
作业①:
– 要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
1)代码内容:
--------------------------------------------------
点击查看代码
import sqlite3
import urllib.request
from bs4 import BeautifulSoup
from datetime import datetimedef create_table():"""创建天气数据表[1](@ref)"""with sqlite3.connect("beijing_weather.db") as conn:conn.execute('''CREATE TABLE IF NOT EXISTS weathers (wDate TEXT PRIMARY KEY,wWeather TEXT,wTemp TEXT)''')def get_beijing_weather():"""获取北京天气数据[1,3](@ref)"""url = "http://www.weather.com.cn/weather/101010100.shtml"try:# 发送请求[3](@ref)response = urllib.request.urlopen(url, timeout=10)soup = BeautifulSoup(response, "html.parser")weather_data = []# 获取7天天气数据[4](@ref)for day in soup.select("ul.t.clearfix li")[:7]:date = day.select_one('h1').text.strip()weather = day.select_one('p.wea').text.strip()# 温度提取[2](@ref)high_temp = day.select_one('p.tem span')low_temp = day.select_one('p.tem i')temp = f"{high_temp.text}/{low_temp.text.replace('℃', '')}℃" if high_temp else low_temp.textweather_data.append((date, weather, temp))print(f"{date}: {weather} {temp}")return weather_dataexcept Exception as e:print(f"获取天气数据失败: {e}")return Nonedef save_weather(data):"""保存天气数据[1](@ref)"""with sqlite3.connect("beijing_weather.db") as conn:for date, weather, temp in data:conn.execute("INSERT OR REPLACE INTO weathers VALUES (?, ?, ?)",(date, weather, temp))def show_weather():"""显示天气数据[3](@ref)"""with sqlite3.connect("weather.db") as conn:rows = conn.execute("SELECT * FROM weathers ORDER BY wDate").fetchall()print(f"\n{'日期':<12}{'天气':<10}{'温度':<10}")print("-" * 30)for date, weather, temp in rows:print(f"{date:<12}{weather:<10}{temp:<10}")if __name__ == "__main__":print("=== 北京天气采集 ===")create_table()if weather_data := get_beijing_weather():save_weather(weather_data)show_weather()--------------------------------------------------

