
人工智能之数据分析 Pandas
第二章 Series
@
目录
- 人工智能之数据分析 Pandas
- 前言
- 一、什么是 Series?
- 二、Series 的核心特点
- 三、创建 Series 的 4 种主要方式
- 1. 从列表或 NumPy 数组创建
- 2. 从字典创建(最常用之一)
- 3. 用标量(单个值)创建
- 4. 创建空 Series
- 四、Series 的常用属性与方法
- 五、数据访问与操作
- 1. 访问元素
- 2. 切片
- 3. 修改与增删
- 4. 向量化运算与过滤
- 六、重要注意事项
- 七、总结
- 后续
- 资料关注
前言
Pandas 的 Series 是其最基础、最核心的一维数据结构,是学习 Pandas 的起点。本文从定义、特点、创建方式、常用操作、注意事项等方面进行系统而详细的介绍。
一、什么是 Series?
Series 是一个带标签索引的一维数组,由两部分组成:
- values(值):实际存储的数据,底层为 NumPy 数组(
ndarray),支持整数、浮点、字符串、布尔值等任意类型,也可包含缺失值NaN。 - index(索引):与每个值一一对应的标签,默认为从 0 开始的整数,但可自定义为字符串、日期等可哈希类型。
✅ 简单理解:Series = 字典 + 数组
- 像字典一样可通过“键”(索引)快速访问值;
- 像数组一样支持向量化运算和高效数值计算。
二、Series 的核心特点
| 特性 | 说明 |
|---|---|
| 一维结构 | 只有一列数据 |
| 自动对齐 | 运算时按索引对齐,不匹配的位置返回 NaN |
| 支持缺失值 | 使用 NaN 表示缺失数据 |
| 可命名 | 可通过 name 参数设置名称(常用于转为 DataFrame 的列名) |
| 索引可重复 | 允许重复索引(但会影响唯一访问) |
| 不可变大小(默认) | 创建后长度固定,但可通过 append、drop 等生成新对象 |
三、创建 Series 的 4 种主要方式
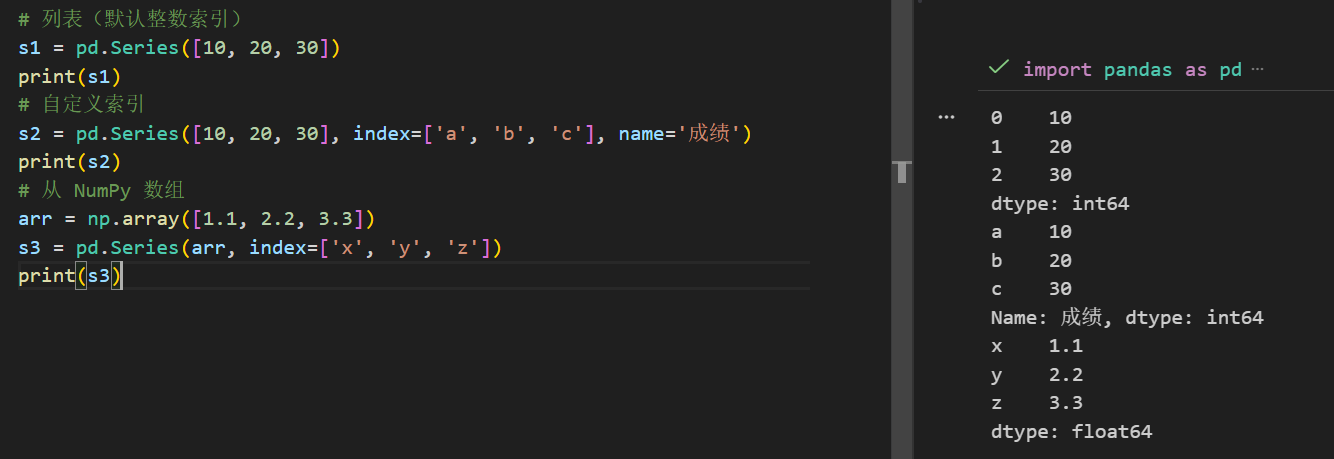
1. 从列表或 NumPy 数组创建
import pandas as pd
import numpy as np# 列表(默认整数索引)
s1 = pd.Series([10, 20, 30])
# 自定义索引
s2 = pd.Series([10, 20, 30], index=['a', 'b', 'c'], name='成绩')
# 从 NumPy 数组
arr = np.array([1.1, 2.2, 3.3])
s3 = pd.Series(arr, index=['x', 'y', 'z'])
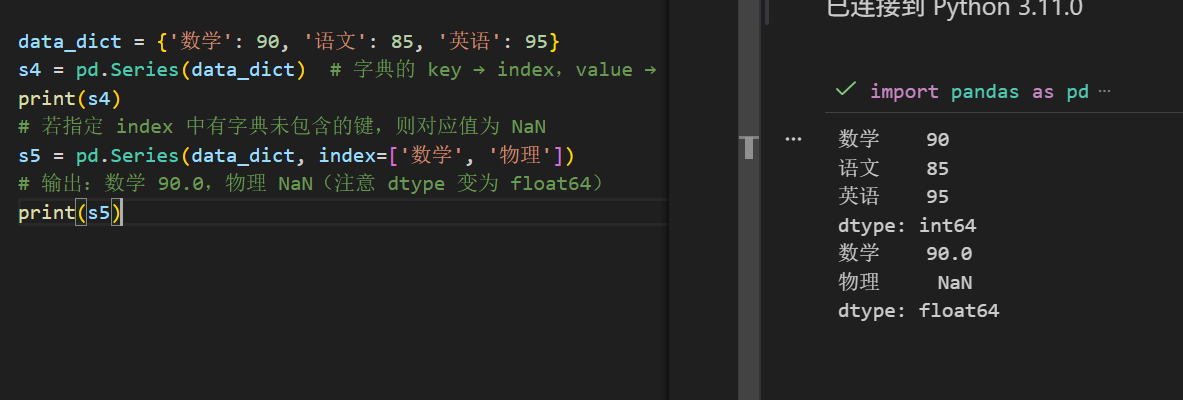
2. 从字典创建(最常用之一)
data_dict = {'数学': 90, '语文': 85, '英语': 95}
s4 = pd.Series(data_dict) # 字典的 key → index,value → data# 若指定 index 中有字典未包含的键,则对应值为 NaN
s5 = pd.Series(data_dict, index=['数学', '物理'])
# 输出:数学 90.0,物理 NaN(注意 dtype 变为 float64)
3. 用标量(单个值)创建
s6 = pd.Series(5, index=['A', 'B', 'C'])
# 所有位置都填充为 5
# A 5
# B 5
# C 5

4. 创建空 Series
empty_s = pd.Series(dtype='float64') # 必须指定 dtype
四、Series 的常用属性与方法
| 属性/方法 | 说明 | 示例 |
|---|---|---|
.index |
获取索引 | s.index |
.values |
获取数据(NumPy 数组) | s.values |
.name |
获取或设置名称 | s.name = '分数' |
.dtype |
数据类型 | s.dtype |
.shape |
形状(如 (3,)) |
s.shape |
.size |
元素总数 | s.size |
.isnull() / .notnull() |
判断是否为 NaN | s.isnull() |
