
【大数据】水质数据可视化分析实用的系统 计算机工程 Hadoop+Spark环境配置 数据科学与大信息技术 附源码+文档+讲解
2025-10-25 20:34 tlnshuju 阅读(0) 评论(0) 收藏 举报一、个人简介
二、系统介绍
大数据框架:Hadoop+Spark(Hive需要定制修改)
构建语言:Java+Python(两个版本都承受)
数据库:MySQL
后端框架:SpringBoot(Spring+SpringMVC+Mybatis)+Django(两个版本都支持)
前端:Vue+Echarts+HTML+CSS+JavaScript+jQuery
水质资料可视化分析系统是一个面向水环境监测与决策支持的专业平台,基于Hadoop+Spark的大数据计算能力、Django后端服务与Vue+ElementUI+ECharts的交互可视化层,承担从海量传感器/监测点内容的采集、清洗、计算、分析到结果持久化与可视化展示的全流程任务。系统以Spark做为主力计算引擎负责批量数据处理与流式清洗,启用Spark SQL做完复杂时序与空间聚合,必要时将数据下沉为Pandas以支持部分高阶算法和统计检验;MySQL用于业务元数据与分析结果存储,前端通过RESTful接口请求后端聚合视图、关联网络、风险评估与大屏展示数据,ECharts负责渲染时序曲线、热力/地理图和关联图谱。功能模块包括综合统计(按站点/时间/污染物维度的均值、峰值、超标率等指标)、污染物关联分析(相关矩阵、显著性检验与网络边列表,用于识别可能的污染联动)、水质安全评估(基于标准阈值和加权指标计算水质指数并给出分级告警)、特定污染溯源分析与高级算法模块(支持基于样本的异常检测与趋势预测),以及用于指挥调度的大屏可视化。整个体系注重数据流的可追溯性与模块化扩展,便于在毕业设计阶段完成一套可运行、可验证的端到端方案,同时保留将来接入更多传感源或替换算法的柔性接口。
三、视频解说
【大数据】水质资料可视化分析系统 计算机项目 Hadoop+Spark环境设置 数据科学与大数据技术 附源码+文档+讲解
四、部分功能展示




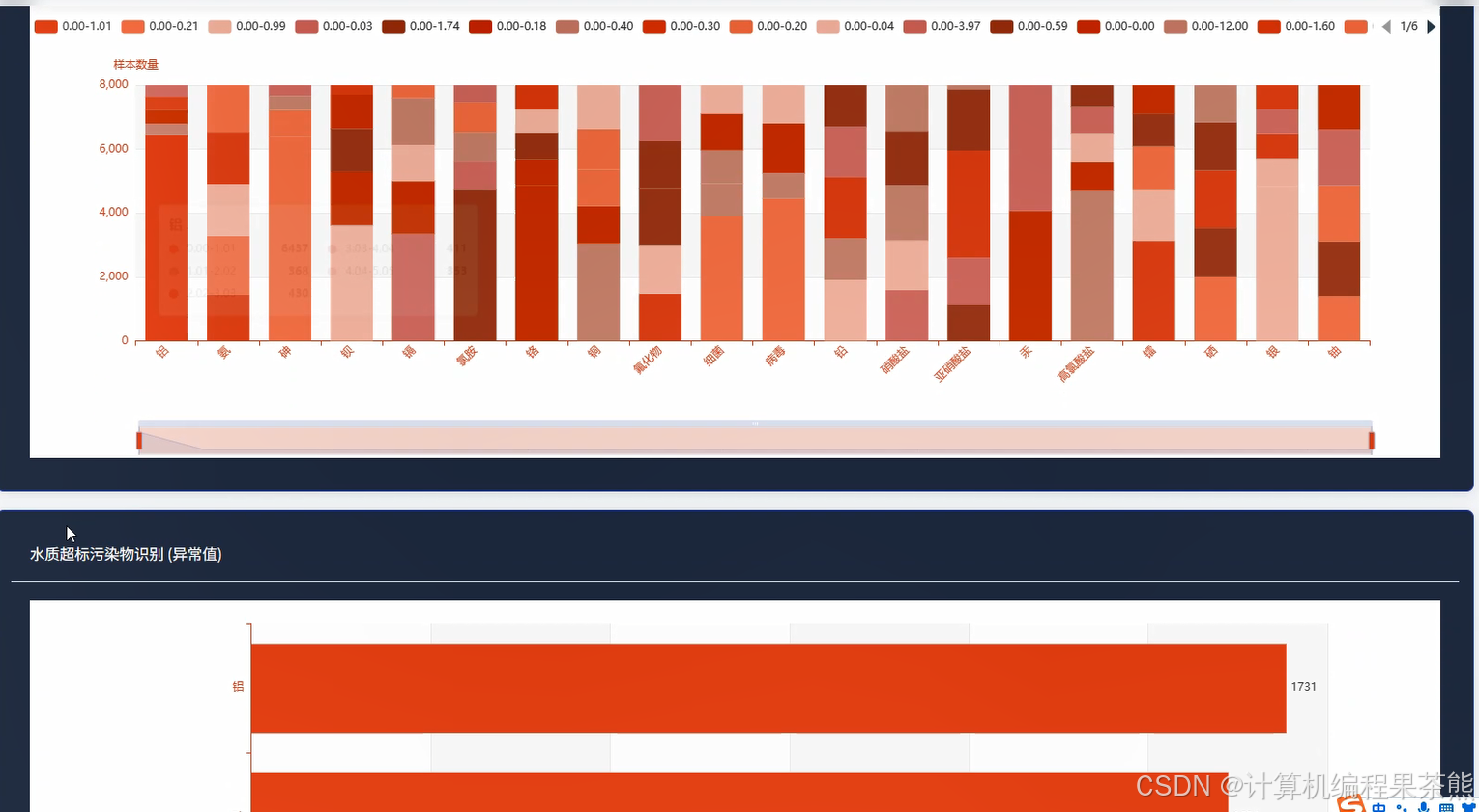

五、部分代码展示
from pyspark.sql import SparkSession,functions as F
import pandas as pd
import numpy as np
from sqlalchemy import create_engine
from scipy import stats
spark=SparkSession.builder.appName("水质数据可视化分析系统").config("spark.sql.shuffle.partitions","200").getOrCreate()
engine=create_engine("mysql+pymysql://user:password@host:3306/dbname?charset=utf8mb4")
def aggregate_statistics(spark,hdfs_path,start_date=None,end_date=None,out_table="agg_statistics"):df=spark.read.option("header","true").option("inferSchema","true").parquet(hdfs_path)if start_date and end_date:df=df.filter((F.col("timestamp")>=F.lit(start_date))&(F.col("timestamp")<=F.lit(end_date)))df=df.withColumn("date",F.to_date("timestamp"))pivot_df=df.groupBy("station_id","date").pivot("pollutant").avg("value")agg_cols=[c for c in pivot_df.columns if c not in ("station_id","date")]exprs=[F.avg(c).alias(c+"_avg") for c in agg_cols]+[F.max(c).alias(c+"_max") for c in agg_cols]+[F.min(c).alias(c+"_min") for