第一次项目作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 实现一个3000字以上论文查重程序 |
github连接:
https://github.com/sugarcaneprince/sugarcaneprince
psp表格如下
| Process Stages | Process Stages (中文) | (分钟) | (分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 15 | 10 |
| Development | 开发 | 215 | 310 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 50 |
| · Design Spec | · 生成设计文档 | 20 | 15 |
| · Design Review | · 设计复审 | 20 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| · Design | · 具体设计 | 30 | 45 |
| · Coding | · 具体编码 | 45 | 80 |
| · Code Review | · 代码复审 | 30 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 40 |
| Reporting | 报告 | 80 | 100 |
| · Test Report | · 测试报告 | 40 | 60 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| · 合计 | 310 | 420 |
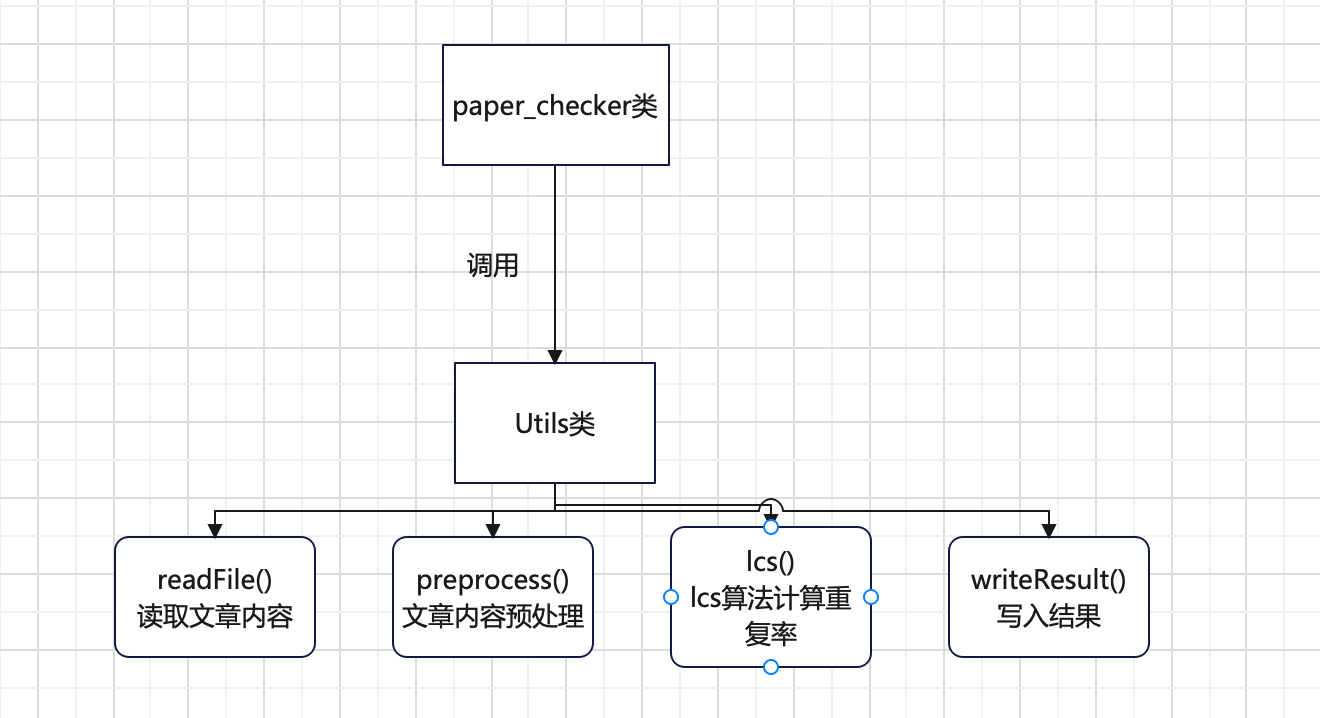