以上为爬取部分的代码,数据库里的内容如不做删除,输出会有些不合规,所以在运行代码时需要加入删除数据库内容的模块,以规范输出。
输出结果:

2)心得体会:
要注意数据库里的内容,由于代码会有多次运行,所以需在运行时对原有的存储数据进行删除。
作业②:
– 要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
– 网站:东方财富网:https://www.eastmoney.com/
– 技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
1)代码内容:
--------------------------------------------------
点击查看代码
import requests
import pandas as pd
import json
import sqlite3
from datetime import datetimedef get_stock_data():"""获取股票数据并格式化为表格"""url = "https://push2.eastmoney.com/api/qt/clist/get"params = {'cb': 'jQuery371048325911427590795_1761723060607','fid': 'f3', 'po': '1', 'pz': '20', 'pn': '1', 'np': '1','fltt': '2', 'invt': '2', 'ut': 'fa5fd1943c7b386f172d6893dbfba10b','fs': 'm:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23','fields': 'f12,f13,f14,f1,f2,f4,f3,f152,f5,f6,f7,f15,f18,f16,f17,f10,f8,f9,f23','_': '1761723060609'}try:response = requests.get(url, params=params, timeout=10)content = response.textjson_str = content[content.find('(') + 1:content.rfind(')')]data = json.loads(json_str)if data.get('rc') != 0 or not data.get('data'):return pd.DataFrame()stocks = []diff_data = data['data']['diff']items = diff_data.values() if isinstance(diff_data, dict) else diff_datafor item in items:stock = {'代码': item.get('f12', ''),'名称': item.get('f14', ''),'最新价': round(item.get('f2', 0), 2),'涨跌幅': f"{item.get('f3', 0):.2f}%",'涨跌额': round(item.get('f4', 