c in agg_cols]stats_df=pivot_df.groupBy("station_id").agg(*exprs)exceed_df=df.select("station_id","date","pollutant","value").join(spark.createDataFrame([(p,0) for p in []],["p","dummy"]),F.lit(True),"left")stats_df=stats_df.withColumn("computed_at",F.current_timestamp())win=F.windowrolling_df=pivot_dffor c in agg_cols:rolling_df=rolling_df.withColumn(c+"_7d_avg",F.avg(F.col(c)).over(Window.partitionBy("station_id").orderBy(F.col("date").cast("long")).rowsBetween(-6,0)))pdf=stats_df.toPandas()if not pdf.empty:pdf["top_pollutant"]=pdf[[col for col in pdf.columns if col.endswith("_avg")]].idxmax(axis=1).str.replace("_avg","")pdf.to_sql(out_table,engine,if_exists="append",index=False)return {"status":"ok","rows":len(pdf)}
def pollutant_correlation_analysis(spark,hdfs_path,pollutant_list=None,output_table="pollutant_correlation"):df=spark.read.option("header","true").option("inferSchema","true").parquet(hdfs_path)df=df.withColumn("date",F.to_date("timestamp"))if pollutant_list:df=df.filter(F.col("pollutant").isin(pollutant_list))wide=df.groupBy("station_id","date").pivot("pollutant").avg("value")cols=[c for c in wide.columns if c not in ("station_id","date")]wide=wide.fillna(value=0)size=wide.count()sample_pdf=wide.toPandas()if sample_pdf.shape[0]>50000:sample_pdf=sample_pdf.sample(n=50000,random_state=42)numeric=sample_pdf[cols].replace([np.inf,-np.inf],np.nan).dropna(axis=1,how="all").dropna(axis=0,how="any")if numeric.shape[1]<2 or numeric.shape[0]<10:return {"status":"insufficient_data"}pearson=numeric.corr(method="pearson")spearman=numeric.corr(method="spearman")edges=[]cols_list=list(numeric.columns)for i in range(len(cols_list)):for j in range(i+1,len(cols_list)):x=numeric.iloc[:,i].valuesy=numeric.iloc[:,j].valuestry:r,p=stats.pearsonr(x,y)except Exception:r,p=(np.nan,np.nan)edges.append({"p1":cols_list[i],"p2":cols_list[j],"pearson_r":float(r) if not