.unique() |
返回唯一值 | s.unique() |
.value_counts() |
统计各值出现次数 | s.value_counts() |
.describe() |
描述性统计(均值、标准差等) | s.describe() |
.sort_values() |
按值排序 | s.sort_values() |
.sort_index() |
按索引排序 | s.sort_index() |
.astype('float64') |
类型转换 | s.astype('str') |
.to_list() |
转为 Python 列表 | s.to_list() |
.to_frame() |
转为 DataFrame | s.to_frame() |
五、数据访问与操作
1. 访问元素
s = pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])s['a'] # 标签索引 → 1
s[0] # 位置索引 → 1(不推荐,易混淆)
s.loc['a'] # 显式索引(推荐)
s.iloc[0] # 隐式位置索引(推荐用于位置访问)
2. 切片
s['a':'c'] # 显式切片 → 包含 'c'(前闭后闭)
s.iloc[0:2] # 隐式切片 → 不包含索引 2(前闭后开)
3. 修改与增删
s['b'] = 20 # 修改
s['e'] = 5 # 新增(自动扩展)
del s['a'] # 删除(原地修改)
s_new = s.drop('c') # 返回新 Series,不修改原对象
4. 向量化运算与过滤
s * 2 # 所有元素 ×2
s[s > 3] # 布尔索引:筛选值大于 3 的元素
np.sqrt(s) # 应用 NumPy 函数
六、重要注意事项
-
索引对齐机制
两个 Series 运算时,Pandas 会自动按索引对齐,非公共索引位置结果为NaN:s1 = pd.Series([1, 2], index=['a', 'b']) s2 = pd.Series([3, 4], index=['b', 'c']) print(s1 + s2) # a NaN # b 6.0 # c NaN -
NaN 的处理
NaN != NaN,不能用==判断,应使用isnull()或pd.isna()- 含
NaN的 Series,dtype通常为float64
-
索引可重复,但慎用
重复索引会导致s['key']返回多个值(Series 而非标量) -
性能提示
- 尽量避免频繁修改 Series(如循环中赋值),建议一次性构建
- 使用
.loc/.iloc提高代码可读性和安全性
七、总结
Series 是 Pandas 的基石:
- 它融合了数组的高效计算与字典的灵活索引;
- 是构建 DataFrame 的基本单元(DataFrame 的每一列就是一个 Series);
- 掌握 Series,就掌握了 Pandas 数据操作的核心逻辑。
后续
python过渡项目部分代码已经上传至gitee,后续会逐步更新。
资料关注
公众号:咚咚王
gitee:https://gitee.com/wy18585051844/ai_learning

《Python编程:从入门到实践》
《利用Python进行数据分析》
《算法导论中文第三版》
《概率论与数理统计(第四版) (盛骤) 》
《程序员的数学》
《线性代数应该这样学第3版》
《微积分和数学分析引论》
《(西瓜书)周志华-机器学习》
《TensorFlow机器学习实战指南》
《Sklearn与TensorFlow机器学习实用指南》
《模式识别(第四版)》
《深度学习 deep learning》伊恩·古德费洛著 花书
《Python深度学习第二版(中文版)【纯文本】 (登封大数据 (Francois Choliet)) (Z-Library)》
《深入浅出神经网络与深度学习+(迈克尔·尼尔森(Michael+Nielsen)》
《自然语言处理综论 第2版》
《Natural-Language-Processing-with-PyTorch》
《计算机视觉-算法与应用(中文版)》
《Learning OpenCV 4》
《AIGC:智能创作时代》杜雨+&+张孜铭
《AIGC原理与实践:零基础学大语言模型、扩散模型和多模态模型》
《从零构建大语言模型(中文版)》
《实战AI大模型》
《AI 3.0》