0), 2),'成交量': item.get('f5', 0),'成交额': item.get('f6', 0),'振幅': f"{item.get('f7', 0):.2f}%",'最高': round(item.get('f15', 0), 2),'最低': round(item.get('f16', 0), 2),'今开': round(item.get('f17', 0), 2),'昨收': round(item.get('f18', 0), 2)}stocks.append(stock)return pd.DataFrame(stocks)except Exception as e:print(f"获取数据失败: {e}")return pd.DataFrame()def save_to_database(df, db_name="stock_data.db"):"""将数据保存到SQLite数据库"""if df.empty:return Falsetry:conn = sqlite3.connect(db_name)cursor = conn.cursor()# 修复:正确的CREATE TABLE语句cursor.execute('''CREATE TABLE IF NOT EXISTS stocks (id INTEGER PRIMARY KEY AUTOINCREMENT,代码 TEXT, 名称 TEXT, 最新价 REAL, 涨跌幅 TEXT, 涨跌额 REAL, 成交量 INTEGER, 成交额 REAL, 振幅 TEXT,最高 REAL, 最低 REAL, 今开 REAL, 昨收 REAL)''')# 修复:正确的INSERT语句(添加了表名stocks)for _, row in df.iterrows():cursor.execute('''INSERT INTO stocks (代码, 名称, 最新价, 涨跌幅, 涨跌额, 成交量, 成交额, 振幅, 最高, 最低, 今开, 昨收)VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)''', tuple(row))conn.commit()conn.close()return Trueexcept Exception as e:print(f"保存到数据库失败: {e}")return Falsedef display_table():"""显示股票数据表格并保存到数据库"""df = get_stock_data()if df.empty:print("未获取到数据")return# 显示数据df_display = df.copy()df_display.insert(0, '序号', range(1, len(df) + 1))# 格式化显示df_display['成交量'] = df_display['成交量'].apply(lambda x: f"{x / 10000:.2f}万手" if x > 10000 else f"{x}手")df_display['成交额'] = df_display['成交额'].apply(lambda x: f"{x / 100000000:.2f}亿元" if x > 100000000 else f"{x / 10000:.2f}万元")pd.set_option('display.max_columns', None)pd.set_option('display.width', None)print("\n股票数据列表:")print("=" * 110)print(df_display.to_string(index=False))print("=" * 110)print(f"总计: {len(df)} 只股票")# 保存到数据库if save_to_database(df):print("数据已成功保存到数据库")else:print("数据保存到数据库失败")if __name__ == "__main__":display_table()