接口的设计和实现过程
-
程序主要分为两个简单的类,一个是用于实现计算模块的辅助工具类,另一个是程序的入口类
-
画出简单的流程图以便于理解
-
![image]()
-
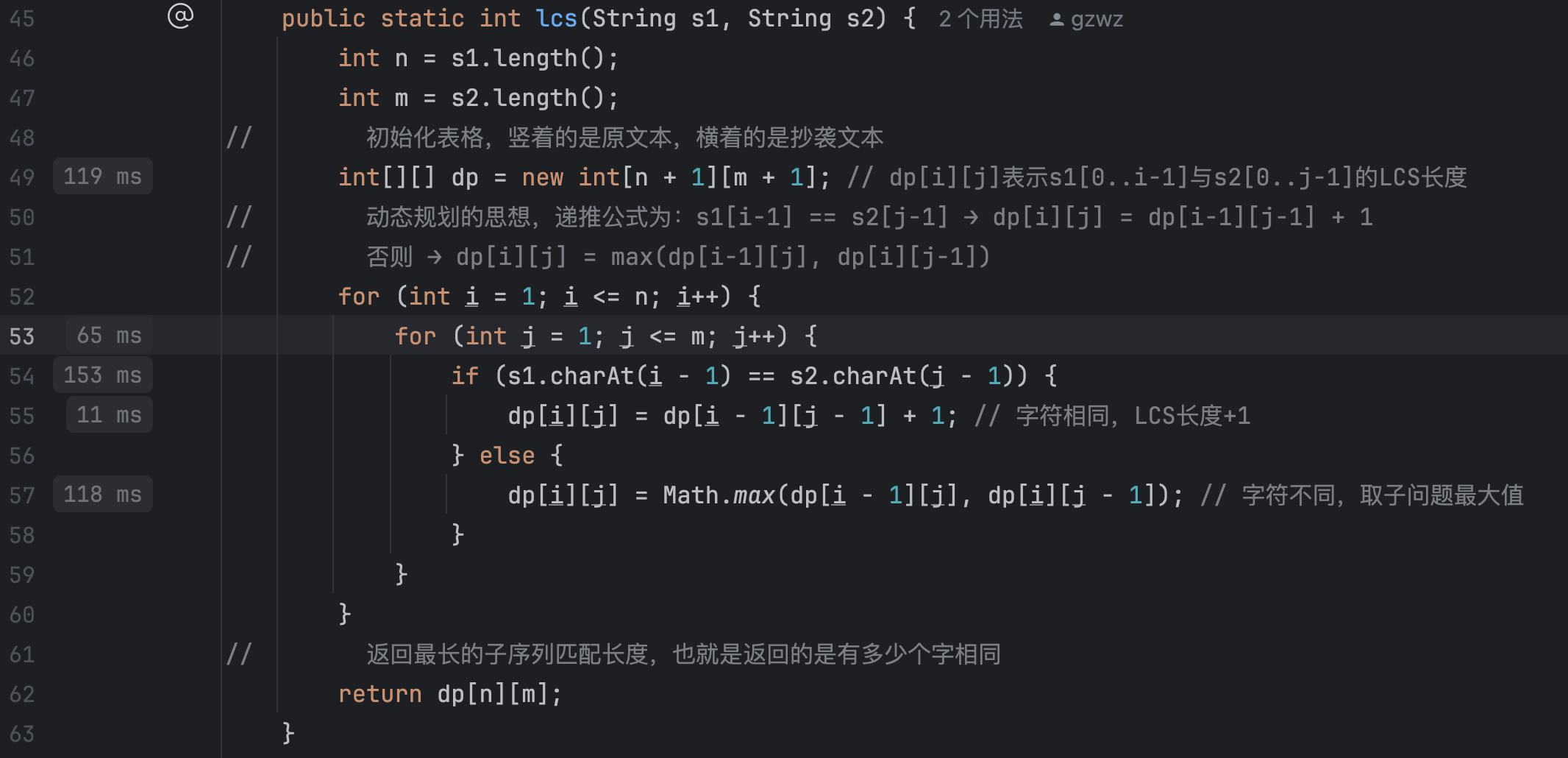
lcs()是实现文章查重的关键算法,算法主要利用动态规划
-
动态规划的思想,递推公式为:
-
s1[i-1] == s2[j-1] → dp[i][j] = dp[i-1][j-1] + 1
-
否则 → dp[i][j] = max(dp[i-1][j], dp[i][j-1])
-
算法高效且避免了恶意重复相同字段而降低重复率的问题,能够高效的得出文章的查重率
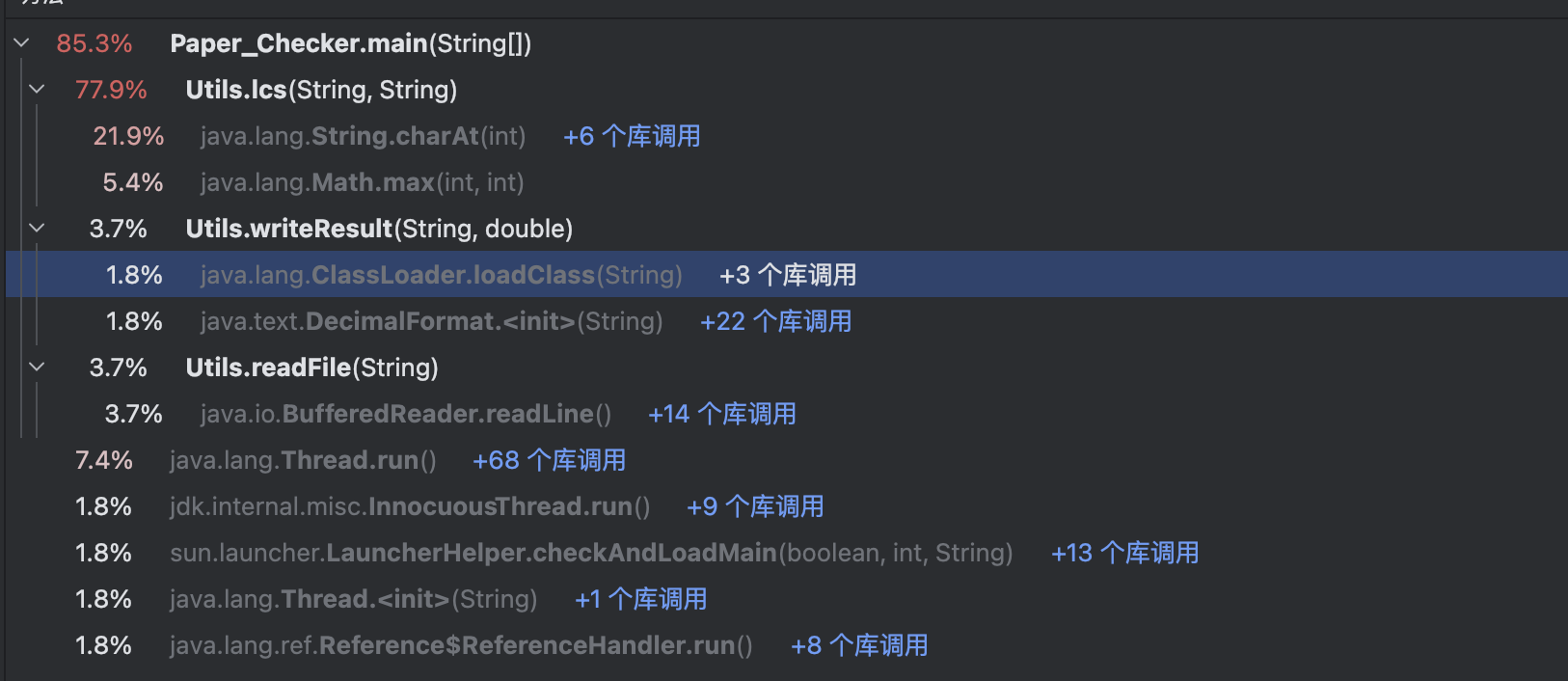
计算接口部分的性能改进
-
展示性能分析图
-
![image]()
- 不难看出,lcs()算法的执行就是性能消耗最大的
-
展示lcs()算法的部分耗时
-
![image]()
计算模块单元测试展示
由于算法的关键在于lcs()算法,首先对lcs()算法的部分结果进行测试,测试代码如下
@Testpublic void test() {
// 修改System.out.println(Utils.lcs("今天是周日我很开心","今天是周三你很伤心"));
// 增加System.out.println(Utils.lcs("今天是周日我很开心","今天是周日我很开心,明天是周一我很难过"));
// 减少System.out.println(Utils.lcs("今天是周日我很开心","今天是周日"));
// 胡乱打System.out.println(Utils.lcs("今天是周日我很开心","我是计算机科学与技术专业的学生"));}
测试结果如下

