
先看结论:
| 显存 | 典型的笔记本显卡型号 | 可运行模型 | 上下文长度限制 |
|---|---|---|---|
| 8G | 5070 | 7B/8B 模型的 Q4_K_M 量化版 | 增加上下文长度会迅速消耗剩余显存。 |
| 12G | 5070Ti | 7B/8B 模型任何版本。 13B/14B 模型的 Q4_K_M 量化版 | |
| 16G | 5080 | 12B-14B 模型 Q8 (8-bit) | 上下文(如 8K, 16K, 32K Token)的首选。 |
| 24G | 5090 | 30B - 34B 级模型Q4/Q5 量化版 |
说明:
- “7B/8B” 中的 “B” 是 “Billion”(十亿),代表模型的参数数量,是衡量模型规模的核心指标。
- 本文讨论的“可运行”主要指推理(Inference),即加载模型并生成文本,而非训练(Training)或微调(Fine-tuning),后两者对显存的需求是推理的数倍。
推理时显存大小计算公式
简化推理公式:
显存需求 = (模型总参数量 * 量化密度) + 上下文缓存 + 系统开销
系统开销
这一项是固定开销,用于确保程序正常运行,和模型大小关系不大。
这一项难以精确计算,通常是 1 GB 到 3 GB 左右。
主要存储下面这些内容:
- 激活值 (Activations): 模型在计算过程中产生的中间结果,需要临时存储。
- 显存 Buffer: GPU 驱动程序和操作系统所需的最小显存占用。
- 计算 Buffer: 用于张量 (Tensor) 操作和数据传输所需的临时空间。
如果你使用批处理(Batch Size > 1)进行训练或微调,这一项会显著增加。
量化密度
一个模型就是由 N 亿个参数组成的。
每个参数是一个数字,这个数字占用的空间取决于其精度(量化密度)。
| 精度类型 | 量化密度 | 每参数占用字节数 | 示例:7B 模型所需显存 |
|---|---|---|---|
| LLM原始精度 BF16 | 2 | 2 Bytes | 7 * 2 = 14GB |
| Q8 | 1 | 1 Bytes | 7 * 1 = 7GB |
| Q4 (GGUF) | 1 | 0.5 Bytes | 7 * 0.5 ≈ 3.5GB |
上下文缓存
上下文缓存会随着你输入的文本长度和输出的文本长度而变化.
简单计算公式
上下文缓存 ≈ 2 * 模型的层数 * 上下文长度 * 批处理大小 * 隐藏层维度 * 缓存精度
- 2: 在
Transformer架构中,注意力机制需要Key(K)和Value(V)两组向量来代表上下文,所以我们需要存储2份。 - 模型的层数:
LLM是多层堆叠的,每层都需要维护自己独立的K和V缓存。因此总消耗必须乘以模型的总层数,这个层数也是模型深度。 - 批处理大小: 本地推理通常为
1 - 上下文长度 (Context Length)
- 隐藏层维度:也就是模型宽度
下面这张表展示了 KV 缓存(即上下文长度)对显存需求的爆炸性影响:
| 模型 | 上下文长度 L=4096 tokens | 上下文长度 L=8192 tokens | 上下文长度 L=32768 tokens |
|---|---|---|---|
| Llama 3 8B | ≈2.0 GB | ≈4.0 GB | ≈16.0 GB |
| Mixtral 8x7B | ≈2.0 GB | ≈4.0 GB | ≈16.0 GB |
| Qwen 2 72B | ≈10.0 GB | ≈20.0 GB | ≈80.0 GB |
上下文越长,占用的显存就越多。
这也是为什么 8GB 显存跑 7B Q4 模型没问题,但一旦上下文长度设置到 32k 或 64k,显存会立即爆满。
计算示例
示例计算:运行 Llama 3 8B 的 Q4_K_M 量化版,上下文设为 4096 tokens。
-
模型参数显存:8B 参数 * 0.5 Bytes/参数 ≈ 4 GB。
-
KV缓存显存:约 2 GB。
-
系统开销:预估 1.5 GB。
-
总计显存需求:4 + 2 + 1.5 = 7.5 GB。
因此,8GB 显存刚好在临界点,增加上下文或使用更高精度量化会爆显存。
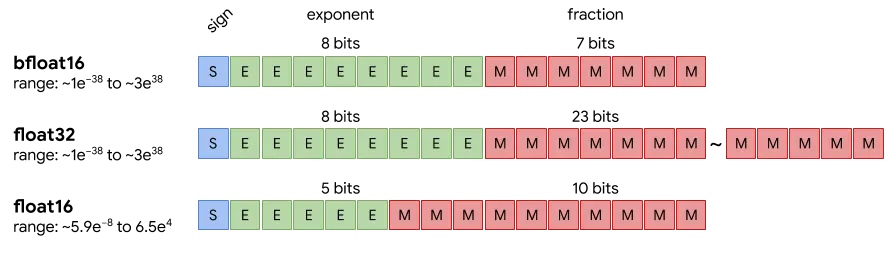
模型的原始精度
BF16现在是大型语言模型(LLM)训练的绝对主流精度。
原因:AI训练中,数值范围比精度更重要。
因为梯度、参数可能很大或很小,但不需要小数点后很多位的精确值。所以BF16保留了和FP32一样的8位指数,确保范围足够,但减少尾数到7位,牺牲精度换内存和速度。
简单来说,你可以这样理解:
BF16 设计了一个和 FP32 一样宽的“桶”(指数位),但允许“桶”壁更粗糙一些(尾数位少)。
这样既能装下训练中的所有“水”(数值),又让“桶”本身更轻便(16位)。
这正是AI训练最需要的特性。
量化与精度对照
| 类型 | 等级/格式 | 存储比特数 | 核心特点与说明 |
|---|---|---|---|
| LLM原始精度 | BF16 | 16 | |
| 量化格式 | Q8_0 | 8 | 基于块的8位整数,接近无损,可视为“高保真压缩”。 |
| 量化格式 | Q6_K | 6 | 高性价比平衡点。 |
| 量化格式 | Q5_K_M | 5 | 最流行选择之一,精度与体积平衡好。 |
| 量化格式 | Q4_K_M | 4 | 另一最流行选择,比Q5更小。 |
| 量化格式 | Q3_K_M | 3 | 低资源场景,精度损失明显。 |
| 量化格式 | Q2_K | 2 | 极限压缩,研究或特定场景用。 |
- 表格中的 Q8/Q6/Q5/Q4 等(特指GGUF格式)是整数量化,但采用了块状混合精度技术。这意味着模型内不同部分的权重可能用4、5、6、8比特等不同精度存储,以达到最佳性价比,不是简单的“全部权重统一降到N比特”。
- 选择建议:
- 追求极致效果:用 BF16/FP16。
- 最佳平衡点:从 Q4_K_M 或 Q5_K_M 开始尝试。
- 接近无损:选 Q6_K 或 Q8_0。
- 资源极度有限:考虑 Q3_K_M 或 Q2_K。
总结
在有限显存下,需要在“模型规模”、“量化精度”和“上下文长度”这三个核心要素之间进行动态权衡。
没有唯一的最优解,只有最适合当前任务和硬件的平衡点。