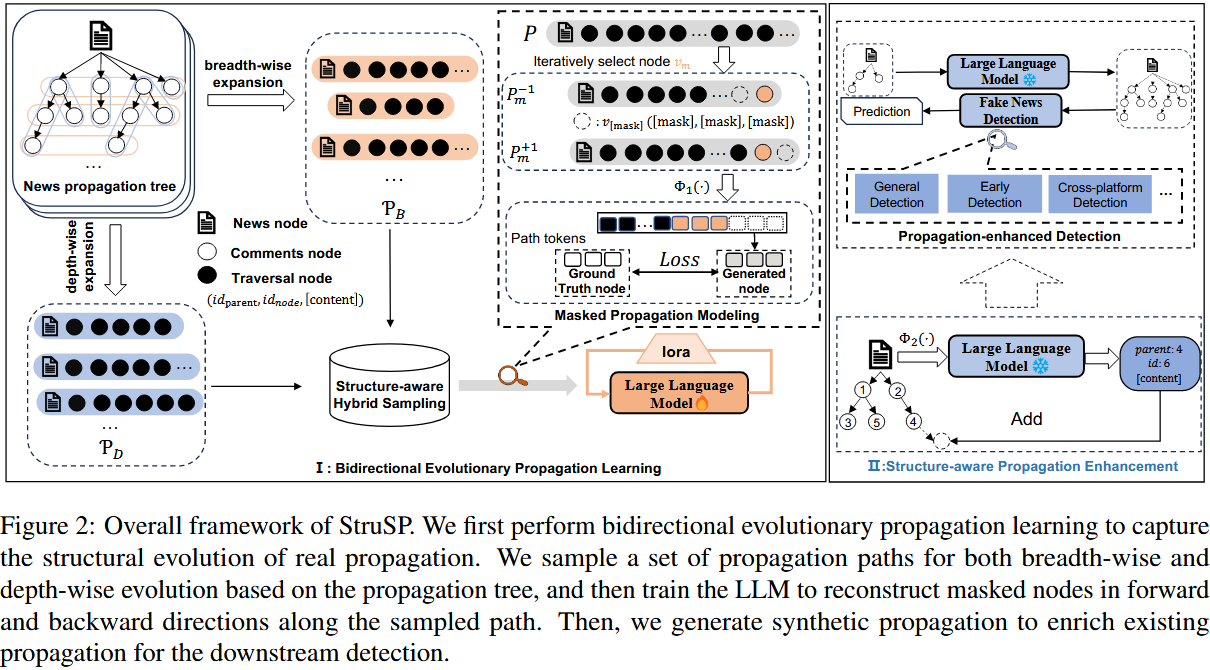
3.2 双向进化传播学习(Bidirectional Evolutionary Propagation Learning)
3.2.1 结构感知混合采样(Structure-aware Hybrid Sampling)
每条传播路径 $P \in P = P_B \cup P_D$ 表示为节点序列:
$P = (v_0, v_1, ..., v_{|P|})$
其中每个节点 $v_i$ 用三元组表示: $v_i = <id_{parent}, i, c_i>$
3.2.2 掩码传播建模(Masked Propagation Modeling)
3.3 结构感知传播增强(Structure-aware Propagation Enhancement)
-
序列转换:将给定的不完整传播 $G_0'$ 按时间顺序转换为传播序列 $P_{\mathcal{G}', 0}$;
-
迭代生成:训练后的 LLM 基于前序传播序列,通过提示模板 Φ2(⋅) 生成下一个评论节点:
-
公式
-
$v_i' = LLM(\Phi_2(P_{\mathcal{G}', i-1})) $
$P_{\mathcal{G}', i} = P_{\mathcal{G}', i-1} \cup \{v_i'\} $
-
-
提示模板:Given the propagation tree: ${P_{G', i-1}}$, please predict the next comment node in a JSON format as same as other nodes, i.e., {parent node index: num, node index: num, content: text}.