- 第一个测试结果,只有“今天是周__很___心”符合结果,6个字符匹配成功
- 第二个测试结果,完全是添加,所以9个字符匹配成功
- 以下结果以此类推,不再赘述
接下来引入测试的文件
测试文件来源于老师发送的测试文档,直接抛出结果
首先测试的是add的文本,测试结果与覆盖率如下,不出意外应该为100%的查重率

事实也确实如此,由于下面所有的代码覆盖率都基本一致,后序就不再截图

接着测试del过的文本,结果如下

dis_1的文本,文本只经过部分简单的修改

dis_2的文本,顺序经过打乱

依然有较高的查重率,所以能表现出lcs()算法的健壮
dis_3的文本,顺序经过较强的打乱

依旧能有67%以上的查重率
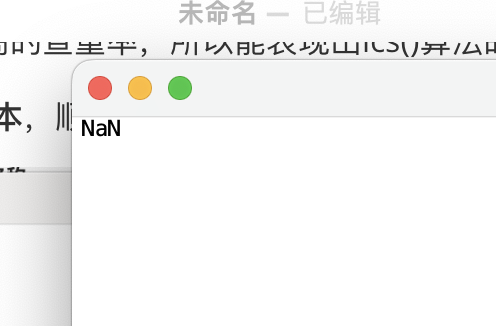
有可能出现的异常
// 计算重复率(避免除零错误)
int origLen = origText.length();
double rate = origLen == 0 ? 0 : (double) lcsLength / origLen;
在判断的时候有可能出现除零异常
但是我提前做了错误处理,如果原来的文本为空白文本,那读取出来的字符个数为0,不将0值替换的话,结果将会出现除零异常,res传出的值为null
按照原来的思路的话就不会出现问题