--------------------------------------------------
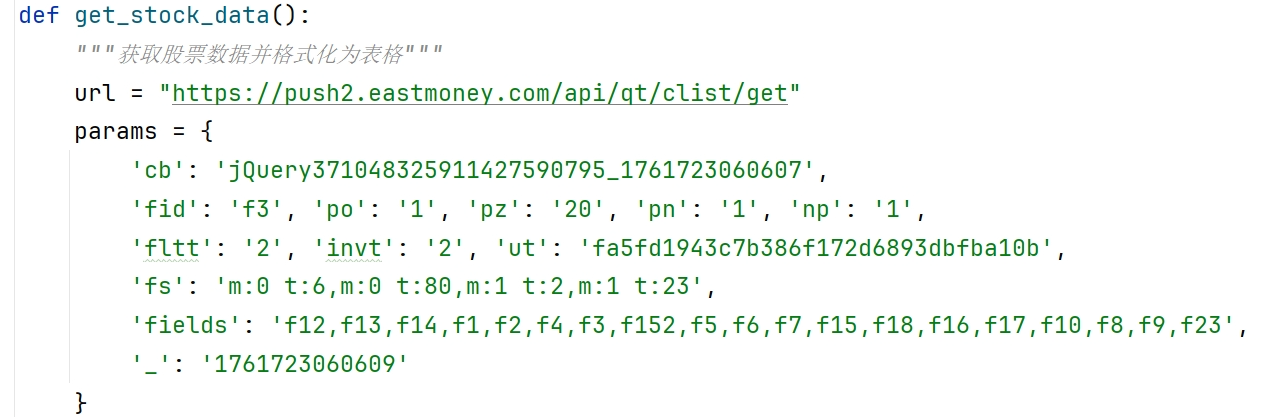
以上为经由ai转换得到的api,借此读取网页上的数据。
输出结果:
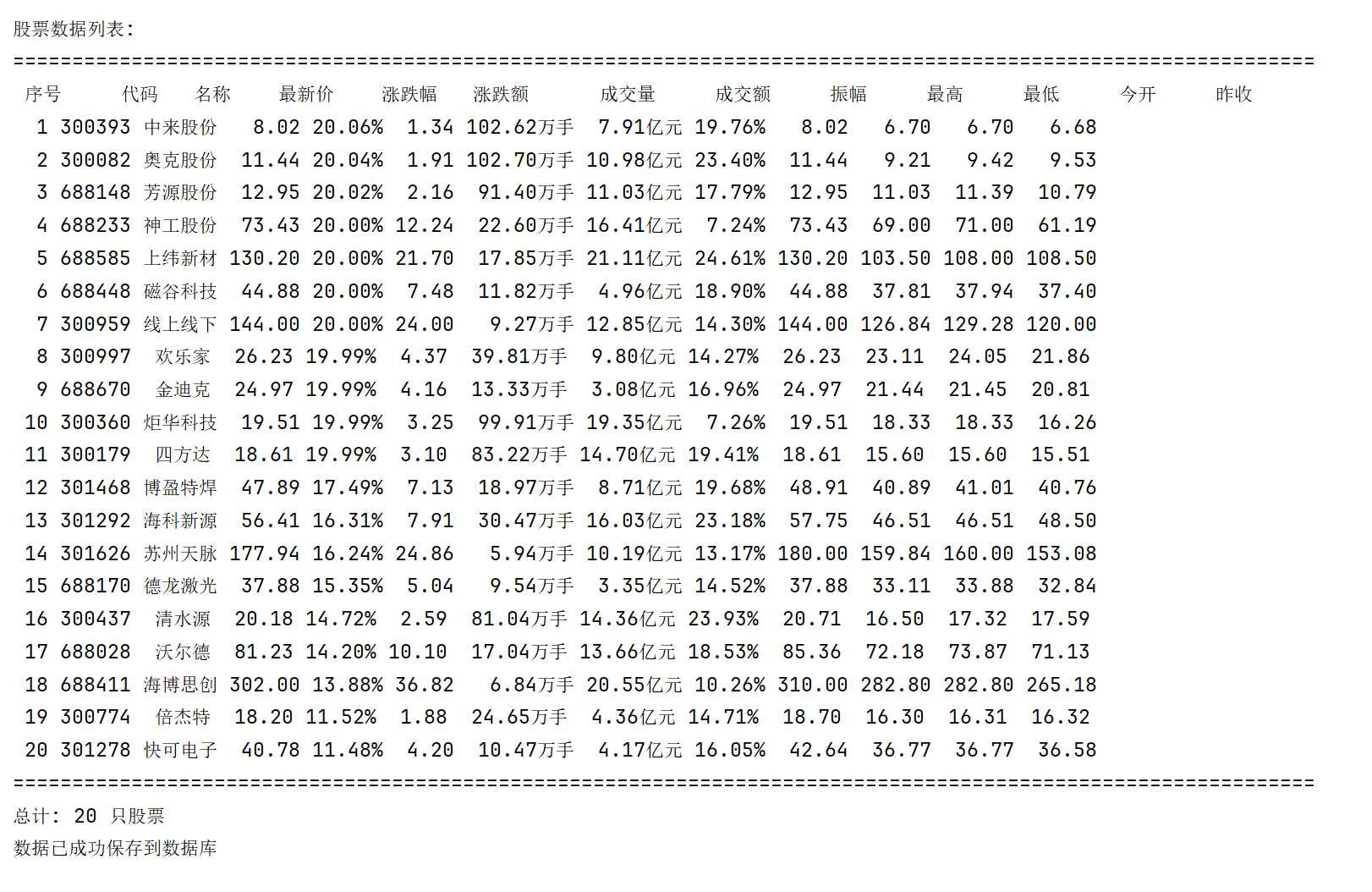
2)心得体会:
可以通过调取api的方式爬取网页中的数据
作业③:
– 要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021 )所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
– 技巧:分析该网站的发包情况,分析获取数据的api
1)代码内容:
--------------------------------------------------
点击查看代码
import requests
import sqlite3
import osclass FZUImageCrawler:def __init__(self, bcur_type=11, year=2021):self.api_url = f"https://www.shanghairanking.cn/api/pub/v1/bcur?bcur_type={bcur_type}&year={year}"self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36','Referer': 'https://www.shanghairanking.cn/',}self.db_file = f"universities_{year}.db"self.table_name = "rankings"def get_data_from_api(self):response = requests.get(self.api_url, headers=self.headers, timeout=10)response.raise_for_status()return response.json()def save_to_database(self, data):"""将数据存储到SQLite数据库"""if not data or 'data' not in data or 'rankings' not in data['data']:print("错误:数据格式不正确,无法存入数据库。")returnrankings = data['data']['rankings']# 如果数据库文件已存在,则删除if os.path.exists(self.db_file):os.remove(self.db_file)conn = Nonetry:conn = sqlite3.connect(self.db_file)cursor = conn.cursor()print(f"成功连接到数据库 {self.db_file}。")# 创建表cursor.execute(f'''CREATE TABLE {self.table_name} (ranking INTEGER,school_name TEXT,province TEXT,type TEXT,score REAL)''')print(f"成功创建表:{self.table_name}。")