
1. 安装前准备
系统要求
- 操作系统: Windows 10/11, macOS 或 Linux
- 硬件要求:
- CPU: 至少4核处理器
- 内存: 8GB 或更高(推荐16GB)
- 存储: 至少有5GB可用空间
- GPU: 可选(NVIDIA显卡推荐使用CUDA驱动)
网络要求
- 稳定的互联网连接(下载模型文件需要)
- 可能需要配置代理(如有需要)
2. Ollama 安装步骤
-
下载Ollama:
- 访问 Ollama官网下载页面
- 选择适合您操作系统的版本下载
-
安装Ollama:
- Windows: 双击下载的安装程序,按照向导完成安装
- macOS: 拖动Ollama到Applications文件夹
- Linux: 使用包管理器或运行下载的安装脚本

-
验证安装:
ollama --version如果安装成功,将显示Ollama的版本信息


3. 下载和运行Qwen3:0.6B模型
命令行方式
ollama pull qwen3:0.6b
ollama run qwen3:0.6b

GUI方式
- 打开Ollama应用
- 在模型库中选择"qwen3:0.6b"
- 点击"Download"按钮
- 下载完成后点击"Run"运行模型
模型存储位置
- Windows:
C:\Users\<用户名>\.ollama\models - macOS/Linux:
~/.ollama/models


4. 使用模型
命令行交互
ollama run qwen3:0.6b
键入问题后按Enter发送,输入/bye或按Ctrl+C退出


安装qwen3模型后,ollama界面里面也可以进行对话

Web接口
- 运行模型后,会启用http接口,可以使用浏览器访问 http://localhost:11434,如果已经运行,会提示
Ollama is running。
5. 整合到Cherry Studio
-
在Cherry Studio中添加本地模型:
- 选择"Local Models" > "Add Model"
- 配置端口为11434(Ollama默认端口)
- 选择模型为qwen3:0.6b



-
如果Ollama运行在其他机器上:
- 确保防火墙允许11434端口的连接
- 在Cherry Studio中使用
http://<IP地址>:11434
6. 性能监控和优化
资源占用检查
- Windows: 任务管理器 > 性能标签
- macOS/Linux: 使用
top或htop
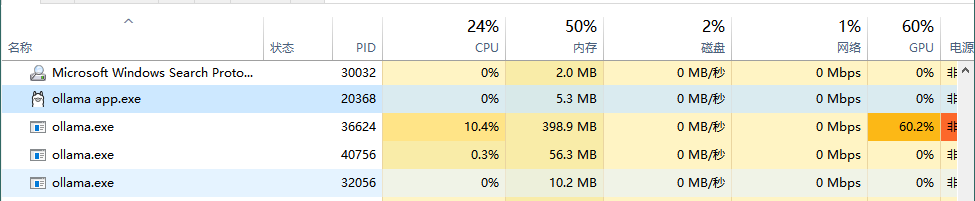
进行对话的时候,CPU和GPU的占用,GPU是GTX-1066-6G,可以看到占用也不是很高。
优化建议
-
GPU加速:
- 确保安装正确的GPU驱动
- 对于NVIDIA显卡,安装CUDA工具包
- 检查Ollama是否识别到GPU:
查看是否有CUDA设备信息ollama list
-
批量处理:
- 使用
--num-ctx参数调整上下文长度(默认2048)
ollama run qwen3:0.6b --num-ctx 4096 - 使用
7. 常见问题排查
-
下载失败
- 检查网络连接
- 尝试使用代理:
ollama pull qwen3:0.6b --proxy http://<代理地址>:<端口> - 检查存储空间是否足够
-
模型运行缓慢
- 升级硬件配置(特别是GPU)
- 减少上下文长度
- 关闭其他占用资源的程序
-
模型无法加载
- 检查模型是否完整下载:
ollama list - 重新下载模型:
ollama rm qwen3:0.6b ollama pull qwen3:0.6b
- 检查模型是否完整下载:
8. 进阶使用
自定义模型配置
- 创建Modelfile:
FROM qwen3:0.6b PARAMETER temperature 0.7 PARAMETER top_p 0.9 - 构建自定义模型:
ollama create my-qwen -f Modelfile - 运行自定义模型:
ollama run my-qwen
API访问
Ollama提供REST API,可用于编程访问:
curl http://localhost:11434/api/generate -d '{"model": "qwen3:0.6b","prompt": "你好,你是谁?","stream": false
}'
9. 备份与迁移
-
备份模型:
ollama pull qwen3:0.6b模型会自动存储在默认目录
-
迁移到其他机器:
- 复制
~/.ollama/models目录到新机器 - 在新机器上安装Ollama
- 运行:
ollama run qwen3:0.6b
- 复制