-
-
终止条件:生成节点数量达到预设值 $k$(实验中设为 $30$)。【迭代生成】
迭代生成算法
3.4 传播增强检测(Propagation-enhanced Detection)
$\hat{y} = f(\mathcal{G}_k')$
4 实验
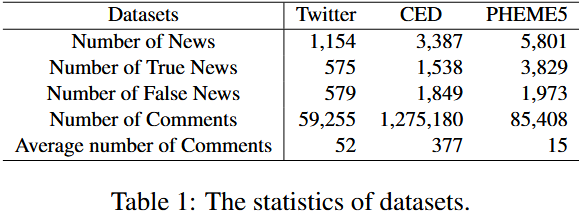
4.1 数据集(Datasets)
4.2 Baselines(基准模型)
| 模型名称 | 模型类型 | 核心原理 |
|---|---|---|
| BERT | 文本内容基模型 | 预训练语言模型,取最后一层输出输入分类器,仅依赖新闻文本特征 |
| dEFEND | 文本 + 评论基模型 | 设计句子 - 评论共注意力子网络,融合新闻内容与评论特征进行检测 |
| GCN | 传播结构基模型 | 对新闻传播图执行图卷积操作,学习结构特征用于分类 |
| Bi-GCN | 传播结构基模型 | 基于传播图建模双向传播关系,捕捉更丰富的结构依赖 |
| EBGCN | 传播结构基模型 | 采用贝叶斯图卷积网络,从不确定传播中学习结构特征 |
| RAGCL | 传播结构基模型 | 通过自适应传播图对比学习,学习鲁棒的谣言表示 |
| LLM-text | LLM 基检测模型 | 仅输入新闻文本,让 LLM 直接进行虚假新闻分类 |
| LLM-comments | LLM 基检测模型 | 输入新闻文本 + 真实评论,让 LLM 进行分类 |