# 准备插入数据data_to_insert = []for school in rankings:data_to_insert.append((school['rankOverall'],school['univNameCn'],school['province'],school['univCategory'],school['score']))# 批量插入数据cursor.executemany(f'INSERT INTO {self.table_name} (ranking, school_name, province, type, score) VALUES (?, ?, ?, ?, ?)',data_to_insert)conn.commit()print(f"成功将 {len(data_to_insert)} 条数据存入数据库。")except sqlite3.Error as e:print(f"数据库操作失败:{e}")finally:if conn:conn.close()def print_from_database(self):"""从数据库中读取数据并打印到控制台"""if not os.path.exists(self.db_file):print(f"错误:数据库文件 {self.db_file} 不存在。")returnconn = Nonetry:conn = sqlite3.connect(self.db_file)cursor = conn.cursor()cursor.execute(f'SELECT * FROM {self.table_name} ORDER BY ranking')rows = cursor.fetchall()print(f"\n--- {self.api_url.split('year=')[1]}年中国大学主榜排名 (从数据库读取) ---")print(f"{'排名':<5}\t{'学校':<15}\t{'省市':<5}\t{'类型':<5}\t{'总分':<5}")print("-" * 50)for row in rows:# 处理分数为None的情况,显示为空字符串score_display = row[4] if row[4] is not None else ''print(f"{row[0]:<5}\t{row[1]:<15}\t{row[2]:<5}\t{row[3]:<5}\t{score_display:<5}")except sqlite3.Error as e:print(f"读取数据库时出错:{e}")finally:if conn:conn.close()def crawl_and_download(self):"""主方法:获取数据、保存到数据库、从数据库打印"""data = self.get_data_from_api()if data:self.save_to_database(data)self.print_from_database()if __name__ == "__main__":crawler = FZUImageCrawler()crawler.crawl_and_download()
--------------------------------------------------
在抓取js文件时,可以直接寻找payload.js文件,也可以通过关键信息直接在界面右侧进行查找获取
在api转换时,通过转换后的bcur_type进行查找,发现转换的方法在3b2735a.js文件下,“bcur_type=11, year=2021”分别代表着11种排名类型与2021年年份。
输出结果:
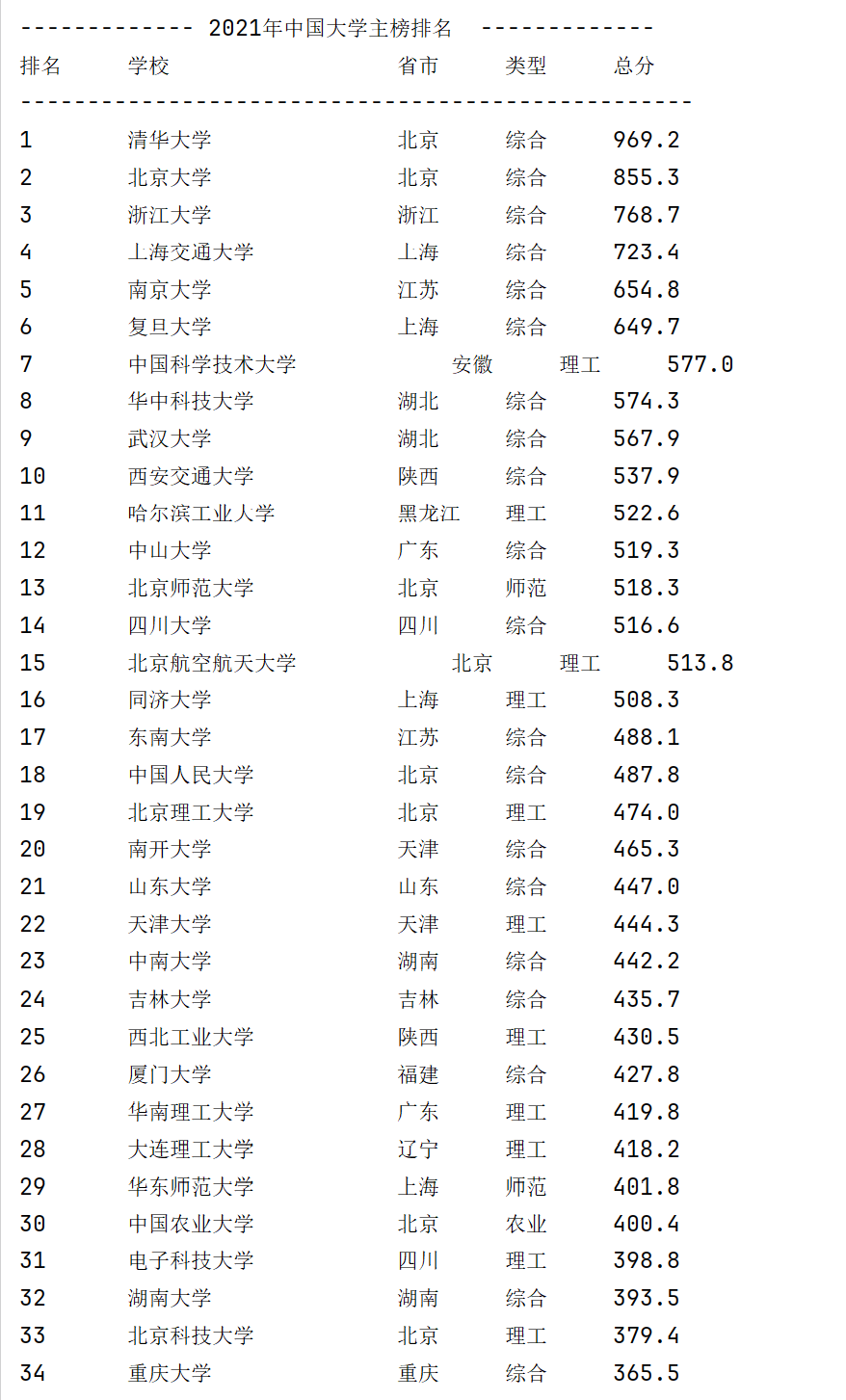
2)心得体会:
静态页面无法进行完整爬取,可借由js文件爬取内容