np.isnan(r) else None,"p_value":float(p) if not np.isnan(p) else None})edges_df=pd.DataFrame(edges)if not edges_df.empty:edges_df.to_sql(output_table,engine,if_exists="replace",index=False)corr_payload={"pearson_matrix":pearson.fillna(0).to_dict(),"spearman_matrix":spearman.fillna(0).to_dict(),"edges":edges_df.to_dict(orient="records")}return corr_payload
def water_quality_safety_analysis(spark,hdfs_path,standards,weights=None,out_table="wqi_results"):df=spark.read.option("header","true").option("inferSchema","true").parquet(hdfs_path)df=df.withColumn("date",F.to_date("timestamp"))wide=df.groupBy("station_id","date").pivot("pollutant").avg("value")pdf=wide.toPandas().fillna(np.nan)pollutant_cols=[c for c in pdf.columns if c not in ("station_id","date")]if weights is None:weights={p:1.0 for p in pollutant_cols}scores=[]for idx,row in pdf.iterrows():station=row["station_id"]date=row["date"]total_w=0.0total_score=0.0exceed_list=[]for p in pollutant_cols:val=row.get(p)std=standards.get(p)if pd.isna(val) or std is None or std==0:continuescore=100*(1.0-(val/float(std)))if score<0:score=0.0if score>100:score=100.0w=weights.get(p,1.0)total_score+=score*wtotal_w+=wif val>std:exceed_list.append({"pollutant":p,"value":float(val),"standard":float(std)})wqi=(total_score/total_w) if total_w>0 else Noneif wqi is None:category="unknown"elif wqi>=90:category="优"elif wqi>=70:category="良"elif wqi>=50:category="轻度污染"else:category="重度污染"scores.append({"station_id":station,"date":date,"wqi":float(wqi) if wqi is not None else None,"category":category,"exceedances":exceed_list})result_df=pd.DataFrame(scores)if not result_df.empty:result_df.to_sql(out_table,engine,if_exists="append",index=False)alarms=result_df[result_df["wqi"]<50]if not alarms.empty:alarms.to_sql(out_table+"_alarms",engine,if_exists="append",index=False)return {"computed":len(result_df),"alarms":len(alarms)}六、部分文档展示

七、END
文末获取源码联系计算机编程果茶熊