| LLM-propagation | LLM 基检测模型 | 输入完整传播信息(新闻 + 评论 + 传播结构),让 LLM 进行分类 |
| 模型名称 | 核心原理 |
|---|---|
| GenFEND | 定义 30 个特定用户画像(性别、年龄、教育水平),让 LLM 扮演这些用户生成评论 |
| DELL | 通过迭代过程让 LLM 扮演指定用户,可直接评论新闻或回复已有评论,生成传播结构 |
| LLM(未微调) | 直接使用未经过 BEP 训练的 LLaMa3-8B-Instruct,按 SPE 模块流程生成传播 |
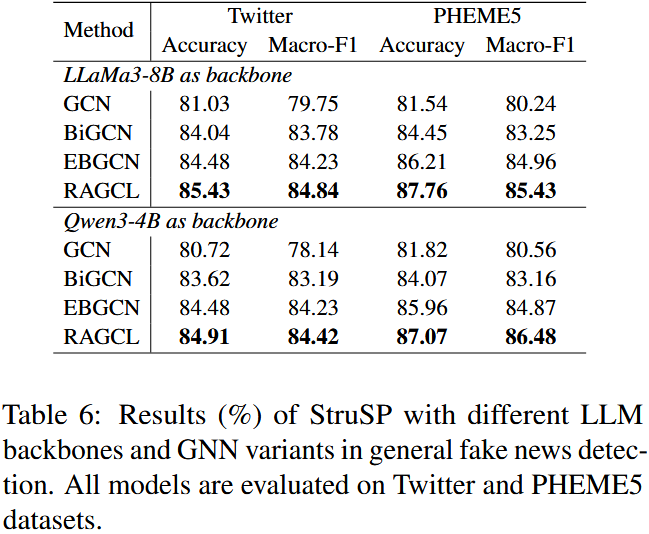
4.3 实验内容、结果与结论
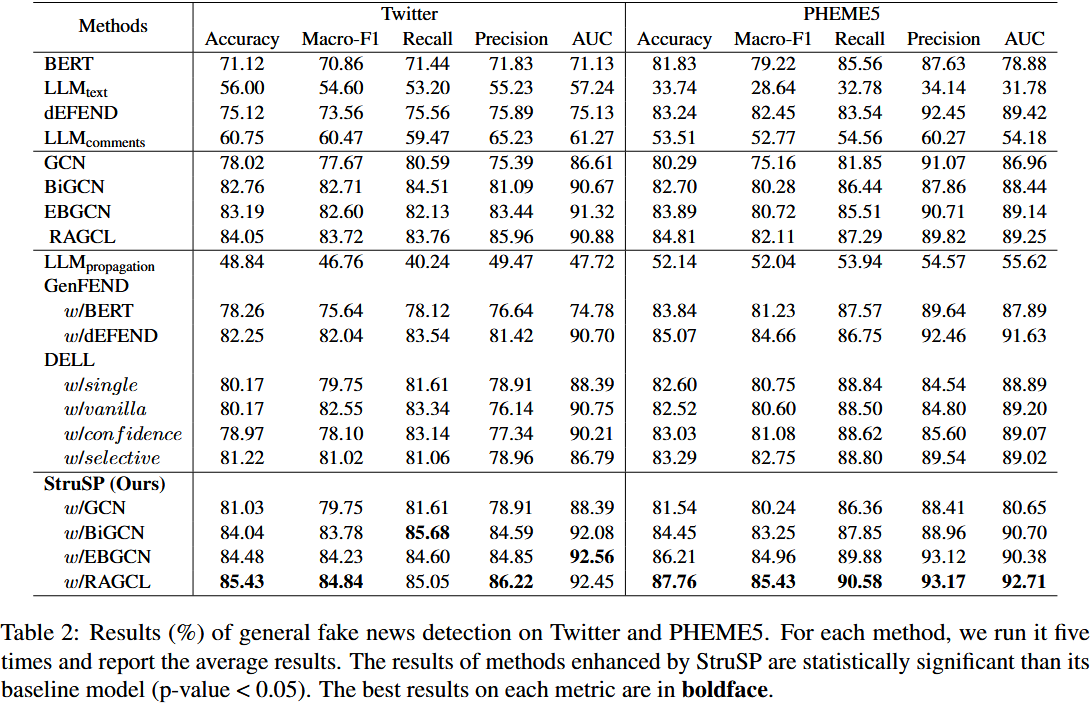
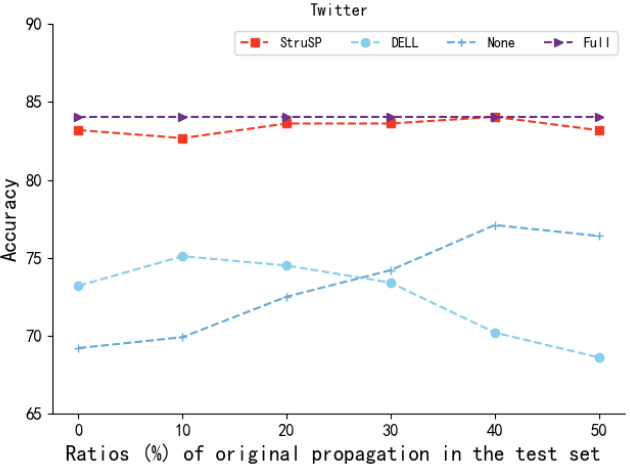
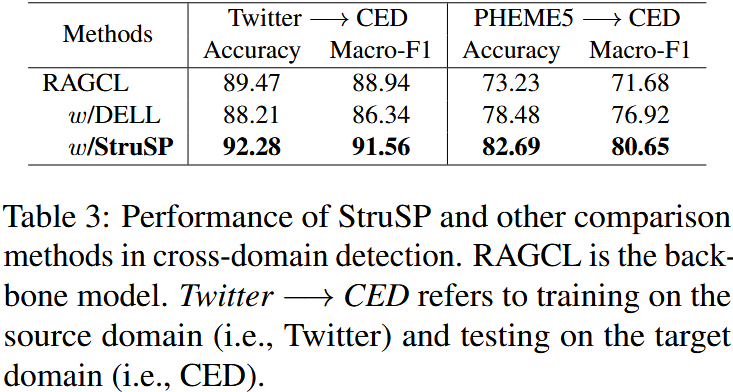
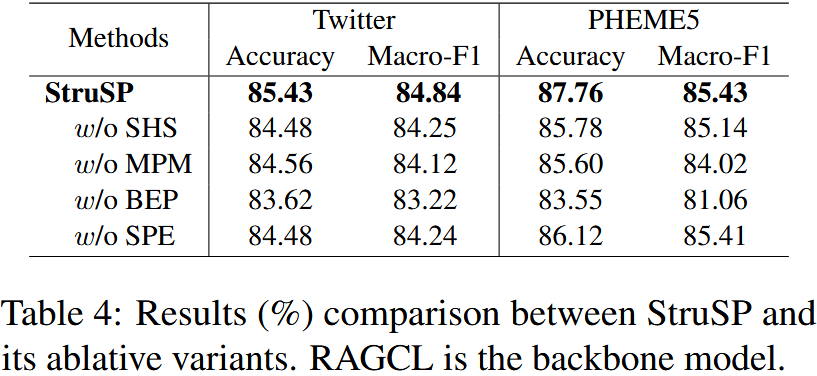
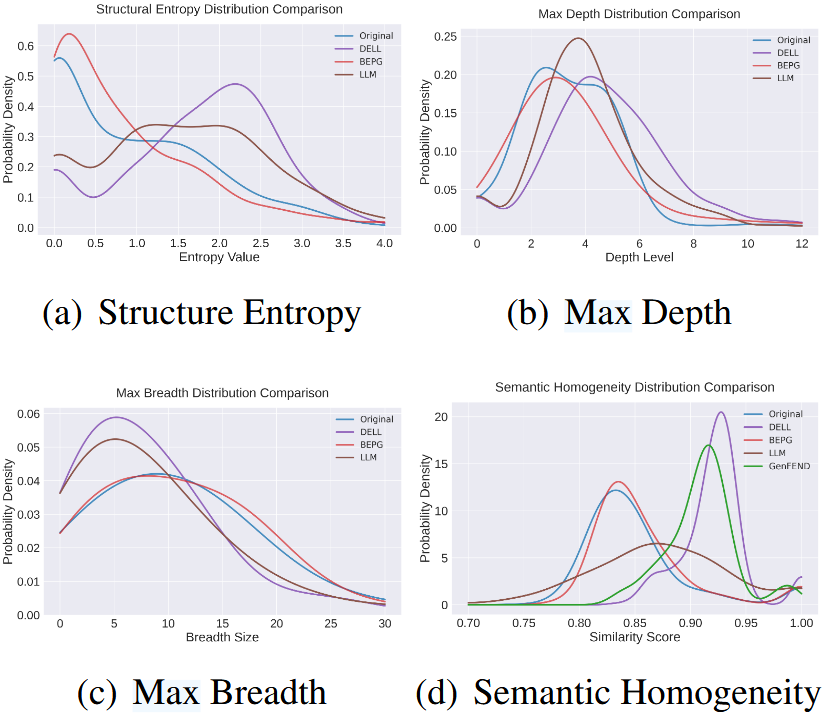
图 4:在合并的 Twitter 和 PHEME5 数据集上进行的微观层面传播分析结果。不同方法生成的传播在结构熵、实例级深度 / 广度以及语义同质性方面的分布情况
参考
- Let Silence Speak: Enhancing Fake News Detection with Generated Comments from Large Language Models
- DELL: Generating reactions and explanations for LLM-based misinformation detection
- From skepticism to acceptance: Simulating the attitude dynamics toward fake news
- Can llms simulate social media engagement? a study on action-guided response generation
- Evidence-driven retrieval augmented response generation for online misinformation
- Structure-aware Propagation Generation with Large Language Models for Fake News Detection
- Collaboration and Controversy Among Experts: Rumor Early Detection by Tuning a Comment Generator